注:本文写作的时候是基于 Window 10 MySQL 5.7 ,现在笔者迁移以及重构文章的时候是基于 MacOS 和 MySQL 8,系统版本带来的影响主要是一些配置上的问题,而升级到 MySQL 8 更多的是带来了一些新特性,其实对于日常的 MySQL 使用,这两点几乎可以忽略不计,我们更应该将注意力放在 MySQL 本身。
1. 引言
当你登录你的QQ账号和别人吹水的时候,当你期末交作业去度娘复制的时候,当你在工作中登录一些网站的时候,再比如当你查看自己几乎没有什么余额的银行卡的时候(捂脸),或许自己也没注意,(非需要,大部分人也不想注意哈哈哈)我们一直都在以某种方式与数据库打交道,或许你是一个开发人员,也或许你也只是一个普通的用户,数据库与我们的生活息息相关,作为一名程序员,现在学习 MySQL 和 Oracle 的会多一些,像微软的 SQL Server 以前配合 asp 的时候用的还是挺多的,不过现在就没那么流行了。

所以我们先从 MySQL 讲起,同时文章中穿插一些 SQL 的基本概念,我觉得能更好的理解这几种 SQL 型数据库哈
关于 MySQL 的几篇文章,在前一年左右大概更新过几篇,但是都差强人意,所以最近加班加点,重新将 MySQL 相关的,例如语法、约束、事务等等重新整理一遍,第一篇先来看一下入门的一些语法和操作
既然你都打开这篇文章了,那你就注定不是一个村民,这一局我们跳 Java 程序员!
开发学习中,想满足一些需求,与数据打交道这可太频繁了,如何存储这些数据就是你考虑的问题了,当然不考虑性能,管理、安全等等,你的选择可就多了,存个 txt,存个xml,甚至还可以存个excel等等,有位刚入门朋友曾经问过我这样一个问题 “他在学习IO的一些技术的时候,常常会简单的保存一些数据到 .txt 文件中,为什么还需要数据库呢?”,这样的一些小Demo,大家在Java基础的学习中应该都是做过的,那么我们下面就从这个问题讲起~
2. 为什么使用数据库?
2.1 查询速度
假定我们将数据全部存储在一个普通文件中(data.txt 文件,数据以逗号间隔)
......"Eminem",male,1972,"USA""Rihanna",female,1988,"Barbados""Taylor Swift",1989,female,"USA""Aavril Lavigne",1984,female,"Canada"......
如果在我们的数据极为庞大的情况下,我们需要查询其中的一些数据,例如,查询Eminem的国籍,我们一般会使用遍历,但是毫无疑问,这个响应时间会变得极其缓慢,但是使用数据库后,它所提供的一些索引技术等就可以解决这样的问题
2.2 数据完整有效
"Rihanna",female,1988,"Barbados""Rihanna",female,1995,"USA"
如果数据中出现了重名的情况,又如何判断是不是同一个人呢?
如果 data.txt 文件中的数据被错误的修改,例如出生年份被修改为其他类型字符串这种无效表达怎么办?
或许你可以在程序中写一些逻辑判断语句进而筛选处理这些问题,但是仍旧在数据较为庞大的情况下,会出现各种各样的问题,增加了开发者的开发难度,而数据库本身就制定了一些约束,从而保证了数据的完整且,有效,从而使开发者只需要更加注重于程序本身的设计,而不用花费过多的时间去处理数据上的一些细节问题。
2.3 数据共享
常用来简单存储数据的 txt/excel 等均属于单一文件,并且都是无法共享的,只支持当前用户使用并且修改。
而数据库则允许用户共享,不同的用户可以同时存取数据库中的数据,用户也可以用各种方式通过接口使用数据库,并提供数据共享。
2.4 数据的安全性
在我们前者中,数据的修改是很随意的。
但是在实际开发中,我们有时候需要面临,多个用户检索、修改同一文件中的数据,或者在并发情况下,写同一文件或者记录,而数据库基于锁等的一些技术便可以帮助我们解决这些问题(这些锁的问题会在后面的事务以及例如数据库引擎的时候讲解到,前期知道一个概念即可)。
2.5 故障恢复
由于逻辑或者物理上的错误,导致了系统的错误操作,从而使得数据被破坏,如何快速恢复数据,我们上面的单一文件系统显然无法帮助我们解决问题,而数据库却有相关机制去弥补、处理相关问题。
上面我们仅仅从几个常见的点分析了为什么使用数据库,当然远远不止这些,所以总的来说就是数据库其特殊的存储以及管理方式,既提高了效率,也极大的减少了开发人员的负担
总结一下:数据库 em… 是个好东西!

