- 文件的查找
- 用which 查找软件安装位置
- which ascp
- 启动环境
- conda activate rna
- 退出环境
- conda deactivate
- 列出已存在的环境
- conda env list
- conda info —env
- 删除已创建的小环境及安装的包
- conda remove -n rna —all
- 安装软件
- conda install fastqc
- 多个软件可以一起安装
- conda install -y multiqc fastp
- 查看conda环境中已安装的软件
- conda list
- 1.查看符合正则表达式的软件
- conda list fast*
- 2.查看指定的环境的软件
- conda list -n rna
- 删除软件
- conda remove fastqc
- conda remove -n rna fastqc
- 升级软件
- conda update fastqc
- 环境变量
- • 文件系统结构:
- 自定义变量
- 状态变量:
- echo $?
- 位置参数变量:
- $n
- $0 代表命令本身,
- $1~$9 代表第 1~9 个参数,
- 结构化语句
- if 条件语句的常见条件:
- 实际用法:
- 数值判断
- 文件判断
- for循环语句的常见格式:
- biosoft database file2 file5 file8 filereport_read_run_PRJNA229998_tsv.txt #project
- data file1 file3 file6 file9 miniconda3 #readme.txt
- Data file10 file4 file7 file{i..10} Miniconda3-latest-Linux-x86_64.sh
- while循环语句的常见格式:
- 1.生成连续文件
- 2.将结尾的.sra替换成.fastq
- 查看变量长度
- echo ${#id}
- Shell 脚本
- 任务提交:
文件的查找

用find查找当前目录带有fq结尾的文件
find ./ -name ‘*fq’
用which 查找软件安装位置
which ascp
结果:/trainee2/Apr14/miniconda3/envs/rna/bin/ascp
启动环境
conda activate rna
退出环境
conda deactivate
列出已存在的环境
conda env list
conda info —env
删除已创建的小环境及安装的包
conda remove -n rna —all
安装软件
conda install fastqc
多个软件可以一起安装
conda install -y multiqc fastp
查看conda环境中已安装的软件
conda list
1.查看符合正则表达式的软件
conda list fast*
2.查看指定的环境的软件
conda list -n rna
删除软件
conda remove fastqc
conda remove -n rna fastqc
不指定-n参数就得进入该环境之后才能进行删除操作
同样,-y能够跳过确认执行的步骤
升级软件
conda update fastqc
环境变量
常见环境变量:
• $HOME:当前用户的主目录
• $PATH:shell查找命令的目录列表由,冒号(:)分隔
• $SHELL:bash shell的全路径名
• $LOGNAME:当前用户的登录名
(echo $HOME)
• echo
echo $PATH | tr ‘:’ ‘\n’

• 文件系统结构:
/ 虚拟目录的根目录。通常不会在这里存储文件
/bin 二进制目录,存放许多用户级的GNU工具
/boot 启动目录,存放启动文件
/dev 设备目录,Linux在这里创建设备节点
/etc 系统配置文件目录
/home 主目录,Linux在这里创建用户目录
/lib 库目录,存放系统和应用程序的库文件
/media 媒体目录,可移动媒体设备的常用挂载点
/root root 用户的主目录
/sbin 系统二进制目录,存放许多GNU管理员级工具
/run 运行目录,存放系统运作时的运行时数据
/tmp 临时目录,可以在该目录中创建和删除临时工作文件
/usr 用户二进制目录,大量用户级的GNU工具和数据文件都存储在这里
lscpu 查看CPU信息
free -h 查看内存信息
df -h 查看硬盘信息
du -h -d 1 查看文件大小
du -sh ~ 查看文件大小
top 查看系统进程
ps -ef | grep “$LOGNAME” 查看系统进程
htop
![4XK%B_UAXB]`)A0ZUMQ$S2E.png](/uploads/projects/huluobu-fpy9r@dg3o3m/1181dfed9dabc6d36674d4e0791b517c.png)
自定义变量
双引号:变量被解释
![_DZV$)_F0BO2VWGI5O416Q.png
打印bin目录带sh结尾的文件
ls /bin/*sh
意思是把bin目录下的所有以sh结尾的文件都打印出来
![$G7W0XFKPGOSD$_5D$HNHJ.png
状态变量:
echo $?
