
官方网站:https://pandas.pydata.org/docs/ 中文网站:http://www.pypandas.cn/
隔行插入空行
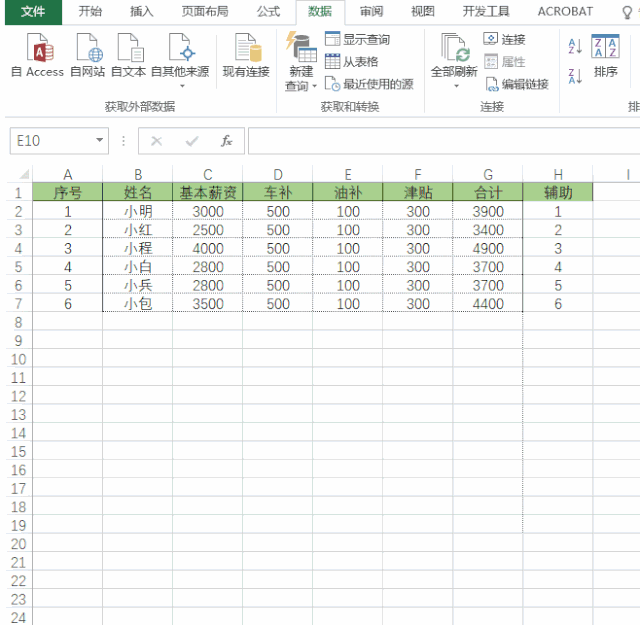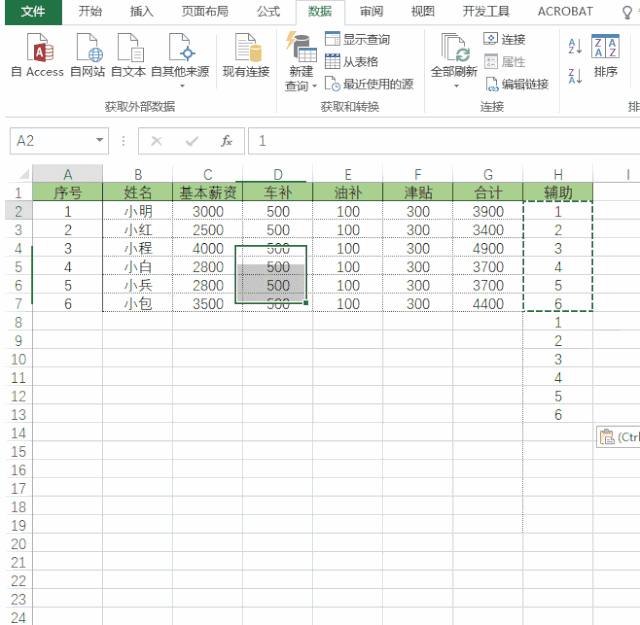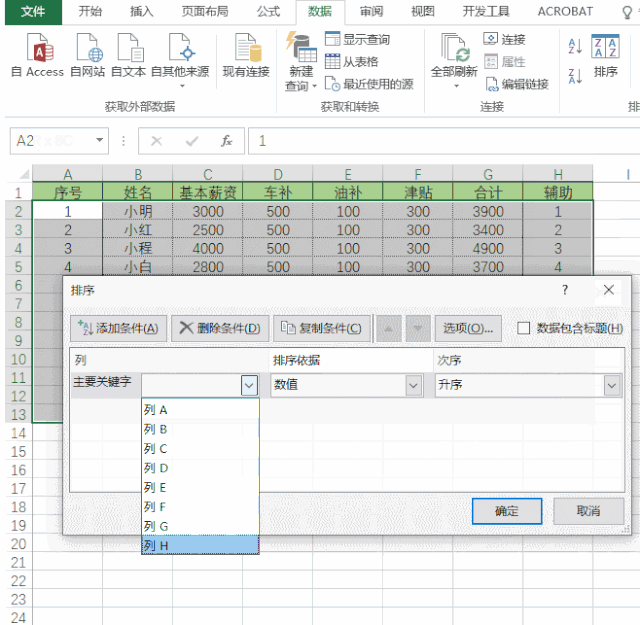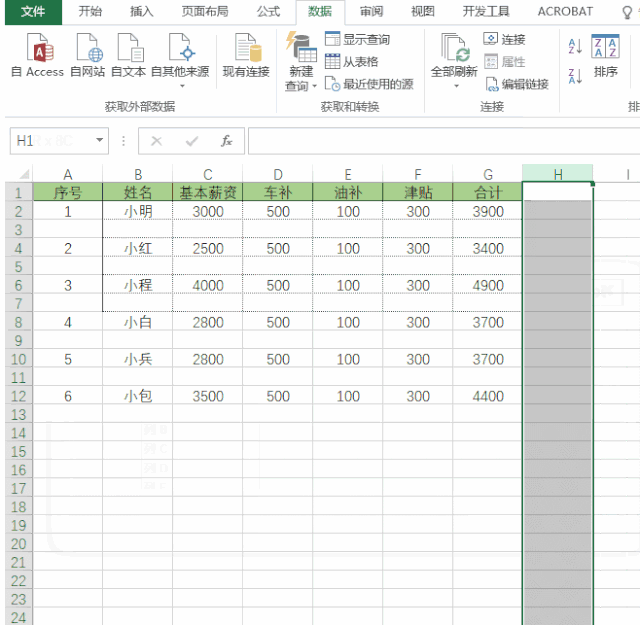
实现V1:
隔行插入空行(暂未实现):
列索引变化
way1
添加一个排序列sort,可以和range一致
通过 df[‘new_col1’] = 5 在末尾插入新的数据行,并设置指定列的值,比如拆分编码
遍历新增后,再通过sort列排序完成最终操作。
way2
切割dataFrame,append行后,再concat
def insert(df, i, df_add):# 指定第i行插入一行数据df1 = df.iloc[:i, :]df2 = df.iloc[i:, :]df_new = pd.concat([df1, df_add, df2], ignore_index=True)return df_newdata = {'name':['li', 'gg', 'zz'],'age':[20, 21, 22],'height':[170, 178, 174]}df = pd.DataFrame(data)print('df:')print(df)df_add = pd.DataFrame({'name':['yy'], 'age':[25], 'height':[168]})# 在第2行插入一条新的数据df_new = insert(df, 1, df_add)print('df_new:')print(df_new)"""df:name age height0 li 20 1701 gg 21 1782 zz 22 174df_new:name age height0 li 20 1701 yy 25 1682 gg 21 1783 zz 22 174"""
拆解列,给指定列赋值:
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2022-01-11 20:04# @Author : yx.Jiang# @File : excel_update.py# @Software: PyCharmimport pandas as pdfrom pandas import DataFramedef read_excel(path='测试.xlsx'):# DataFramedf = pd.read_excel(path, sheet_name="Sheet1")# 最大行数# rows = df.shape[0]# 最大列数# cols = df.columns.size# 获取【商家id】列series = df['商家id']# for val in series.values:# print(val)# a = val.split('+')# print(a)for item in series.items():index = item[0] + 1if index == len(list(series.items())):breakraw_code = item[1]# 跳过空列if (not (type(raw_code) is float)) and raw_code.find('+') != -1:split_tuple = raw_code.split('+')df.loc[index-1, '商家id'] = split_tuple[0]df.loc[index, '商家id'] = split_tuple[1]df.loc[index+1, '商家id'] = split_tuple[2]return dfif __name__ == '__main__':data = read_excel()print(data)DataFrame(data).to_excel('update.xlsx', sheet_name='Sheet1', index=False, header=True)
实现V2:
#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2022/1/17 10:36# @Author : yx.Jiang# @File : interlaced_insertion_blank_line.pyimport pandas as pdfrom pandas import DataFramedef insert(df, i, df_add):# 指定第i行插入一行数据df1 = df.iloc[:i, :]df2 = df.iloc[i:, :]df_new = pd.concat([df1, df_add, df2], ignore_index=True)return df_newdef read_excel(path='测试.xlsx', sheet_name="Sheet1"):if sheet_name is None:sheet_name = 'Sheet1'df_dict = pd.read_excel(path, sheet_name)df = DataFrame(df_dict, index=range(len(df_dict)))businesses = df['商家id']names = df['姓名']ages = df['年龄']headers = df.head(0).columns # Index(['姓名', '年龄', '商家id', 'Unnamed: 3'], dtype='object')length = len(list(businesses.items())) # 数据行长度index = 0 # 原始数据下标insert_index = 0 # 插入行下标for item in businesses.items():insert_index += 1# print(f'index: {index}, length: {length} , insert_index: {insert_index}')if index >= length:breakraw_code = item[1]if raw_code.find('+') != -1:split_tuple = raw_code.split('+') # 需要拆解的列df.loc[insert_index - 1, '商家id'] = split_tuple[0] # 修改原始行# 新增行df_add1 = DataFrame({headers[0]: [names[index]], headers[1]: [ages[index]], headers[2]: [split_tuple[1]]},index=range(0, 1))df = insert(df, insert_index, df_add1)df_add2 = DataFrame({headers[0]: [names[index]], headers[1]: [ages[index]], headers[2]: [split_tuple[2]]},index=range(0, 1))insert_index += 1df = insert(df, insert_index, df_add2)index += 1insert_index += 1return dfif __name__ == '__main__':path = ''while path is None or path == '':path = str(input("请输入excel的路径及名称[如:C:/Users/Administrator/Desktop/测试.xlsx]:"))if path.find('/') != -1:path = path.replace("/", "\\")st_name = str(input("请输入Sheet名称[如:Sheet1(默认)]:"))if st_name == '':st_name = Nonedata = read_excel(path, st_name)DataFrame(data).to_excel('update.xlsx', sheet_name='Sheet1', index=False, header=True)
打包exe
使用pyinstaller打包
命令:Pyinstaller -F interlaced_insertion_blank_line.py -i excel.ico
需要将icon的格式转为ico格式设置程序的icon;
命令执行之后,如下:
进入dist目录执行可执行程序:
解决:进入
path\Anaconda3\envs\py37\Library\bin目录下找到 mkl_intel_thread.1.dll 文件 复制至dist目录下,再次执行可执行程序

按提示输入参数即可:update.xlsx即为生成的excel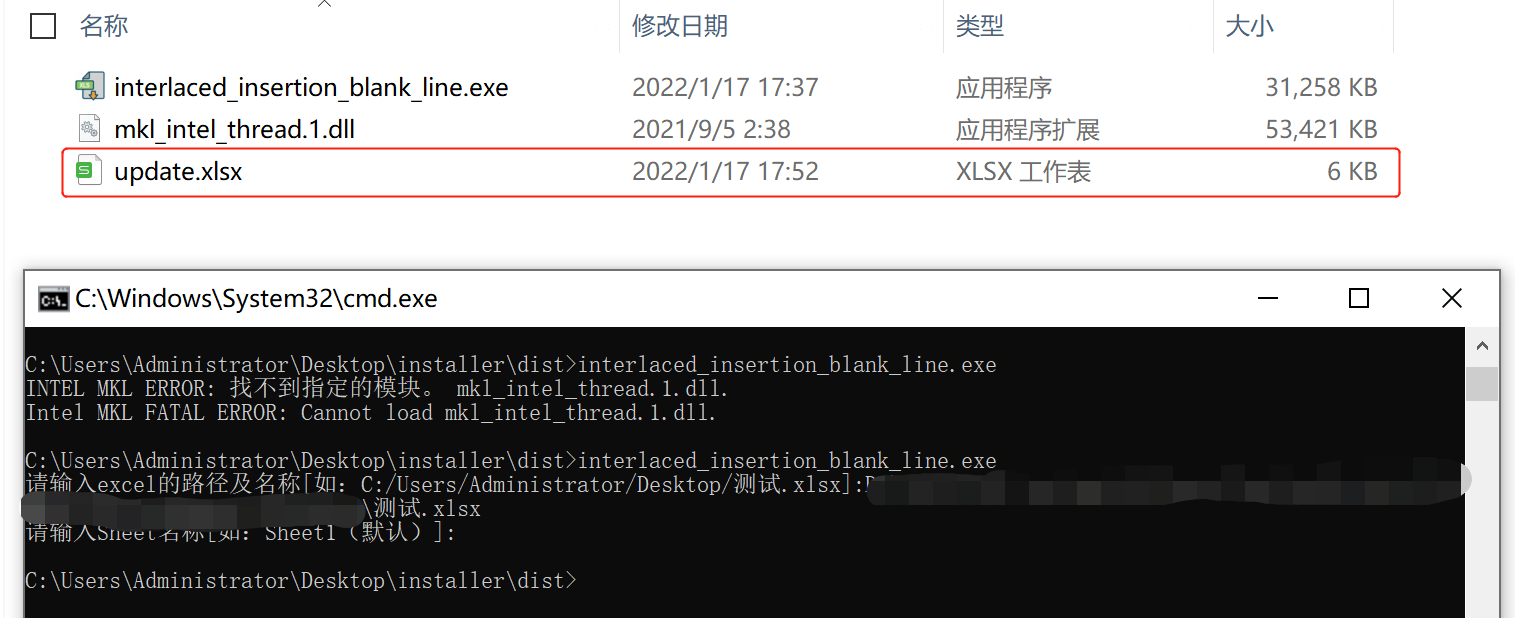

扩展
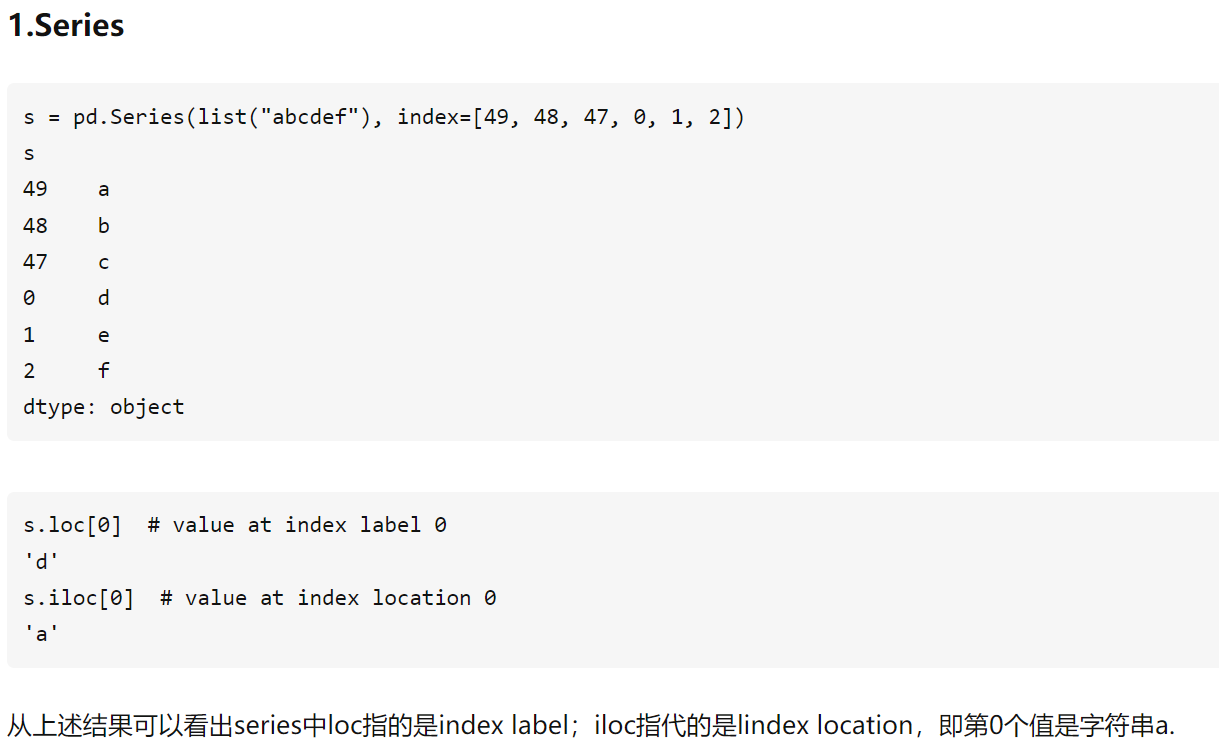

来源: loc和iloc的区别

若有收获,就点个赞吧
0 人点赞