3. MySQL 基本操作
至于安装的部分,这里就不提及了,否则篇幅会过于的长,无论是选择安装版本也好,免安装的压缩包也好,选对版本,装好就行了,可以去网上参考一些教程,至于版本 5.5 -> 5.6 -> 5.7 -> 8 都是可以的,毕竟只是单纯的学习 MySQL,不用过多的考虑和 Java 等的版本或者配置问题,我这台机器版本为 5.7 哈(就目前看来大部分过去的服务还是以 5.7 的居多,不过现在 8 所占的比重也在提升)
同时今天演示的所有内容,直接在 cmd/iterm2 等终端中使用命令执行也可以,也可以直接使用一些图形化工具,例如 Navicat、SQLyog 等等都是可以的,图形化工具看数据会更舒服一些,但是即使图形化工具中,入门的学习,我还是极其不推荐直接点击按钮,执行创建插入等等操作,过于依赖图形界面,会让你的惰性变得更加的大,对在高级语言中自己写 SQL 也是百害无一利,一定要自己书写,执行,才能更好的理解与学习哈
3.1 启动服务
首先登录之前需要启动,相关的 MySQL 服务,有两种方式
- 通过服务窗口设置(我这里介绍的是 Windows 方式)
- cmd—> services.msc —> 找到 MySQL 服务 —> 设置启动,禁止等
通过命令启动
安装版 点击 MySQL 5.7 Command Line Client 后输入密码即可(安装后就有,可以看任务栏)
- 安装 8 版本也基本大同小异
- 通过命令行
- 如果没有配置环境变量,需要在通过 cd 命令指向到 mysql 安装目录下的 bin文件夹
- 如果 MySQL/bin 已经在环境变量中了,直接执行命令就可以了
- 命令行示例: ```shell mysql -u用户名 -p密码
mysql -u用户名 -p
mysql -h 地址 -P 端口 -u用户名 -p
举例:用户名:root,密码:root99- `mysql -uroot -proot99 `- 这种情况下,会弹出一个警告,它认为在命令行中明文的输入密码是不安全的- 说明:我用的是 Mac 下的 iTerm2 ,理解为 cmd 即可。- mysql -uroot -p- 这种情况下,密码输入会被遮掩(Window 是星号,Mac 是直接看不到),警告就消失了- mysql -h 192.168.3.144 -P 3306 -uroot -p- 这种方式用来连接远程的数据库,我这里用我本地的虚拟机演示了一下<a name="6a227c5b"></a>### 3.2.2 退出```sqlexitquit
4. SQL简单认识
4.1 什么是SQL?