获取执行上一个指令的执行状态返回值,返回0表示
上一个命令或者程序执行成功,返回的值为非0则表
示上一个命令执行失败。
位置参数变量:
$n
$0 代表命令本身,
$1~$9 代表第 1~9 个参数,
结构化语句
if 条件语句的常见格式:
if [ 1 -eq 1 ]
echo “welcome to biotrainee”
else
echo “###”
fi
![7QEC0@%A~C%$NQWO7UN3_S.png
if 条件语句的常见条件:
-eq
[ INT1 -eq INT2 ] INT1 和 INT2 两数相等返回为真
-ne
[ INT1 -ne INT2 ] INT1 和 INT2 两数不等返回为真
-gt
[ INT1 -gt INT2 ] INT1 大于 INT2 返回为真
-ge
[ INT1 -ge INT2 ] INT1 大于等于 INT2 返回为真
-lt
[ INT1 -lt INT2 ] INT1 小于 INT2 返回为真
-le
[ INT1 -le INT2 ] INT1 小于等于 INT2 返回为真
实际用法:
数值判断
$if [ 1 -eq 1 ]thenecho "welcome to biotrainee"elseecho "###"fi# welcome to biotrainee
$ if [ $? -eq 0 ]thentouch ok.txtfi# (rna) Apr14 13:21:47 ~$ ls#biosoft database Miniconda3-latest-Linux-x86_64.sh project#data filereport_read_run_PRJNA229998_tsv.txt myDir #readme.txt#Data miniconda3 ok.txt文件判断
[ -a FILE ] 如果 FILE 存在则为真
[ -d FILE ] 如果 FILE 存在且是一个目录则返回为真
[ -f FILE ] 如果 FILE 存在且是一个普通文件则返回为真
$ if [ -f readme.txt ];then echo "jojo";fi#jojofor循环语句的常见格式:
![F[EWH4DV2_PEF840{X$FAK.png
$ for i in {1..5}doecho ${i} "Hi!"sleep 3sdone#1 Hi!#2 Hi!#3 Hi!#4 Hi!#5 Hi!用循环创建多个文件
for i in {1..10};do touch file${i};done
```shell $ for i in {1..10};do touch file${i};done
$ ls
biosoft database file2 file5 file8 filereport_read_run_PRJNA229998_tsv.txt #project
data file1 file3 file6 file9 miniconda3 #readme.txt
Data file10 file4 file7 file{i..10} Miniconda3-latest-Linux-x86_64.sh
用vim编辑出一个含有for i in {50..60};doecho ${i};done内容的文件,保存并退出。然后bash这个文件,就可以直接运行文件里面的内容,可以使用cat查看。<a name="cPlUm"></a>### 读取.sh文件<a name="Rr2Pz"></a>### bash file.sh```shell$ bash touch.sh#50#51#52#53#54#55#56#57#58#59#60$ cat touch.shfor i in {50..60}doecho ${i}done
![X]UXZ%(DH4O]R}KAOW38M`C.png](/uploads/projects/huluobu-fpy9r@dg3o3m/f279a57614ef27ceca8c139321cee71a.png)
for循环语句的常见格式:
$ list="CDS exon gene start_codon stop_codon transcript UTR"$ for i in ${list}> do> echo "this feature is ${i}"> done#this feature is CDS#this feature is exon#this feature is gene#this feature is start_codon#this feature is stop_codon#this feature is transcript#this feature is UTR
ls file*
用 for循环 把文件的后缀增加一个.txt
(因为{i}.txt不存在,用mv的话,把一个文件mv称不存在的文件,相当于重命名)
$ for i in `ls touch.sh`>do mv ${i} ${i}.txt>done$ ls#biosoft database Miniconda3-latest-Linux-x86_64.sh #touch.sh.txt#data filereport_read_run_PRJNA229998_tsv.txt project#Data miniconda3 readme.txt
while循环语句的常见格式:

用 while循环 把文件的后缀加一个.txt
$ ls touch.sh.txt | while read id> do> mv ${id} ${id}.txt> done$ ls#biosoft filereport_read_run_PRJNA229998_tsv.txt readme.txt#data miniconda3 touch.sh.txt.txt
