在基础篇中主要讲解了 MySQL 的入门和各种常见用法,而后面的进阶篇会适当的补充一些原理性质,以及调优性质的内容,而第一篇主要是,先对过去的内容做一个小结,不过重点还是实际开发中的一些小 case,与前面的内容也尽量不重合。
1. 三大范式
首先是三大范式,而范式其实就是在设计数据库的时候,我们需要满足的一些规则规范。它能够帮助我们设计出一个简洁高效的数据库。
1.1 第一范式
定义:所有列不可以再分。
简单的说,就是要保证某张表中的某个字段,是原子的。
例如我们经常看到的表结构会有,姓名、性别、手机号、邮箱等等字段,那么为什么不直接叫做 联系人信息字段呢?然后存一个字符串或者 Json 串。其实主要也是遵循了第一范式。
还有一些场景,例如如下我拟了一个考勤表,其中需要记录打卡地点。我们也可以直接把地址存在 address 字段中,但是如果你想要针对地址中的某个部分去做操作,就需要把 address 读取后拆分处理。如果存储的时候就做了这一步,那么我们读取修改的时候就会方便很多。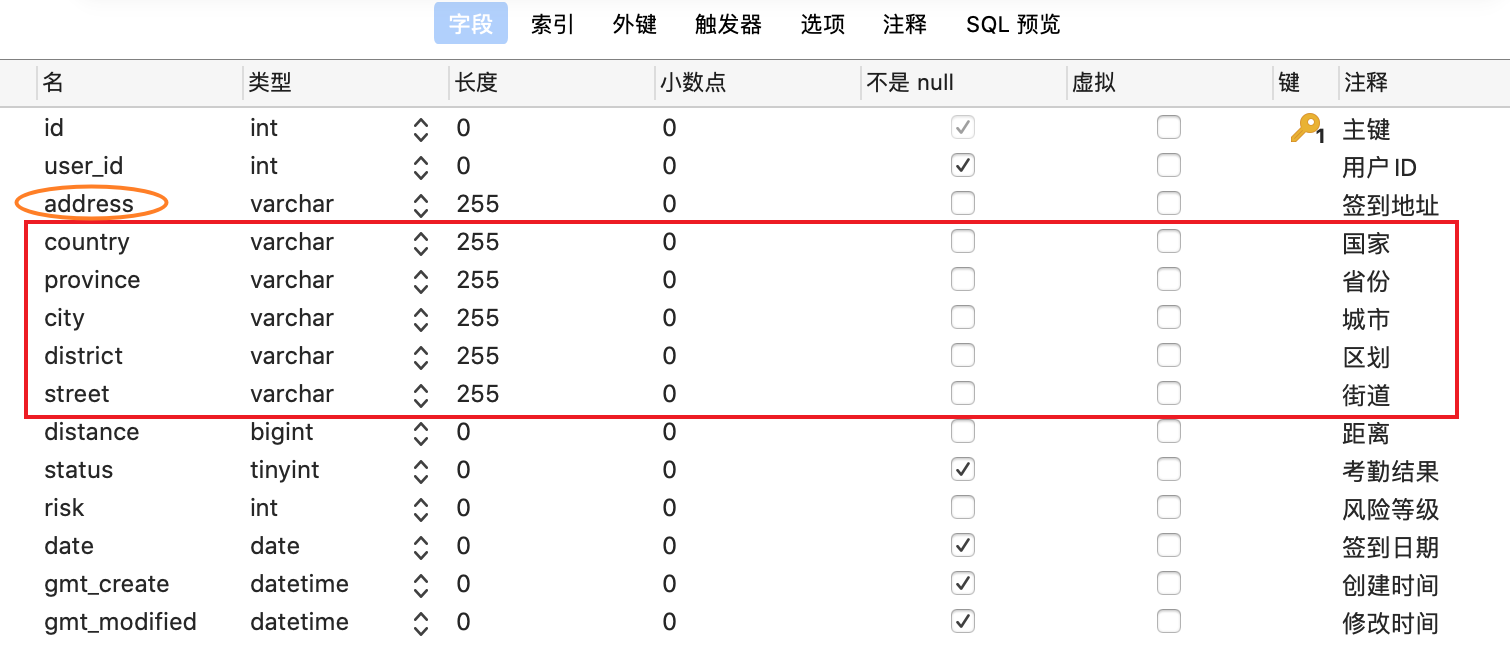
1.2 第二范式
定义:第二范式在基于第一范式的基础上,要求表中的每条记录都能被唯一区分,即设置主键,同时要求非主键字段全部依赖于主键字段。
第二范式的要求,简单的说就是,首先必须要设置主键(主键最好与业务无关,例如自增id),同时在一张表中只能保存一种数据。
解释一下:例如我们用户表就是用来存储用户相关信息的数据表,其中各个除了主键外的字段都与用户信息相关,且能被主键唯一确认。在遵循这种范式的前提下,在其他表中就可以通过用户表主键作为外键的方式引入我们需要的数据,防止冗余,利于管理。
1.3 第三范式
定义:依然是在前两大范式的基础上,要求非主键列不能依赖于除了主键列以外的其它列。
例如,在一张用户表中,主键为自增的id,字段包括用户信息,但是还包括角色的相关信息,例如角色名称,角色描述。这就是典型的不满足第三范式,因为其实在用户表中已经出现了冗余字段,即角色相关信息,如果当角色信息被更新的时候,那么如果不同步更新所有用到这个角色信息的用户信息,就会导致数据不一致,这是很危险的。
所以一般都会只留一个角色的 id 编号等,从而解耦。
小结:一般来说,前两个范式还好,第三范式偶尔不一定能完全满足,我们可以根据自己的需要取舍,进行一定的反范式,例如保留适当的容易,以减少 join 等的次数。因为越严格的遵循第三范式就会导致需要多次 join 数据,造成性能上的损失,不允许 join 的情况下, 也需要在内存中进行匹配。所以这一点上可以根据业务适当的自我平衡。
2. 数据类型
2.1 整型
1. 表达是否概念的字段,必须使用 is_xxx 的方式命名,数据类型必须是 unsigned tinyint (1 代表是,0代表否)
- 首先是关于命名,POJO 类中的任何布尔类型的变量,都不要加 is 前缀,所以,需要在
设置从 is_xxx 到 Xxx 的映射关系。数据库表示是与否的值,使用 tinyint 类型,坚持 is_xxx 的命名方式是为了明确其取值含义与取值范围。 - 第二个就是关于 unsigned ,它的含义就是无符号,例如 tinyint -128 ~ 127 的范围,如果使用了 unsigned ,就会取非负,然后使得正向的范围翻倍:0~255。
2. 占用字节的大小,只与类型有关,与类型括号后的数字无关