4.1.1 基本概念
Structured Query Language:结构化查询语言。
SQL就是访问和处理关系数据库的计算机标准语言,它定义了操作所有关系型数据库的规则。
虽然 SQL 的语法标准很多部分可以直接在其他 DBMS 上使用,不过大部分数据库在SQL的标准上进行了扩展。而每一种数据库操作的方式存在不一样的地方,称为“方言”。
但凡涉及到关系型数据库就离不开SQL,例如在电商网站中存入商品信息,游戏中存储装备道具信息等。
4.1.2 常见分类
常见的关系型数据库:MySQL 、Oracle、Microsoft SQL Server、Microsoft Access、DB2、
- 商用:Oracle、DB2、Microsoft SQL Server
- 开源:MySQL
- 桌面:Microsoft Access
常见的非关系型数据库:Cloudant、MongoDb、Redis、HBase
4.1.3 总结
总之:SQL 是一种强力的语言,我们可以通过一定简洁的语法,实现各种复杂的需求
4.1.4 补充事项
- SQL语句 单行或多行书写,以分号结尾,并且可以使用空格和缩进来增强语句的可读性
- MySQL 数据库的 SQL 语句不区分大小写,关键字建议使用大写
三种注释
单行注释
-- 注释内容# 注释内容 (这是MySQL独有的)
多行注释
/* 注释内容 */
4.2 SQL分类
| 分类 | 作用 | | —- | —- | | 数据定义语言——DDL(Data Definition Language) | 允许用户定义 (创建) 数据库对象:数据库,表,列等 | | 数据操作语言——DML(Data Manipulation Language) | 允许用户对数据库中表的数据进行增删改 | | 数据查询语言——DQL(Data Query Language) | 允许用户查询数据库中表的记录(数据) | | 数据控制语言——DCL(Data Control Language) | 用来定义数据库的访问权限和安全级别,及创建用户 |
5. MySQL 语法详解
5.1 操作数据库
其实这部分语法的介绍,围绕的就是 CURD
- CURE —> C:创建(Create)+ U:修改(Update)+ R:查询 / 读取(Retrieve)+ D:删除(Delete)
例如创建、查询、使用数据库中表中的一条一条的记录是比较常用的,但是对于数据库和表的操作并不会很频繁,一般初期设置好后,很少会去修改数据库,所以这一部分,快速了解就好了,标题中标 ※ 符号的要会用
5.1.1 创建数据库 ※
- 创建数据库
举例: ```sql mysql> CREATE DATABASE mysql_grammar_test;CREATE DATABASE 数据库名称;
Query OK, 1 row affected (0.12 sec)
2. **创建数据库,判断不存在,再创建**```sqlCREATE DATABASE IF NOT EXISTS 数据库名称;
创建数据库,并且制定字符集
CREATE DATABASE 数据库名称 CHARACTER SET 字符集名;
5.1.2 修改数据库
修改数据库的字符集
ALTER DATABASE 数据库名称 CHARACTER SET 字符集名称;
5.1.3 查询数据库 ※
查询所有数据库名称
- 这台电脑上没怎么用本地的数据库,只有几个默认的库和自己测试的库
SHOW DATABASES
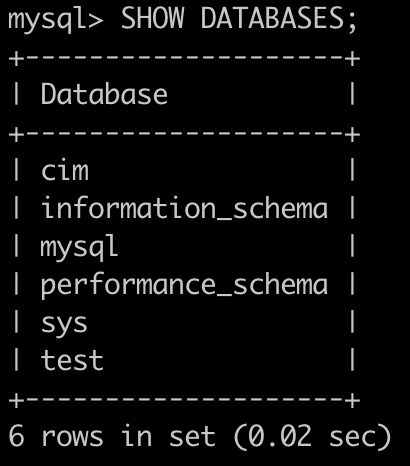
- 这台电脑上没怎么用本地的数据库,只有几个默认的库和自己测试的库
查询某个数据库的字符集
- 通过查询某个数据库的创建语句就可以看到其字符集,前面创建的时候,我们并没有指定字符集,但是可以看到默认数据库字符集为 utf-8
举例:SHOW CREATE DATABASE 数据库名称;