把文件输出到config中
$ ls touch.sh.txt.txt > config$ cat config#touch.sh.txt.txt
移除文件id的txt
因为刚才加了两次txt,所以移除一次后还剩一个
$ cat config | while read id> do> mv ${id} ${id%.txt}> done$ ls#biosoft Data miniconda3 #readme.txt#config database Miniconda3-latest-Linux-x86_64.sh #touch.sh.txt
掐头去尾
${变量#关键字}
若变量内容从头开始的数据符合“关键字”,则将符 合的最短数据删除
${变量##关键字}
若变量内容从头开始的数据符合“关键字”,则将符 合的最长数据删除
${变量%关键字}
若变量内容从尾开始的数据符合“关键字”,则将符 合的最短数据删除
${变量%%关键字}
若变量内容从尾开始的数据符合“关键字”,则将符 合的最长数据删除
$ id=example.test.fq$ echo $id#example.test.fq#####从头到最后,去掉第一个点号前面的所有内容 *.代表点前面所有内容$ echo ${id#*.}#test.fq#########也可以直接指定删除哪一个字符$ echo ${id##example.}#test.fq#######从头开始,去掉最后一个点前面的所有内容$ echo ${id##*.}#fq#####从后往前,删除第一个.前面的内容$ echo ${id%.*}#example.test######从后往前,删除最后一个.前面的内容$ echo ${id%%.*}#example
1.生成连续文件
2.将结尾的.sra替换成.fastq
第一种方法:
#############1.生成SRR1234501.sra到SRR1234510.sra这10个id$ for i in {01..10};do touch SRR12345${i}.sra;done$ ls#biosoft filereport_read_run_PRJNA229998_tsv.txt readme.txt SRR1234504.sra #SRR1234508.sra#data miniconda3 SRR1234501.sra SRR1234505.sra #SRR1234509.sra#Data Miniconda3-latest-Linux-x86_64.sh SRR1234502.sra SRR1234506.sra #SRR1234510.sra#database project SRR1234503.sra SRR1234507.sra#################2.将结尾的.sra替换成.fastq$ ls SRR12345* | while read id> do> sed 's/.sra/.fastq/g'> done#SRR1234502.fastq#SRR1234503.fastq#SRR1234504.fastq#SRR1234505.fastq#SRR1234506.fastq#SRR1234507.fastq#SRR1234508.fastq#SRR1234509.fastq#SRR1234510.fastq
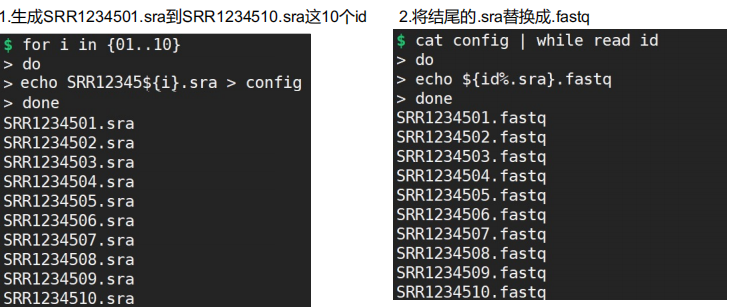
第二种方法:
$ for i in {01..10}> do> echo SRR12345${i}.sra >> config> done$ cat configSRR1234510.sraSRR1234501.sraSRR1234502.sraSRR1234503.sraSRR1234504.sraSRR1234505.sraSRR1234506.sraSRR1234507.sraSRR1234508.sraSRR1234509.sraSRR1234510.sra$ cat config | while read id> do> echo ${id%.sra}.fastq> doneSRR1234510.fastqSRR1234501.fastqSRR1234502.fastqSRR1234503.fastqSRR1234504.fastqSRR1234505.fastqSRR1234506.fastqSRR1234507.fastqSRR1234508.fastqSRR1234509.fastqSRR1234510.fastq
查看变量长度
echo ${#id}
1、修改变量的字符串
echo ${id/test/1}
${变量/旧字符串/新字符串}
把变量id里面的第一个test替换为1
![YYJ0OSDIF@]$W]LI8XOGQLX.png](/uploads/projects/huluobu-fpy9r@dg3o3m/df5458d584bef8bbe618d94fffc7cfd3.png)
标准模式
![K}YLA2CO1M`)0AANTBHT7G.png
1: 标准输出流
2:标准误输出流
用vim编辑器脚本写一句Welcome to Biotrainee()!,用bash命令运行.sh结尾的脚本,然后显示。
我们可以用bash命令运行脚本的同时,把结果输出,正确的结果1输出到test.log文件中,然后把2中的错误也输出到1中,也就是正确结果和错误结果同时存在test.sh中。
$ bash test.sh# Welcome to Biotrainee()!$ bash test.sh 1>test.log 2>&1$ cat test.log# Welcome to Biotrainee()!
