线程IO模型
单线程
这里的单线程程序,是指主要工作线程,他完成了redis的最核心的功能。
内存级别的运算
采用非阻塞IO
读写套接字不会被阻塞,套接字对象Non_Blocking 选项能使读写尽情!此时限制是内核为读写缓冲区分配的字节数
事件轮询(多路复用)
这是一个很经典很经典的概念,node,vertx,nginx等高性能语言/程序都使用事件轮询。
简单概括,线程有个死循环。这个死循环不断循环去查询有什么事情要做了,有什么事情做完了。事件循环API是系统提供的select/epoll(linux)/kqueue(freebsd & macosx),不同操作系统实现方式不一但本质相似。
指令队列和响应队列
Redis 为每个客户端连接提供一个指令队列和一个响应队列。客户端指令在指令队列排队处理,先到先得。响应队列顾名思义,存放处理结果,当响应队列中数据为空,事件循环不会去处理此客户端的写事件。直到响应队列有数据。
定时任务
通信协议

持久化
内存数据终究是内存数据,重启,宕机等因素使之消散。如果在不影响性能的前提下,将内存持久化是一个问题。使用快照和AOF 能一定程度的达到这个目标,但。。。
快照
“快照是不是啪的一下,将redis实例的内存数据写入磁盘文件中?”
快照其实frok()了一个进程才完成快照,redis实例内存占用的组成部分主要是代码段和数据段。他们被系统分成多干数据页。
fork()时,子进程与工作进程在fork的瞬间共享那时的数据页。利用系统COW(Copy On Write)机制,当工作进程接收修改数据的指令时,被修改的数据页会被复制分离一份,然后在此数据页基础进行修改,这样子进程看到的数据依然是fork瞬间看到的数据。
之后,子进程读取内存的数据也不会影响工作进程。
“数据页复制分离太多是不是内存翻倍?”
如果内存中热数据太多确实可能出现近似出现这样的问题,但是redis一般业务中,冷数据比较多吧。
AOF
“AOF追加的修改指令过多怎么办?”
AOF通过保存对数据的修改指令,等到redis 实例重启时,执行AOF中的命令来达到恢复数据的效果.当然这样随着操作越来越多,AOF指令越来越多.
通过”瘦身”操作可以减少保存的指令,还是fork子进程,根据redis实例内存数据重新生成一批指令存入新的指令文件中,期间接收到的指令追加到新文件中.完成瘦身替换.
“指令未被刷入磁盘,redis就宕机了怎么办?”
修改指令被redis实例处理,先会写入AOF文件中,然后才会被执行.
其中写入文件,实际是先写入系统为AOF文件分配的内存缓冲,随后系统内核将内存缓冲数据异步刷盘到AOF文件中(这里决定刷盘的是系统),这里很容易出现宕机,指令丢失的情况. 而系统提供fsync(fd),可以让我们强制将内存缓冲数据刷盘,就是性能比较低下.
“AOF和快照都不算完美,有没有其他方法?”
首先列举一下AOF和快照的缺点:
- 快照创建子进程,读取redis大块内存,并且大块刷盘,消耗系统资源大,在寸土必争的服务器,决定其不能频繁使用,而这也意味着宕机重启使用快照回溯数据会损失很多数据,因为其只保留了最近一次快照的数据,之后的数据因为没有快照而丢失
- AOF ,问题在于是系统决定将指令缓冲刷盘还是使用fsync强制刷盘?系统决定,这就很随机了.可能数据会丢失比较多.使用fsync,性能消耗比较巨大.
“那么有什么补救方法吗?”
主从了解一下! AOF 和快照主要是性能,数据丢失问题, 如果保证主从数据能最终同步的情况,让从数据进行备份操作,主数据专心提供服务,情况会好很多,当然一主一从的模式,当从节点宕机或者网络原因就会使主从能力大打折扣,建议多个从节点,保证可用。
4.0 混合持久化
快照会丢失数据,AOF 慢。redis4.0推出快照+AOF 的模式,即开启快照到快照结束的时间段内增量指令使用AOF保存,将快照(RDB)文件内容和AOF文件存储一起。这样开启快照不会丢失大量数据,载入速度也会大大加快
管道
由客户端提供的功能。其实就是一次请求含有多个指令,指令的读写都要经过内核分配的缓冲区。
在官网对于管道的的介绍是一般“blocking way”的链接,指令的下发需要经过“来回来回来回。。。”的RTT.