mysql> SHOW CREATE DATABASE mysql_grammar_test;+--------------------+-----------------------------------------------------------------------------+| Database | Create Database |+--------------------+-----------------------------------------------------------------------------+| mysql_grammar_test | CREATE DATABASE `mysql_grammar_test` /*!40100 DEFAULT CHARACTER SET utf8 */ |+--------------------+-----------------------------------------------------------------------------+1 row in set (0.00 sec)
5.1.4 删除数据库
- 通过查询某个数据库的创建语句就可以看到其字符集,前面创建的时候,我们并没有指定字符集,但是可以看到默认数据库字符集为 utf-8
删除数据库
DROP DATABASE 数据库名称;
判断数据库存在,存在再删除
DROP DATABASE IF EXISTS 数据库名称;
5.1.5 使用数据库 ※
关于数据库常用的增删改查就说完了,下面要开始讲解关于表和数据了,但是我们必须指定使用的数据库,才可以针对这个数据进行一些操作表或数据等等操作
查询当前正在使用的数据库名称
SELECT DATABASE();
使用数据库
USE 数据库名称;
5.2 操作表
符号规定:下面展示一些定义的时候,为简便理解,使用中文配合符号表述(会有具体举例,不用担心理解不了)
<>中的内容为实际的语义[]中的内容为任选项(不填写也可){}中的内容必须显式的指定|为选项符[,...n]表示前面的项可以重复多次5.2.1 创建表 ※
SQL 语言通过定义一个关系所对应的基本表来完成关系模式的定义,其语句格式为:
当然了你看完这个定义可能一下子不好理解,我在后面,会就着一个实际的例子,来和大家讲解,在此之前有两个重要的知识需要补充:CREATE TABLE 表名(<列名1> <数据类型1> [<列级完整约束条件>],[<列名2> <数据类型2> [<列级完整约束条件>],...],[<表级完整约束条件>]);
5.2.1.1 数据类型
关系中的每一个属性,都来自一个域,它的取值必须是域中的值,而在 SQL 中,这个域的概念,用数据类型来实现,就比如,我们定义的这一列数据都只能是 8个单位长度以内的字符串
下面列了几种常见的数据类型
| 数据类型 | 含义 |
|---|---|
| CHAR(n) | 长度为 n 的定长字符串 |
| VARCHAR(n) | 最长度为 n 的边长字符串 |
| INT 或 INTERGER | 长整数 |
| SMALLINT | 短整数 |
| DOUBLE(6,3) | 双精度浮点数,代表共保留6位数字,小数点后保留3位(也可不设置直接使用) |
| FLOAT(n) | 浮点数,精度至少为 n 位数字(也可不设置直接使用) |
| DATE | 日期,只包含年月日,yyyy-MM-dd |
| TIMESTAMP | 时间戳类型,包含年月日时分秒,yyyy-MM-dd HH:mm:ss |
5.2.1.2 约束条件
约束,就是针对属性值的一些约束条件,只针对某一列,叫做列级约束、针对多列属性的约束,叫做表级约束,怎么理解呢?就例如某一列叫做 学号,我们就指定约束,这一行不允许为 NULL 等等