![L]9WK%~XW(FBMJ%RBW`3}0X.png](/uploads/projects/huluobu-fpy9r@dg3o3m/ebff050b2f3f4138189dd84554deb152.png)
创建一个新的脚本test1.sh$ vim test1.sh$ cat test1.shpwdpwdppp###运行脚本$ bash test1.sh#/trainee2/Apr14#/trainee2/Apr14#test1.sh: line 3: ppp: command not found###2.进行重定向,但不指定标准输出和标准误输出。正确的在out.log中,错误的输出到标准输出流(屏幕)$ bash test1.sh > out.log#test1.sh: line 3: ppp: command not found$ cat out.log#/trainee2/Apr14#/trainee2/Apr14###3.进行分开重定向,正确与错误分别进入两个log文件$ bash test1.sh 1> out.log 2> error.log$ cat out.log#/trainee2/Apr14#/trainee2/Apr14$ cat error.log#test1.sh: line 3: ppp: command not found###4.进行分开重定向,将2输出到1中,两者都输出到out.log$ bash test1.sh 1>out.log 2>&1$ cat out.log#/trainee2/Apr14#/trainee2/Apr14#test1.sh: line 3: ppp: command not found$ ls#biosoft Data filereport_read_run_PRJNA229998_tsv.txt out.log test1.sh#config database miniconda3 project test.log#data error.log Miniconda3-latest-Linux-x86_64.sh readme.txt test.sh
chmod 修改shell脚本的文件权限
![JY@LEH_S_O]5`GJ`AP)0SCU.png](/uploads/projects/huluobu-fpy9r@dg3o3m/017afb7db6020f3ed3b4c06d00b259e9.png)
shell脚本参数传递
首先建立一个脚本test3.sh,内容是cat $1,代表展开第一个参数。
bash test3.sh readme.txt 意思是把test3.sh里面的脚本传递给readme.txt这个第一个参数
命令传递一个参数
$ cat test3.sh# #!/bin/bash# cat $1$ bash test3.sh readme.txt#Welcome to Biotrainee() !#This is your personal account in our Cloud.#Have a fun with it.#Please feel free to contact with me( email to jmzeng1314@163.com )#(http://www.biotrainee.com/thread-1376-1-1.html)
命令传递多个参数
首先创建一个脚本,内容为cat $0 cat $1 cat $2,意思是打开文件本身test4.sh,打开第一个参数out.log,打开第二个参数error.log。
$ vim test4.sh$ cat test4.sh#!/bin/bashcat $0cat $1cat $2$ bash test4.sh out.log error.log#!/bin/bashcat $0cat $1cat $2/trainee2/Apr14/trainee2/Apr14test1.sh: line 3: ppp: command not foundtest1.sh: line 3: ppp: command not found
任务提交:
![WS9$]4Q8Q4C9($CPG7B}WWT.png](/uploads/projects/huluobu-fpy9r@dg3o3m/846d24709056486bc8ce9e9b50ac6cd5.png)
• tail -f sleep.out 动态查看运行结果输出
运行脚本,可以另开窗口利用tail -f sleep.out来打开sleep.out文件查看动态运行结果输出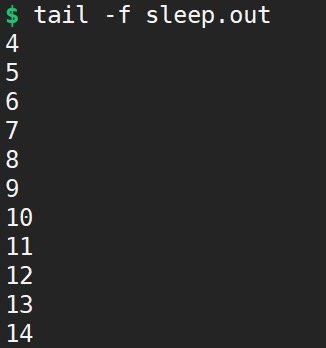
• nohup :不要挂断任务,即把任务提交到服务器上运行
nohup bash sleep.sh &

& :任务后台运行,通常与 nohup 连用
• top :实时显示系统中各个进程的资源占用状况,按 q 退出
top -u Apr14
htop -u Apr14
• ps :Process Status列出进程列表
ps -ef | grep “$LOGNAME”(可查看任务编号)
![HVHY$MW`0ZABO5C2%H]44E9.png](/uploads/projects/huluobu-fpy9r@dg3o3m/b3695156169393c0abc407e746232357.png)
• kill :杀掉进程,kill PID
kill -9 30872
kill -9,然后 加上任务的编号,就可以停止任务,-9意思是杀的彻底一点
(任务编号可以用方法二的命令来查找)
方法二
利用htop -u Apr14命令打开运行进程,找到想要停止的命令并把光标点在命令行让它变蓝,然后点击下方的kill,选择左边栏的9,按回车键,就可以停止任务。

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}