管道则是将指令以“来来来来来回”的方式,使得下个指令不需要等待上一个指令操作结果返回即可发送。于此同时,服务端保存了此次管道中多指令的返回结果,所以单次管道指令不要太多否则redis实例内存占用太多。所以我并不认为是书上所说“客户端提供的能力”。
这里需要着重“blocking way”,或许管道对于 不同的并发模型语言 犹如鸡肋;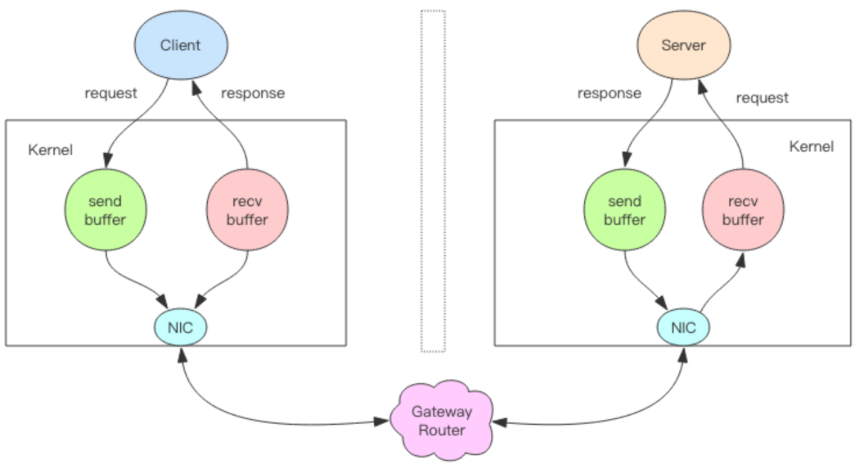
事务
关系型数据库提供事务,并定义事务的四大属性(ACID),原子,一致,隔离,持久。redis的事务是不是也是这样的?
一般事务都有begin,commit,rollback等流程,而redis的事务流程是multi,exec,discard.
multi声明事务的开始,后续指令发送至服务器,并缓存至事务队列中,直到接受exec命令,才开始执行事务队列中的命令。
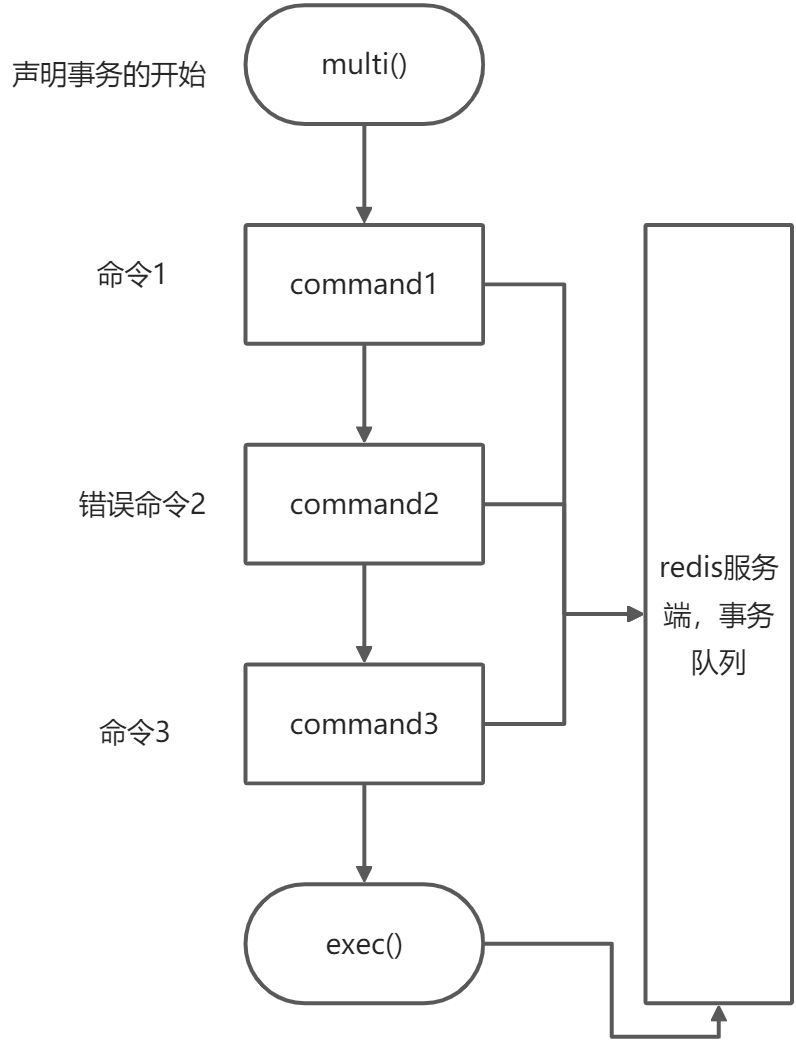
原子性