约束要想说清楚,还是需要一点篇幅的,同时例如外键约束等,就会引申出一些多表之间的问题,为了简便,在这一篇入门文章中就不写关于约束以及多表的问题了,我后面两篇将专门写这部分相关的内容
5.2.1.3 创建表举例
简单解释一下,创建一个学生表,其中有这么几个字段(列)学号、姓名、年龄、出生日期、成绩、插入时间,指定 stu_id 也就是学号作为主键,至于一些非空或者 id 自增我都没有设置哈
CREATE TABLE student(stu_id INT,stu_name VARCHAR(32),stu_age INT,stu_birthday DATE,stu_score DOUBLE(4,1),stu_insert_time TIMESTAMP,PRIMARY KEY(stu_id));
5.2.2 修改表
修改表名
ALTER TABLE 表名 RENAME TO 新表名;
修改列名称和类型
ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型;
修改类型
ALTER TABLE 表名 MODIFY 列名 新数据类型;
修改表的字符集
ALTER TABLE 表名 CHARACTER SET 字符集名称;
添加一列
ALTER TABLE 表名 ADD 列名 数据类型;
5.2.3 查询表
查询某个数据库中所有的表名
SHOW TABLES;
查询表结构
DESC 表名;
5.2.4 删除表
```sql DROP TABLE 表名;
Drop TABLE IF EXISTS 表名;
<a name="63e98980"></a>## 5.3 增删改表中数据 ※※※这一块的内容,实际上才是我们通俗意义上的增删改查,这一块也是用的最多的,毕竟数据库和表,一般初期都会设计好,除非临时有大的需求变更,否则很少会去修改<a name="8e08135d"></a>### 5.3.1 添加数据 ※1. **基本语法:**```sqlINSERT INTO 表名(列名1,列名2,...列名n) VALUES(值1,值2,...值n);
- 举个例子
就用上面创建的学生表
INSERT INTO student(stu_id, stu_name, stu_age, stu_birthday, stu_score, stu_insert_time) VALUES (1001,'张三',20,'2021-05-30',66.6,'2021-05-30 19:00:35');
注意
基本语法
DELETE FROM 表名 [WHERE 条件]
删除数据的条件就很灵活了,在这个部分,我给大家列几种例子,例如在插入这样三条记录的基础上 ```sql INSERT INTO student(stu_id, stu_name, stu_age, stu_birthday, stu_score, stu_insert_time) Values(1001,’张三’,20,’2021-05-30’,66.6,’2021-05-30 19:00:35’);
INSERT INTO student(stu_id, stu_name, stu_age, stu_birthday, stu_score, stu_insert_time) Values(1002,’李四’,25,’2021-05-30’,66.6,’2021-05-30 19:00:35’);
INSERT INTO student(stu_id, stu_name, stu_age, stu_birthday, stu_score, stu_insert_time) Values(1003,’王五’,16,’2021-05-30’,66.6,’2021-05-30 19:00:35’);
- 例 1:删除 stu_id(学号)值为 1001 的记录```sqlDELETE FROM student WHERE stu_id = 1001;
例 2:删除 stu_name(姓名)值为张三的记录