- 例如 int(1) 和 int(255) 其实本质上占用的空间都是一定的,它其实只是列宽的展示,如果位数不够就会补充0,对于实际占用大小无关。
- 所以这也是为什么表达是否概念的内容推荐使用 tinyint 而不是 int | 数据类型 | 占据空间 | 范围(有符号) | 范围(无符号) | 描述 | | —- | —- | —- | —- | —- | | tinyint | 1 个字节 | -2^7 ~ 2^7-1 | 0 - 255 | 小整数值 | | smallint | 2 个字节 | -2^15 ~ 2^15-1 | 0 - 65535 | 大整数值 | | mediumint | 3 个字节 | -2^23 ~ 2^23-1 | 0 - 16777215 | 大整数值 | | int | 4 个字节 | -2^31 ~ 2^31-1 | 0 - 4294967295 | 大整数值 | | bigint | 8 个字节 | -2^63 ~ 2^63-1 | 0 - 18446744073709551615 | 极大整数值 |
2.2 字符和字符串
当你遇到 char(5) 、varchar(255) 可能会觉得,它们占用的空间也是固定的,但是,其实这里就有出入了。char 代表固定长度,varchar 代表可变长度,就像 Java 中数组和 List 的感觉。
- 对于 char(5) 来说,不管你是否用到了,但是一定会会占据 5 个字符的空间。
- 对于 varchar(5) 来说,只是代表你最多能存储 5 个字符,而实际的占用空间是根据输入伸缩的。
虽然看起来 varchar 会更好,不过 char 也有其优势,例如不需要考虑边界问题,读写效率更高,适合一些读写很频繁,但是存储长度固定的数据,而 varchar 更适合更新不频繁,但是长度处于波动的数据,char 长度不够灵活,但是 varchar 需要使用 1 ~ 2 个字节存储当前的实际长度。
根据场景自行取舍即可,例如手机号身份证等等定长的字段,就更适合用 char,其它一些可变的用 varchar
2.3 小数
| 数据类型 | 占据空间 | 是够精确 |
|---|---|---|
| float | 4个字节 | 非精确 |
| double | 8 个字节 | 非精确 |
| decimal | 存9个数字占据4个字节,小数点占一个字节 | 精确 |
知道上表即可,所以单从效率方向看,decimal 不一定如 float 和 double,为了规避小数点,也可以直接将金额相关的单位设置为分级别的。
2.4 时间类型
| 数据类型 | 占据空间 | 取值范围 |
|---|---|---|
| date | 3个字节 | 1000-01-01 ~ 9999-12-31 |
| time | 3~6个字节 | -838:59:59 ~ 838:59:59 |
| datetime | 5~8个字节 | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| timestamp | 4~7个字节 | 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07 |
DATETIME 的范围更大,内存也稍大,而TIMESTAMP的时间会根据时区变化,有些时候也可以存储 Long 类型的时间戳。

若有收获,就点个赞吧
0 人点赞