如图所示,当对执行exec()时,错误命令2并不会阻止命令3的执行,也不会回滚命令1.这并不满足原子性,只是保证当前执行的事务有着不会被其他事务打断。
一般来说事务都伴随着多个命令,使用管道pipeline能有效减少命令的网络io提高性能。
watch
乐观锁watch 解决变量并发问题。如下图,watch 变量1,如果并发存在其他客户端或者线程操作了变量1,那么意味着当前客户端事务操作会执行失败,保证变量1同时有且仅有一个客户端能操作变量1。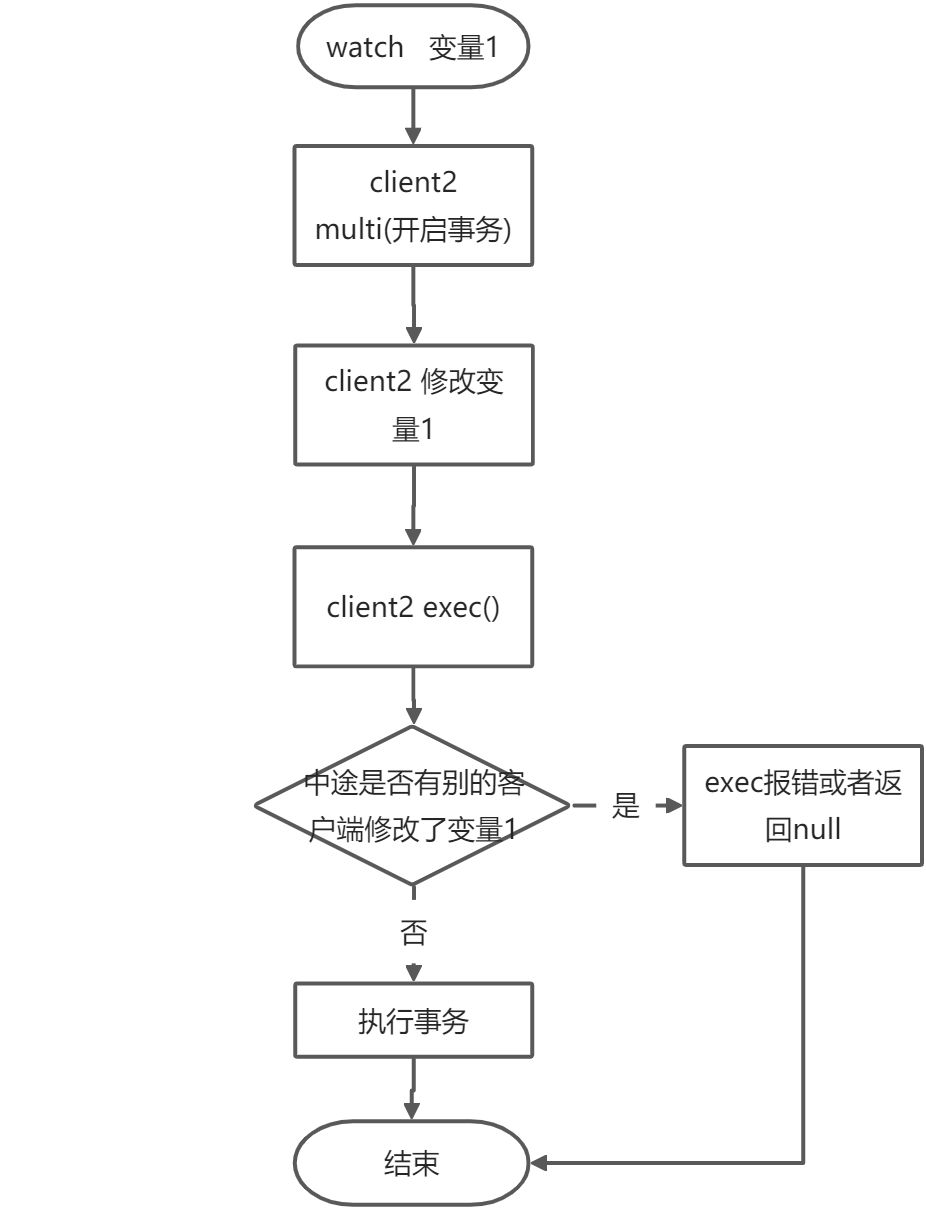
发布订阅(pubSub)
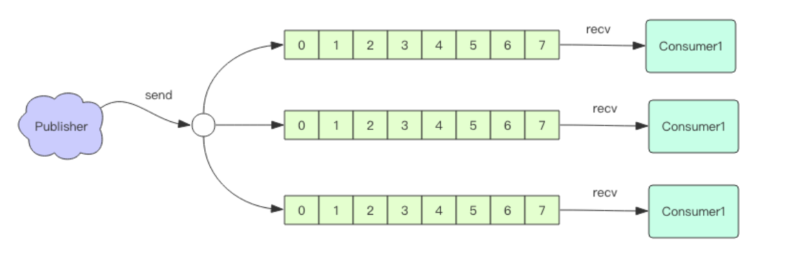
订阅(sub)某个频道的客户端们会接收到向此频道发布(pub)的消息,其有以下特点:
- 一份消息能被多个订阅者消费
- 订阅者能同时订阅多个频道(或者某种匹配规则的频道)
- 如果订阅者连接断开后重连,断开期间,消息会丢失,并不会重发来进行“补救”
- 如果没有订阅者,那么消息发布即丢失了。这意味着需要先启动消费者再启动生产发布者
- 消息不支持持久化!!!!!