DELETE FROM student WHERE stu_name = '张三';
例 3:删除 stu_age(年龄)大于 20 的记录
DELETE FROM student WHERE stu_age >= 20;
- 删除所有数据
如果不填写删除语句中的条件部分,则会删除表中的所有数据,慎用
DELETE FROM 表名;
即使非要删除所有数据,但是这种方式并不推荐,因为这种方式下有多少条记录就会执行多少次删除操作,数据量大的情况下,效率很低
推荐使用
TRUNCATE TABLE 表名;
它的机制是,先删除掉整个表,然后再创建一个空的,与原来一样的表,效率会更高一些
5.3.3 修改数据 ※
UPDATE 表名 SET 列名1 = 值1, 列名2 = 值2,... [WHERE 条件];
关于修改数据,一般情况下,都是通过在条件中,指定某个 id 值,然后去修改,因为这个 id 值一般都是主键,能确定唯一数据
例 1:例如下面,修改学号为 1001 学生的 出生日期和成绩
UPDATE student SET stu_birthday = '2020-02-22', stu_score = 90.8 WHERE stu_id = 1001;
你自己测试的时候可以发现,换种写法即使不指定
WHERE stu_id = 1001似乎也能执行成功UPDATE student SET stu_id = 1001, stu_birthday = '2020-02-22', stu_score = 90.8;
这是因为前面我们已经传入了主键
stu_id = 1001,一般我们修改数据还是在后面设置条件更多补充:一般,我们在高级语言中使用 MySQL 的时候,不考虑使用插件,自己写 SQL 的时候大部分情况都是直接写出所有字段的,并不会向上面一样,只写出某几项,因为我们不确定每次用户需要修改的数据是哪几项,最后执行的效果可以模拟为:
UPDATE student SET stu_id = 1001, stu_name = '张三', stu_age = 20, stu_birthday = '2020-01-01', stu_score = 90.8, stu_insert_time = '2020-02-22' WHERE stu_id = 1001;
也就是,不需要更新的也列了出来,只不过更新的值没有变化而已,这样可以满足用户各种的修改情况,这部分内容,在 JDBC 的相关文章中才是重点,这里也不过多提及了
5.4 查询表中的数据 ※
这一块内容比较多,单独摘出来说,多说一句,这一块的内容,还只是涉及到单表的查询,至于多表复杂的查询,会在下一篇讲完约束以后提到
5.4.1 查询所有
这个非常常用,
*代表所有,然后 FROM 指定表名就可以了,它会将所有记录的完整信息列出来SELECT * FROM 表名;
提一个小 Tips ,如果特别注重效率的话例如在 MyBatis 配合插件,就会直接使用插件生成的 Base_Column_List ,作为查询的值,这个Base_Column_List 就代表所有的字段(列),用 如果后期字段存在增长的问题,在一定程度上这样的书写方式会提高一些效率,而且会有一些安全性上的提升,但是就在刚入门的学习中,即使用 也还好,不够实际书写项目,强烈建议直接指定查询字段。
5.4.2 查询指定字段(列)
如果只需要查询指定的几个字段,可以通过下面的方法,列出指定字段,通过逗号分隔
SELECT 字段名1,字段名2... FROM 表名;
5.4.3 条件查询
- 所有的条件查询语句,都是基于 WHERE 进行使用的
- WHERE 后配合各种运算符,就可以灵活的实现很多查询需求(这些我们下面都会讲到)
> 、< 、<= 、>= 、= 、<>IS NULL 或 IS NOT NULLAND 或 &&BETWEEN...ANDOR 或 ||NOT 或 !IN( 集合)LIKE:模糊查询_:单个任意字符占位符%:多个任意字符占位符
