Google 发表 GFS、MapReduce、BigTable 三篇论文,号称“三驾马车”,开启了大数据的时代。那和这“三驾马车”对应的有哪些开源产品呢?
- GFS 对应的 Hadoop 分布式文件系统 HDFS,
- MapReduce 对应的 Hadoop 分布式计算框架 MapReduce,
- BigTable 对应的 NoSQL 系统 HBase
what is NoSQL
NoSQL,主要指非关系的、分布式的、支持海量数据存储的数据库设计模式。也有许多专家将 NoSQL 解读为 Not Only SQL,表示 NoSQL 只是关系数据库的补充,而不是替代方案。其中,HBase 是这一类 NoSQL 系统的杰出代表。
why is Hbase
HBase 之所以能够具有海量数据处理能力,其根本在于和传统关系型数据库设计的不同思路。传统关系型数据库对存储在其上的数据有很多约束,学习关系数据库都要学习数据库设计范式,事实上,是在数据存储中包含了一部分业务逻辑。而 NoSQL 数据库则简单暴力地认为,数据库就是存储数据的,业务逻辑应该由应用程序去处理,有时候不得不说,简单暴力也是一种美。
HBase 可伸缩架构
HBase 为可伸缩海量数据储存而设计,实现面向在线业务的实时数据访问延迟。
HBase 的伸缩性主要依赖
- 其可分裂的 HRegion
- 可伸缩的分布式文件系统 HDFS

HRegion 是 HBase 负责数据存储的主要进程,应用程序对数据的读写操作都是通过和 HRegion 通信完成。
上面是 HBase 架构图,我们可以看到在 HBase 中,数据以 HRegion 为单位进行管理,也就是说应用程序如果想要访问一个数据,必须先找到 HRegion,然后将数据读写操作提交给 HRegion,由 HRegion 完成存储层面的数据操作。
HRegionServer 是物理服务器,每个 HRegionServer 上可以启动多个 HRegion 实例。当一个 HRegion 中写入的数据太多,达到配置的阈值时,一个 HRegion 会分裂成两个 HRegion,并将 HRegion 在整个集群中进行迁移,以使 HRegionServer 的负载均衡。
每个 HRegion 中存储一段 Key 值区间 [key1, key2) 的数据,所有 HRegion 的信息,包括存储的 Key 值区间、所在 HRegionServer 地址、访问端口号等,都记录在 HMaster 服务器上。为了保证 HMaster 的高可用,HBase 会启动多个 HMaster,并通过 ZooKeeper 选举出一个主服务器。
下面是一张调用时序图,应用程序通过 ZooKeeper 获得主 HMaster 的地址,输入 Key 值获得这个 Key 所在的 HRegionServer 地址,然后请求 HRegionServer 上的 HRegion,获得所需要的数据。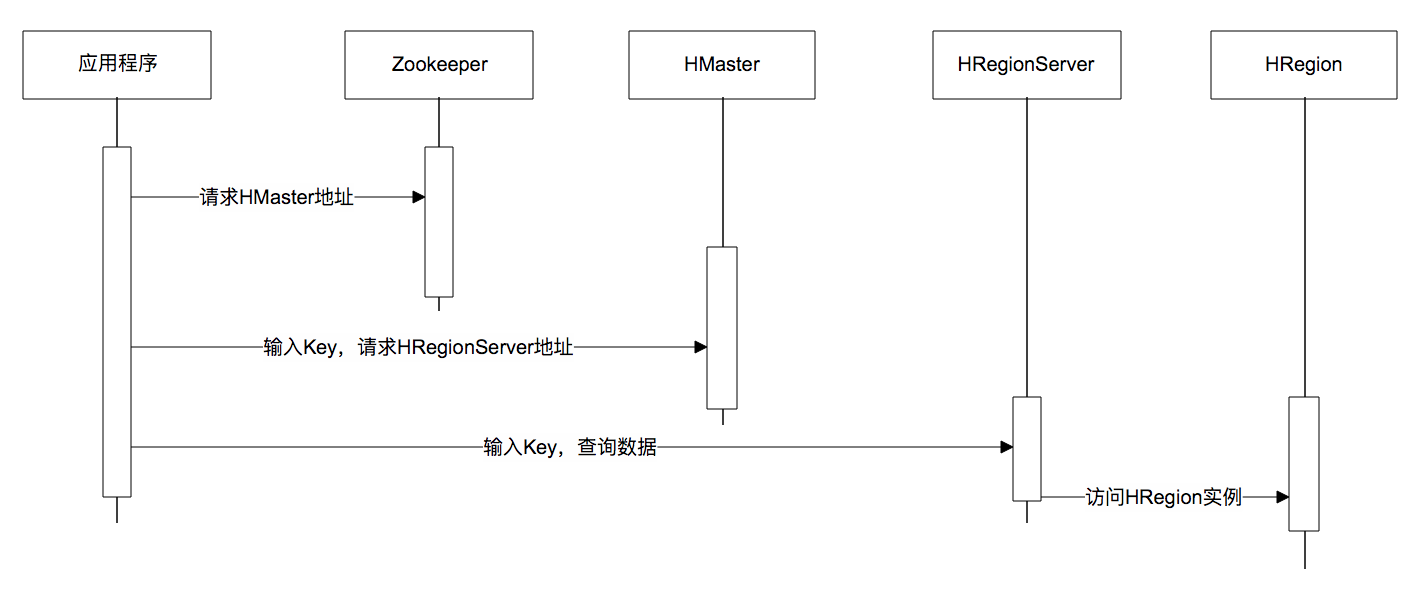
数据写入过程也是一样,需要先得到 HRegion 才能继续操作。HRegion 会把数据存储在若干个 HFile 格式的文件中,这些文件使用 HDFS 分布式文件系统存储,在整个集群内分布并高可用。当一个 HRegion 中数据量太多时,这个 HRegion 连同 HFile 会分裂成两个 HRegion,并根据集群中服务器负载进行迁移。如果集群中有新加入的服务器,也就是说有了新的 HRegionServer,由于其负载较低,也会把 HRegion 迁移过去并记录到 HMaster,从而实现 HBase 的线性伸缩。
总结
先小结一下上面的内容,HBase 的核心设计目标是解决海量数据的分布式存储,和 Memcached 这类分布式缓存的路由算法不同,HBase 的做法是按 Key 的区域进行分片,这个分片也就是 HRegion。应用程序通过 HMaster 查找分片,得到 HRegion 所在的服务器 HRegionServer,然后和该服务器通信,就得到了需要访问的数据。

若有收获,就点个赞吧
0 人点赞
