安装(使用kubeadm安装)
系统要求
提示:
如果您的centos的版本低于7.8建议更新,更新命令如下:
#推荐使用upgrade方式因为它会过滤废弃的安装包➜ yum -y upgrade 或 yum -y update
Kubernetes v1.21 开始,默认移除 docker 的依赖,如果宿主机上安装了 docker 和 containerd,将优先使用 docker 作为容器运行引擎,如果宿主机上未安装 docker 只安装了 containerd,将使用 containerd 作为容器运行引擎;本文使用 containerd 作为容器运行引擎;
- 关于二进制安装kubeadm 是 Kubernetes 官方支持的安装方式,“二进制” 不是。本文档采用kubernetes.io 官方推荐的 kubeadm 工具安装 kubernetes 集群。
1. 修改主机名
➜ hostnamectl set-hostname master-0 (master-0机器执行)➜ hostnamectl set-hostname node1 (node1 机器执行)➜ hostnamectl set-hostname node2 (node2 机器执行)➜ cat >>/etc/hosts <<EOF192.168.xxx.1 master192.168.xxx.2 node1192.168.xxx.3 node2EOF
执行完成后,记得ping一下看能够ping通 比如再master机器上执行
2. 关闭防火墙
➜ systemctl stop firewalld➜ systemctl disable firewalld
3. 关闭swap分区
➜ swapoff -a➜ sed -ri 's/.*swap.*/#&/' /etc/fstab #其实就是找到swap那一行,/etc/fstab在开头加#
4. 将 SELinux 设置为 permissive 模式(相当于将其禁用)
➜ sudo setenforce 0➜ sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
5. 打开ipv6流量转发和时区同步
➜ cat > /etc/sysctl.d/k8s.conf << EOFnet.ipv4.ip_forward = 1net.bridge.bridge-nf-call-ip6tables = 1net.bridge.bridge-nf-call-iptables = 1EOF➜ sysctl --system #立即生效
6. 安装containerd
默认情况下,Kubernetes 使用容器运行时接口(Container Runtime Interface,CRI) 来与你所选择的容器运行时交互,如果你不指定运行时,则 kubeadm 会自动尝试检测到系统上已经安装的运行时对应的套接字路径:
- Docker /var/run/dockershim.sock
- containerd /run/containerd/containerd.sock 我们安装这个作为CRI
- CRI-O /var/run/crio/crio.sock
➜ cat <<EOF | sudo tee /etc/modules-load.d/containerd.confoverlaybr_netfilterEOF➜ modprobe overlay➜ modprobe br_netfilter#如果报错(modprobe: FATAL: Module br_netfilter not found. 重启下机器)# 如果这里你安装了docker下面5步可以忽略,并且看我部署异常的第一条,否则也会出现同样的问题安装 Containerd卸载旧版本可使用:yum remove -y containerd.io 我这里未安装其它版本,暂未用到设置 yum repository➜ sudo yum install -y yum-utils➜ sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo使用这一条命令安装cro,不建议安装docker➜ sudo yum install -y containerd.io下面两条是安装docker的,没用到就忽略➜ sudo yum install docker-ce docker-ce-cli containerd.io➜ sudo systemctl enable --now docker配置 containerd➜ mkdir -p /etc/containerd➜ containerd config default | sudo tee /etc/containerd/config.toml➜ sed -i "s#k8s.gcr.io#registry.aliyuncs.com/k8sxio#g" /etc/containerd/config.toml使用 systemd cgroup 驱动程序,添加这一行SystemdCgrou= true(第97行)➜ sed -i '/containerd.runtimes.runc.options/a\ \ \ \ \ \ \ \ \ \ \ \ SystemdCgroup = true' /etc/containerd/config.toml➜ export REGISTRY_MIRROR=https://registry.cn-hangzhou.aliyuncs.com➜ sed -i "s#https://registry-1.docker.io#${REGISTRY_MIRROR}#g" /etc/containerd/config.toml重新启动 containerd➜ systemctl restart containerd➜ systemctl status containerd设置容器代理(我这里不涉及其它外网容器,一般都能通过国内镜像,这里也暂未设置)➜ mkdir -p /etc/systemd/system/containerd.service.d➜ cat > /etc/systemd/system/containerd.service.d/proxy.conf << EOF[Service]Environment="HTTP_PROXY=http://10.10.10.111:7890/"Environment="HTTPS_PROXY=http://10.10.10.111:7890/"Environment="FTP_PROXY=http://10.10.10.111:7890/"Environment="NO_PROXY=localhost,master-0,127.0.0.1,10.10.10.0/24,10.0.0.0/8,10.244.0.0/16,10.96.0.0/12,::1"EOF➜ systemctl daemon-reload➜ systemctl enable --now containerd➜ # systemctl status containerd我这里是这个版本containerd.io 1.4.9➜ containerd --version
7. 安装/卸载 kubeadm,kubelet,kubectl
- kubeadm —— 启动 k8s 集群的命令工具
- kubelet —— 集群容器内的命令工具
- kubectl —— 操作集群的命令工具
```bash
配置国内Kubernetes源:
➜ cat <
/etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF 配置国外Kubernetes源(如过你安装了代理如clash,需要国外源可这样设置,我这里暂未设置): ➜ cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg EOF
卸载旧版本(如果你未安装,无需执行) ➜ yum remove -y kubelet kubeadm kubectl
安装三件套 kubelet kubeadm kubectl
➜ sudo yum install -y kubelet-1.22.1 kubeadm-1.22.1 kubectl-1.22.1 —disableexcludes=kubernetes
开机启动
➜ systemctl enable —now kubelet
我这里是这个版本Kubernetes v1.22.1
➜ kubelet —version
<a name="ITPut"></a>### 8. master节点初始化<a name="yyy2x"></a>#### 1. kubeadm init执行过程方法一:之前我是安装了clash代理,此模式下无法正常下载相关镜像```bash➜ kubeadm init --pod-network-cidr=10.244.0.0/16
方法二:取代上面方法,逐行执行
所需镜像➜ kubeadm config images list --config kubeadm-init-config.yaml拉起对应所需镜像➜ kubeadm config images pull --config=kubeadm-init-config.yaml初始化Master节点,会在 /etc/kubernetes/manifests 生成 etcd、kube-apiserver、kube-controller-manager、kube-scheduler.yaml➜ kubeadm init --config=kubeadm-init-config.yaml --upload-certs
kubeadm-init-config.yaml文件:值得一提的就是这个 podSubnet 网络必须和我们下面flannel部署 flannel.yaml net-conf.json 的ip一致。也就是说 /etc/kubernetes/manifests/kube-controller-manager.yaml 中确保commond中的为:
- —cluster-cidr=10.244.0.0/16
- —allocate-node-cidrs=true