stream
PubSub不能进行消息持久化,实在是很遗憾。不过5.0版本推出stream数据结构,帮助redis持久化消息队列
内存
32bit 编译与64位编译
redis 采用32bit 编译 能减少数据的指针空间,节省内存
小对象压缩存储
数据量小的集合,采用紧凑式存储,如果数据变大,则会变成常规数据结构
内存回收机制
操作系统回收内存以数据页为单位,redis数据分散于数据页中。也就是说,当redis的key被删除的时候,数据页还有其他数据,系统也就不会立即回收内存空间,当然如果flashdb,直接把所有数据都删除,则会立即回收。
数据删除之后,虽然内存空间可能不会被立即回收,但是后续还能被使用,只是没有归还系统罢了。
内存分配算法
redis使用第三方内存分配库来划分内存页。jemalloc和tcmalloc两种分配库。使用info memory查看使用的分配库版本
主从同步
分布式理论-CAP原理
- C ,一致性
- A,可用性
- P,分区容忍性
增量同步
Redis 主节点同步的式指令,主节点将修改性的指令记录在内存buffer中,然后异步将buffer同步至从节点,那么意味着一致性不能保证。
但是在网络情况良好的时候,能做到最终一致性,即从节点会最终将数据同步。
从节点同步指令流时会反馈主节点同步位置(偏移量),主节点存储指令buffer内存是有限的,如果主从网络断开,那么记录指令的内存buffer 就会被装满!这时候,后来的指令会覆盖已存在的内存buffer,最终导致从节点和主节点数据不一致!!!!!快照同步
新的从节点加入集群,需要进行一次快照同步,同步完成之后进行增量同步。
增量同步可能会出现,内存buffer不够,指令被覆盖的情况,使用快照同步能纠正数据错误。
首先,主节点执行一次bgsave.将内存数据全部加载至磁盘文件(耗性能),然后再将快照文件传送至从节点,从节点接收文件,会清空自己的内存数据,然后根据快照文件做一次全量加载,这期间的增量指令在完成快照同步之后通过增量同步的方式,加载至从节点。。
这里只解决网络断开,从节点重新连接的问题,但是在快照同步时,增量指令还是过于庞大,主从节点在快照同步完成之后,指令数据丢失,导致又需要开启快照同步。。。死循环了(#`O′)!!
无盘复制(2.8.18)
在执行快照同步时,需要完成一次bgsave.这可能会十分影响主节点工作性能。而无盘复制,则省略这个步骤,而将快照内容通过套接字发送至从节点。而从节点和之前一样,下载快照数据,清空内存数据,全量加载
wait
redis 数据同步复制时,采用异步的形式,确保网络良好的情况下,能做到“最终一致性”,wait 指令能确保数据同步至其他从节点。
假设目前一主二从节点,执行 “wait 2 1”,即等待两个从节点同步完数据,最多等待1ms; 如果时“wait 2 0”则表示一直等待从库完成同步。这时候恰巧一个从节点一直宕机,那么wait 会一直等下去,等下去,服务也不能用了!!!!
集群
版本协议问题
2018 年之后的redis 协议有做修改,大公司使用需注意
工作上的问题?
运维和开发,关于3主3从集群,一个主节点宕机,从节点会不会上位主节点?
在工作中,我司开发和运维搭建了一个3主3从的redis集群.其中一台主redis宕机,而相应的从节点却没有主动变成主节点.”如果不能从变主,那么集群的作用感觉就很弱,不能达到高可用,那还算什么集群!”,为此查询资料,做出解答,并弄明白问题所在.
当然,首先需要明白”哨兵模式”,”主从”.”集群”,”槽点”等概念原理,这里,我先看了相关资料,随后查看redis官网(有猜疑最后要看官方,其他资料只是帮助过度)

若有收获,就点个赞吧
0 人点赞
