1. 介绍
2. 数据结构(与mysql对比)
2.1不严谨类比
| ES | Mysql |
|---|---|
| index(索引) | datbase(数据库) |
| type(类型) | table(表) |
| document(一行数据) | data(一行数据) |
| field(属性) | Column(字段) |
注意。ES5.版本支持多个type.ES6.支持一个type.ES7.*不支持type!!!!
2.2 field支持的数据类型
字符串
text: 需要分词。比如一段话 keyword: 关键字,不需要分词。比如全省名字
数据类型
int /long/integer/short/byte/double/float/half_float/scaled_float
时间类型
date
布尔类型
boolean
二进制类型
binary
范围类型
long_range/float_range/ip_range
经纬度类型
geo_point:
等等。。。。
3. 简单的restful API
GET req: http://baseurl/index: 查询索引信息 http://baseurl/index/type/doc_id :查询文档信息 POST req: http://basseurl/index/type/_search:查询文档 http://baseurl/index/type/doc_id/_update:修改文档 PUT req: http://baseurl/index/type/_mappings:创建索引,包括构建索引的详细信息(type,field等等)。 DELETE req: http://baseurl/index/type/doc_id:删除指定文档 http://baseurl/index :删除索引
3.1 索引操作
3.1.1创建索引
创建一个car的索引。包括分片数目,备份数目,具体field
PUT /car 创建一个index{"settings": {"number_of_replicas": 1, //创建备份数目"number_of_shards": 5//创建数据分片数量。系统默认5片},"mappings": {"sportscar":{ // type对象。也就是表"properties": { // 属性"brand":{ // 属性名称"type":"keyword", // 属性类型"index":true //false=> 此属性不能被作为检索条件},"description":{"type":"text","analyzer":"ik_max_word"//分词器选择},"price":{"type":"long"},"birthdate":{"type":"date","format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd" // 不同的属性类型可能有其他的操作字段}}}}}
3.1.2 查看索引信息
GET /car
3.1.3 删除索引
DELETE /car
3.2 文档操作
3.2.1新增文档
- 使用系统生成id ```json POST /car/sportscar { “brand”:”胡小家”, “description”:”自主研发平台设备大点哈客户打款老师夸奖哈客户查金葵花卡很快就会”, “price”:1000.22, “birthdate”:”2020-09-09”
}
- 使用自己规则的id```jsonPOST /car/sportscar/1213{"brand":"胡家2","description":"自主研发平台设备大点哈客户打款老师夸奖哈客户查金葵花卡很快就会","price":1000.22,"birthdate":"2020-09-09"}
3.2.2修改文档
- 覆盖式修改,其实式新增 ```json POST /car/sportscar/1213 { “brand”:”胡家2修改”, “description”:”自主研发平台设备大点哈客户打款老师夸奖哈客户查金葵花卡很快就会”, “price”:1000.22, “birthdate”:”2020-09-09”
}
- 修改某一部分```jsonPOST /car/sportscar/1213/_update{"doc": {"brand":"胡家udate"}}
3.2.3删除文档
4. 使用node去调用
这里使用@elastic/elasticsearch, 配合kibana的json很适合。
5. 各种类型查询
5.1 term&&terms
5.2 match&&match_all
match .会根据你查询内容字段的类型进行相应的查询方式。
6. 一些使用问题
6.1 安装分词器
ES默认分词器对中文不友好。中文词汇会被分为单个字
- github 查询与ES相对应的版本分词器,推荐两个分词器ik 和THULAC
https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.1/elasticsearch-analysis-ik-6.8.1.zip
或者 https://github.com/microbun/elasticsearch-thulac-plugin
进入ES容器bin目录,安装分词器,THULAC分词器一样的操作流程
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.1/elasticsearch-analysis-ik-6.8.1.zip
重启容器
docker restart ES
测试分词器
kibana devtools 请求一下测试命令

疑问
6.*版本是否不支持多个type版本?
朋友的服务是6.8版本,但是其一个index有多个type。于是做了以下实验
准备6.8版本的elasticSearch和kinbana,并测试新增多个type的index.
新增内容:
```json put /cat2 { “settings”: { “number_of_replicas”: 1, “number_of_shards”: 5 }, “mappings”: { “sportscar”: {
"properties": {"brand": {"type": "keyword","index": true}}
}, “sportscar2”: {
"properties": {"brand2": {"type": "keyword","index": true}}
} } }
```
操作结果: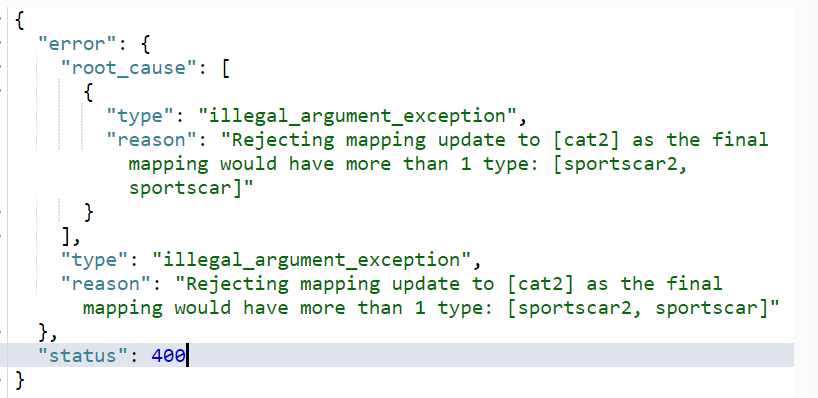
准备5.3版本的elasticSearch和kinbana,并测试新增多个type的index
新增内容和6.8内容一样<br /> 操作结果如下<br />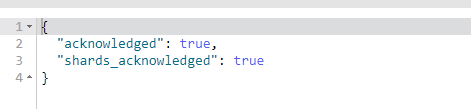<br />从结果来看,和资料显示的一样,6.8版本不支持多个type,但是根据[这个](https://github.com/elastic/elasticsearch/pull/24317),为了兼容之前的版本,ES在6的版本对之前的索引做了兼容,提供配置。
kibana中文控制台设置

若有收获,就点个赞吧
0 人点赞