apiVersion: kubeadm.k8s.io/v1beta2kind: ClusterConfigurationkubernetesVersion: v1.22.1imageRepository: registry.aliyuncs.com/google_containerscontrolPlaneEndpoint: "10.10.10.111:6443"networking:serviceSubnet: "10.96.0.0/16"podSubnet: "10.244.0.0/16"dnsDomain: "cluster.local"dns:type: CoreDNSimageRepository: swr.cn-east-2.myhuaweicloud.com/corednsimageTag: 1.8.0---apiVersion: kubelet.config.k8s.io/v1beta1kind: KubeletConfigurationcgroupDriver: systemd
2. 配置 kubectl
初始化master节点结束后,配置kubectl,生成对应config文件
➜ rm -rf /root/.kube/➜ mkdir -p $HOME/.kube➜ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config➜ sudo chown $(id -u):$(id -g) $HOME/.kube/config
3. 检查master节点初始化结果
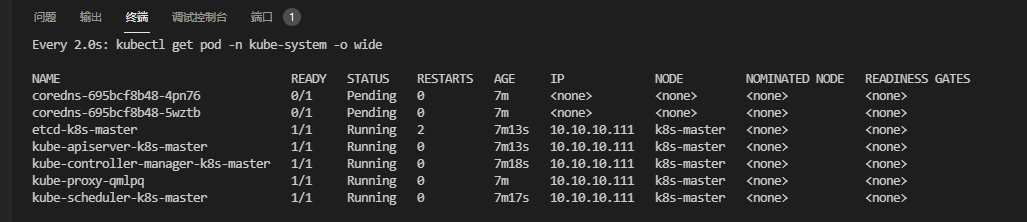
查看 master 节点初始化结果,发现两个coredns的pod处于准备状态,是因为需要部署网络组件
➜ watch kubectl get pod -n kube-system -o wide
➜ kubectl get nodes -o wide

9. 部署网络组件
如果您在阿里云上安装 K8S,建议使用 flannel,有多个案例表明 calico 与阿里云存在兼容性问题。我这里以安装flannel为例子,部署此组件的kind: DaemonSets,意味着我们加入的worker节点也会自动部署kube-flannel-ds,第十步说明如何加入master。当然这一步也可以放到node节点join到master执行也可
➜ curl -O https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml➜ kubectl apply -f ./kube-flannel.yml
10. 状态查看
1. 查看各个组件状态
➜ kubectl get cs

出现这种情况,是/etc/kubernetes/manifests 下的 kube-controller-manager.yaml 和 kube-scheduler.yaml 设置的默认端口是 0,在文件中注释掉就可以了 #port=0,(然后再master节点上重启下kubelet,systemctl restart kubelet.service,我这里没重启也ok,不过这种情况不影响我们使用
2. 查看节点状态
➜ kubectl get nodes -o wide

3. 查看 pod 状态
➜ kubectl get pods --all-namespaces -o wide

11. 添加从节点
# 在master节点执行,获取对应可获取kubeadm join 命令及参数,
➜ kubeadm token create --print-join-command
# 在worker节点执行,如果你之前使用移除节点是delete 执行:systemctl restart kubelet
kubeadm join 192.168.1.148:6443 --token nzdj3s.hsknby9urpz0386n --discovery-token-ca-cert-hash sha256:dfaf08c19c26dee6b0da18da992ad18c14b9330eab5de1d5eceaec103b9cebf4
12. 移除从节点
➜ kubectl drain node1
➜ kubectl delete node1
cordon,drain,delete 此三个命令都会使node停止被调度,后期创建的pod不会继续被调度到该节点上,但操作的暴力程度不一
cordon(停止调度)
停止调度,影响最小,只会将node调为SchedulingDisabled,之后再发创建pod,不会被调度到该节点
旧有的pod不会受到影响,仍正常对外提供服务。恢复调度kubectl uncordon <node_name>
drain(停止调度+删除该节点pod)
驱逐node上的pod,返回成功表明所有的 pod (除了前面排除的那些)已经被安全驱逐。其它节点重新创建。接着,将node节点调为 SchedulingDisabled
delete(停止调度+删除该节点pod+重启kubelet)
delete是一个比较粗暴的命令,它会将被删node上的pod直接驱逐,由其他node创建(针对replicaset),然后将被删节点从master管理范围内移除,master对其失去管理控制,若想使node重归麾下,必须在node节点重启kubelet `systemctl restart kubelet`
部署过程异常问题总结
1. docker安装方式可能出现的异常(非docker安装略过)
因为我之前机器上安装了docker,所以一开始我安装的话容器默认用的是docker,期间出现了一些异常:(健康检查不通过)