- 举些例子
- 例 1 :查询成绩不等于 66.6 的学生 ```sql SELECT * FROM student WHERE stu_score != 66.6;
SELECT * FROM student WHERE stu_score <> 66.6;
- **例 2:查询成绩是否为 NULL(例如未录入)**```sql-- 查询哪些学生成绩字段为 NULLSELECT * FROM student WHERE stu_score IS NULL;-- 查询哪些学生成绩字段不为 NULLSELECT * FROM student WHERE stu_score IS NOT NULL;-- 这是一种错误的写法,NULL的判断是不能用等号的SELECT * FROM student WHERE stu_score = NULL; (错误!!!)
- 例 3:查询成绩大于等于60小于80的学生(成绩良好) ```sql SELECT * FROM student WHERE stu_score >=60.0 AND stu_score <= 80.0;
SELECT * FROM student WHERE stu_score >=60.0 && stu_score <= 80.0;
SELECT * FROM student WHERE stu_score BETWEEN 60.0 AND 80.0;
- **例 4:查询成绩为 40.0 ,90.8 的学生,下面三种查出来结果是一样的**```sqlSELECT * FROM student WHERE stu_score = 40.0 OR stu_score = 90.8;SELECT * FROM student WHERE stu_score = 40.0 || stu_score = 90.8;SELECT * FROM student WHERE stu_score IN (40.0,90.8);
这里要注意了,我上面在 OR 中使用 = 测试,是为了引出 IN 的这个使用方式,但是就没有很好的体现出 OR 和 AND 的区别了
- AND 的字面意思为并且,而 OR 为或者,也就是说 OR 的时候,只需要满足一边的要求就可以查出来
当例如我们也使用大于小于这种运算符,就会体现出问题了
SELECT * FROM student WHERE stu_score >= 60.0 OR stu_score <= 80.0;
它的意思是先查询到成绩 >= 60.0 的所有数据,然后再查询到成绩 <= 80.0 的所有数据,这一点要注意哦
例 5:模糊查询:查询姓张的学生有哪些
SELECT * FROM student WHERE stu_name LIKE '张%';
例 6:模糊查询:查询姓名中第二个字为四的学生
SELECT * FROM student WHERE stu_name LIKE '_四%';
例 7:模糊查询:查询姓名长度为 4 个字的学生(四个
**_**)SELECT * FROM student WHERE stu_name LIKE '____';
例 8:模糊查询:查询姓名中含有五这个字的学生
SELECT * FROM student WHERE stu_name LIKE '%五%';
5.4.4 排序查询
我们很多时候,查询到的数据都是按照主键,例如 id 为顺序的,不过如果我们想要查询到的数据按照一定的方式排序,就用到了 ORDER BY 这个语句,语法如下 ```sql ORDER BY 排序字段1 排序方式1 ,排序字段2 排序方式2…
— 排序方式: ASC:升序,默认的。 DESC:降序