按照上面提示journalctl -xeu kubelet查看日志,或者tail /var/log/messages
发现kubelet的cgroup driver是systemd,docker的 cgroup driver是cgroupfs,两者不一致导致kubelet启动失败。当然如你不安装docker则不会出现上述问题,这里也不推荐安装docker。
修改docker的cgroup dirver设置,打开文件 /usr/lib/systemd/system/docker.service,如下图,将红框中的systemd改为cgroupfs:追加:--exec-opt native.cgroupdriver=systemd
重启docker配置: systemctl daemon-reload && systemctl restart docker,但是发现端口又被占用了所以需重启一下kubeadm就可以了: kubeadm reset -f,最终如愿以偿初始化成功。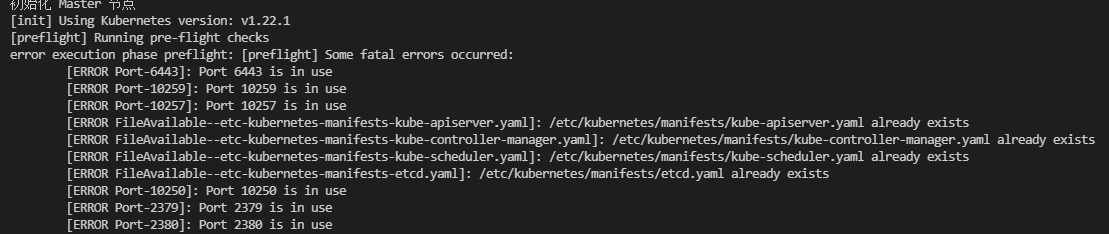

2. 部署flannel组件异常(Kubernetes node节点无法访问ClusterIP)
我们在部署master是可以正常部署的,但是在我们node节点加入后,pod会新生成两个,一个是kube-proxy另外一个就是kube-flannel-ds这两个类型都是DaemondSets所以自动加入到node节点。但是node节点去无法正常生产kube-flannel-ds的pod,报错信息如下:worker节点中的pod无法连接到内部k8s api服务10.0.0.1:443,甚至在worker节点中运行curl也无法连接到 10.0.0.1:443
Failed to create SubnetManager: error retrieving pod spec for 'kube-system/kube-flannel-ds-gs6kv': Get "https://10.96.0.1:443/api/v1/namespaces/kube-system/pods/kube-flannel-ds-gs6kv": dial tcp 10.96.0.1:443: i/o timeout

解决参考:https://www.91the.top/k8s/kubernetes-probelem.html
https://cloud.tencent.com/developer/article/1553536
3. 子节点不支持kubectl get node
出现这个问题的原因是kubectl命令需要使用kubernetes-admin来运行,解决方法如下,将主节点中的【/etc/kubernetes/admin.conf】文件拷贝到从节点相同目录下,在执行一遍即可。
The connection to the server localhost:8080 was refused - did you specify the right host or port?
4. 节点内存不足,正在运行的pod惨遭驱逐
0/1 nodes are available: 1 node(s) had taint {node.kubernetes.io/disk-pressure: }, that the pod didn't tolerate.
当某种条件为真时,节点控制器会自动给节点添加一个污点。当前内置的污点包括:
- node.kubernetes.io/not-ready:节点未准备好。这相当于节点状态 Ready 的值为 “False”。
- node.kubernetes.io/unreachable:节点控制器访问不到节点. 这相当于节点状态 Ready 的值为 “Unknown”。
- node.kubernetes.io/memory-pressure:节点存在内存压力。
- node.kubernetes.io/disk-pressure:节点存在磁盘压力。
- node.kubernetes.io/pid-pressure: 节点的 PID 压力。
- node.kubernetes.io/network-unavailable:节点网络不可用。
- node.kubernetes.io/unschedulable: 节点不可调度。
- node.cloudprovider.kubernetes.io/uninitialized:如果 kubelet 启动时指定了一个 “外部” 云平台驱动, 它将给当前节点添加一个污点将其标志为不可用。在 cloud-controller-manager 的一个控制器初始化这个节点后,kubelet 将删除这个污点。
如果你想查看某个节点是否存在那些污点可以使用如下命令:
➜ kubectl describe node master
Name: master
Roles: master
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/hostname=master
node-role.kubernetes.io/master=
......
Taints: node.kubernetes.io/disk-pressure
Unschedulable: false
......
在节点被驱逐时,节点控制器或者 kubelet 会添加带有 NoExecute 效应的相关污点。 如果异常状态恢复正常,kubelet 或节点控制器能够移除相关的污点。所以此时你部署pod很可能就部署不上去。
污点与忍受度文章可以参考我的下一篇文章:地址
值得一提就是k8>1.8版本后增加了限制容器存储空间的使用;对于容器资源隔离来说,非常有用,万一应用程序失控,写大量日志把node空间写满,影响就大了。
- Docker的 Root Dir: 默认(/var/lib/docker)
- kubelet的root-dir: 默认(/var/lib/kubelet)
ephemeral-storage引发的pod驱逐问题参考这篇文章:文章地址
5. master节点无法部署pod
如果你想单机部署,并且希望master节点可以部署所有东西,会发现pod无法部署上去,会有提示信息:
因为Master 节点默认保留给 Kubernetes 系统组件使用,通过执行1 node(s) had taints that the pod didn't tolerate:kubectl describe node master,可以发现我们的master节点上实际上是存在污点的。pod 不会再被调度到 taint 标记过的节点。我们使用kubeadm搭建的集群默认就给 master 节点添加了一个污点标记,所以我们看到我们平时的 pod 都没有被调度到 master 上去。如果你想部署pod上去去除这个污点就行了或者添加可以忍受此污点的pod。➜ kubectl taint nodes --all node-role.kubernetes.io/master-apiVersion: apps/v1beta1 kind: Deployment metadata: name: taint labels: app: taint spec: replicas: 3 revisionHistoryLimit: 10 template: metadata: labels: app: taint spec: containers: - name: nginx image: nginx ports: - name: http containerPort: 80 tolerations: - key: "node-role.kubernetes.io/master" operator: "Exists" effect: "NoSchedule"lens添加对应集群
点击lens左上第一个菜单File其中的add cluster,将我们/root/.kube文件夹中的config文件添加进去,然后进行访问,当然前提是你本地lens必须能够ping通对应的host,其次是选中对应的集群节点,右击点击setting点击开启按钮,来收集集群的各项信息。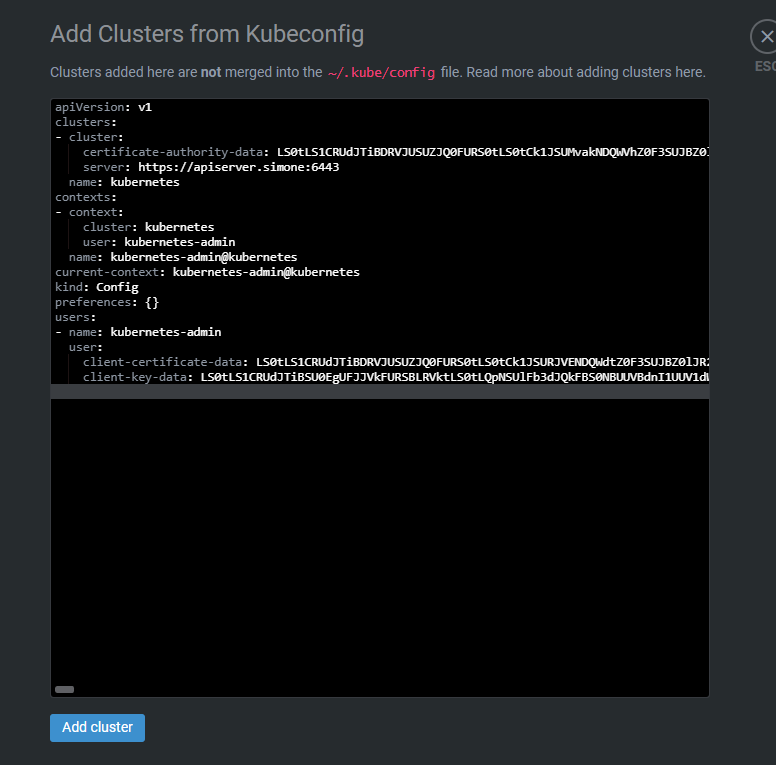

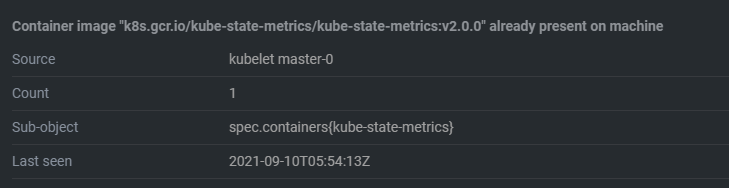
此时它会从下载三个插件来收集集群信息的报表信息,不过值得一提的就是其中有个pod(kube-state-metrics)是从外网下载的, k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0 ,如果没有外网的朋友建议使用dockhub的镜像,因为已经有人从谷歌那里下载下来了,然后你自己打个tag就行。当你对应pod起来后,点进去会发现并未从新拉取pod因为你的策略模式是:imagePullPolicy: IfNotPresent,所以默认是从自己本身容器中拉取对应的镜像。➜ docker pull rewind/kube-state-metrics:v2.0.0 ➜ docker tag rewind/kube-state-metrics:v2.0.0 k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0 ###➜ docker rmi -f rewind

参考链接
文档参考:https://www.qikqiak.com/k8s-book/docs 部署参考:https://kuboard.cn/install/install-k8s.html

若有收获,就点个赞吧
0 人点赞