**注意:**1. 只有排序字段 1 的值相同时,才会执行排序字段 2,如果没有排序字段 2,则按照主键默认排序1. 默认的排序方式是升序,即由低到高- **例 1:按成绩从高到低排序查询(降序)**```sqlSELECT * FROM student ORDER BY stu_score DESC;
- 例 2:按成绩以及从高到低排序查询(降序),其次按照年龄由低到高排序(升序)
SELECT * FROM student ORDER BY stu_score DESC, stu_age ASC;
5.4.5 分组查询
- 基本语法
GROUP BY 分组字段
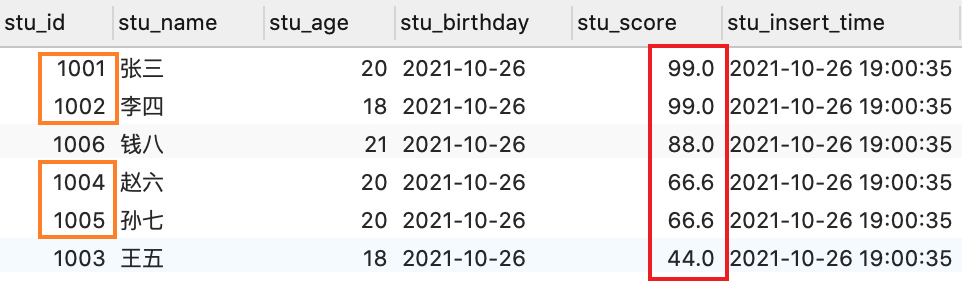
- 例 1:按照年龄分组,分别查询年龄为18岁以及20岁同学的平均分,以及人数, 同时要求:不及格的同学,不计入分组
SELECT stu_age, AVG(stu_score), COUNT(stu_id) FROM student WHERE stu_score > 60 GROUP BY stu_age;
说明:AVG 方法是求平均值的,COUNT 方法是求个数的
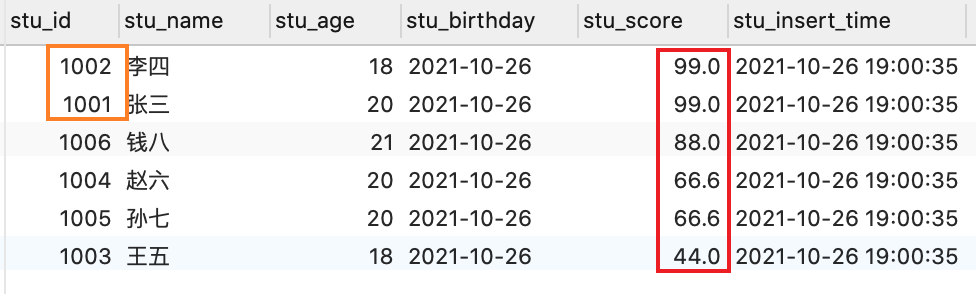
这个可能不好理解,同样配个图,先看一下所有的数据,有 6 位同学,年龄有 18 20 21 这三个,当然一般用男女或者班级,系别等区分会更加贴近现实,我只是懒得,再创建一张表了,就姑且用年龄演示就好了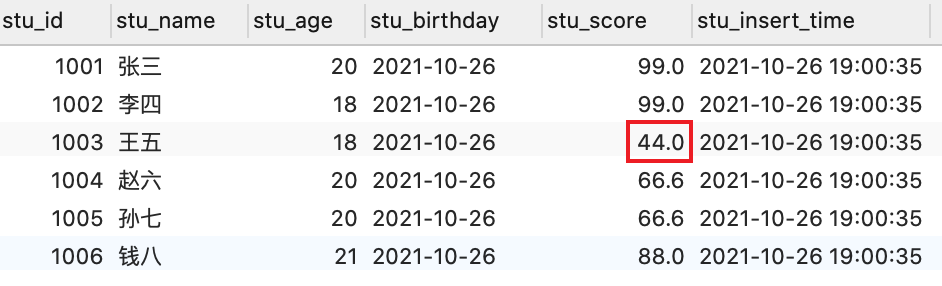
可以看到对应的一些值就查到了,并且不及格的同学并没有参与到分组中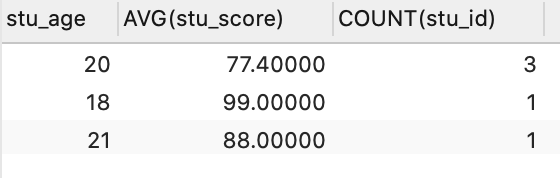
- 例 2:按照年龄分组,分别查询年龄为18岁以及20岁同学的平均分,以及人数, 同时要求:分数低于60分的人,不参与分组,分组之后,人数要大于 2 个人
执行上述代码后,现在就只剩下分组后人数大于 3 的数据了,这是为什么呢?SELECT stu_age, AVG(stu_score), COUNT(stu_id) FROM student WHERE stu_score > 60 GROUP BY stu_age HAVING COUNT(stu_id) > 2;
这个地方就要引入一个新的概念,就是 HAVING
WHERE 和 HAVING 有什么区别呢?
- WHERE 在分组之前进行限定,不满足则不分组
- HAVING在分组之后进行限定,不满足则查不到
- WHERE 后不可以跟聚合函数,HAVING 可以进行聚合函数的判断,例如 AVG 方法、COUNT 方法都是聚合函数
上面例 2 的执行结果:
聚合函数补充:
聚合函数:将一列数据作为一个整体,进行纵向的计算,尽量选择不为空的列进行计算,否则就需要使用 IFNULL 函数进行判断
COUNT:计算个数 -- 一般选择非空的列:主键MAX:计算最大值MIN:计算最小值SUM:计算和AVG:计算平均值
5.4.6 分页查询
如果查询到的数据太多,在同一个页面上显示,很麻烦,分页查询就可以解决这个问题
- 基本语法
2、基本书写公式套路limit 开始的索引,每页查询的条数;
开始的索引 = (当前的页码 - 1) * 每页显示的条数
- 例 1:每页显示 2 条数据 ```sql SELECT * FROM student LIMIT 0,2; — 第1页
SELECT * FROM student LIMIT 2,2; — 第2页
SELECT * FROM student LIMIT 4,2; — 第3页
SELECT * FROM student LIMIT 6,2; — 第4页
```
我暂时表中有7条数据 id 从 1001-1007 ,所以例如我执行显示第二页的语句,就会显示 id 为1003 以及 1004 的数据
另外,LIMIT 是一个MySQL”方言”,在其他数据库中就不支持了,但是不同的数据库,都会有一些替代的写法。

若有收获,就点个赞吧
0 人点赞
