大数据技术概述
从批处理到流处理
批处理(Batch Processing)是指对一批数据进行处理。
数据其实是以流(Stream)的方式持续不断地产生着的,流处理(Stream Processing)就是对数据流进行处理。
流处理框架要解决的问题
- 可扩展性
- 数据倾斜
- 容错性
- 时序错乱
大数据处理平台的演进
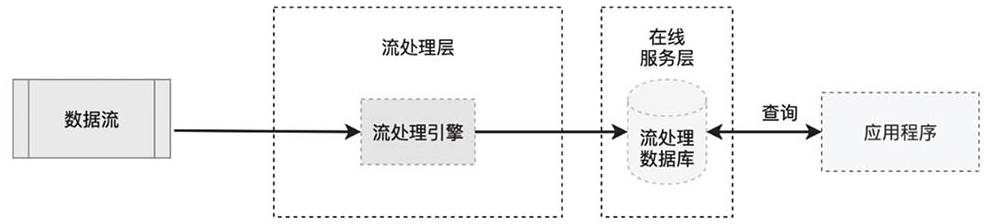
Lambda架构
Lambda架构主要分为3部分:批处理层、流处理层和在线服务层。其中数据流来自Kafka这样的消息队列。

优点:
- 批处理的准确度较高,而且在数据探索阶段可以对某份数据试用不同的方法,反复对数据进行实验。另外,批处理的容错性和扩展性较强。
- 流处理的实时性较强,可以提供一个近似准确的结果。
缺点:
使用两套大数据处理引擎,如果两套大数据处理引擎的API不同,有任何逻辑上的改动,就需要在两边同步更新,维护成本高,后期迭代的时间周期长。
Kappa架构
在某些场景下,没有必要维护一个批处理层,直接使用一个流处理层即可满足需求。Kappa架构适用于一些逻辑固定的数据预处理流程。
流处理基础概念
延迟和吞吐
低延迟,高吞吐。
当前大数据系统都在采用的两种加速方式,第一是优化单节点内的计算速度,第二是使用并行策略,分而治之地处理数据。
窗口与时间
在流处理场景下,数据以源源不断的流的形式存在,数据一直在产生,没有始末。我们要对数据进行处理时,往往需要明确一个时间窗口,比如,数据在“每秒”“每小时”“每天”的维度下的一些特性。窗口将数据流切分成多个数据块,很多数据分析都是在窗口上进行操作,比如连接、聚合以及其他时间相关的操作。
常见的窗口形式:滚动窗口、滑动窗口、会话窗口。
常见的时间语义:Event Time、Processing Time。
Watermark,等待多久后开始窗口计算。
状态与检查点
对一个窗口的流数据聚合运算涉及中间状态。
检查点(Checkpoint)的主要作用是将中间数据保存下来。
数据一致性保障
At-Most-Once
At-Least-Once
Exactly-Once
小结
大数据生态圈历经十几年发展,已经日渐完善,不同技术分别面向存储、计算和在线服务等不同的需求。随着业界对数据实时性要求越来越高,数据处理正在由批处理向流处理发展。
Flink提供了高吞吐、低延迟的性能,有效解决了状态管理和故障恢复等流处理领域非常棘手的问题,并且Flink也提供批处理能力,是一款流处理与批处理一体的大数据处理引擎。
Flink的设计与运行原理
Flink数据流图简介
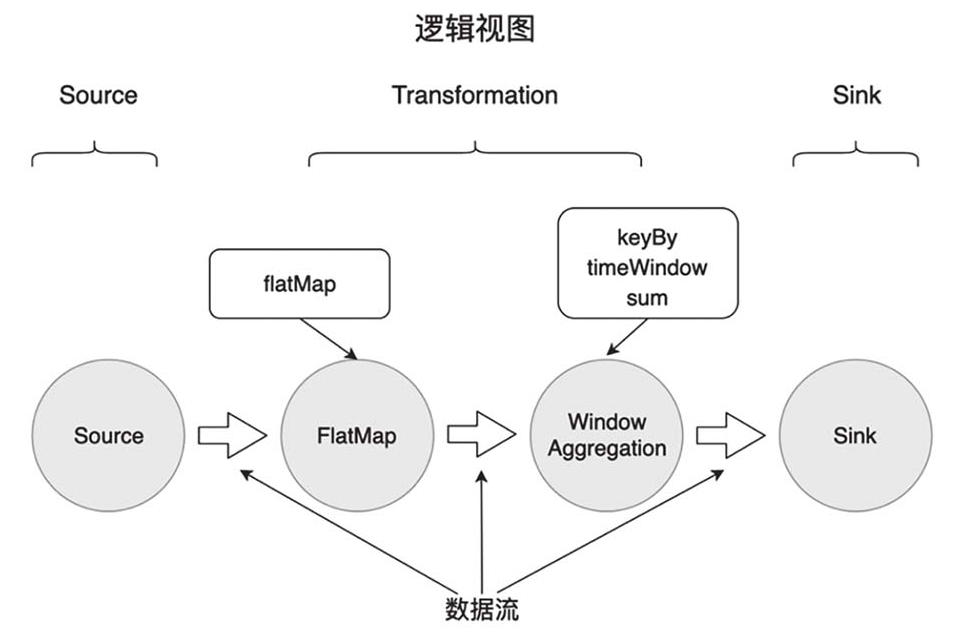
Flink程序和数据流图
Flink程序分为三大部分,第1部分读取数据源(Source),第2部分对数据做转换操作(Transformation),第3部分将转换结果输出到一个目的地(Sink)。

Source算子读取数据源中的数据,数据源可以是数据流,也可以存储在文件系统中的文件。
Transformation算子对数据进行必要的计算处理。
Sink算子将处理结果输出,数据一般被输出到数据库、文件系统或消息队列。
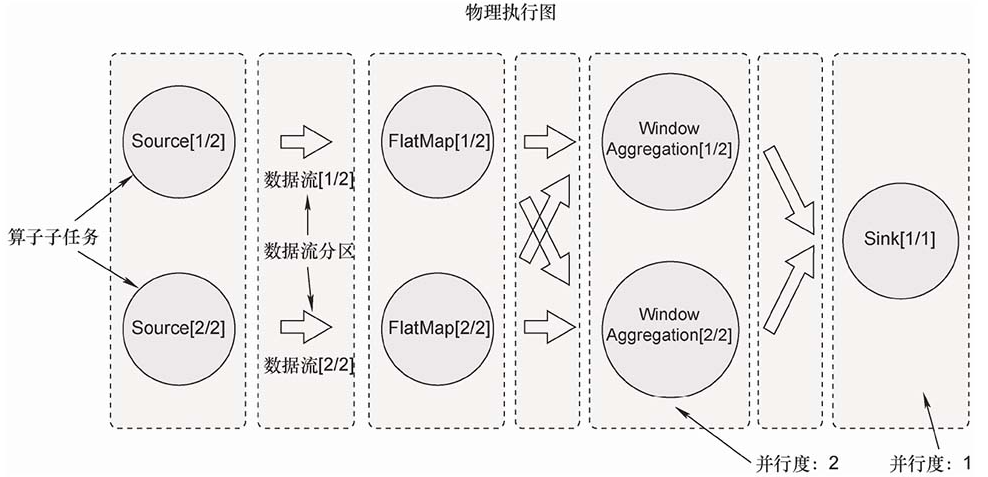
从逻辑视图到物理执行图
形成算子链,共享TaskManager Slot,根据并行度构建算子任务。
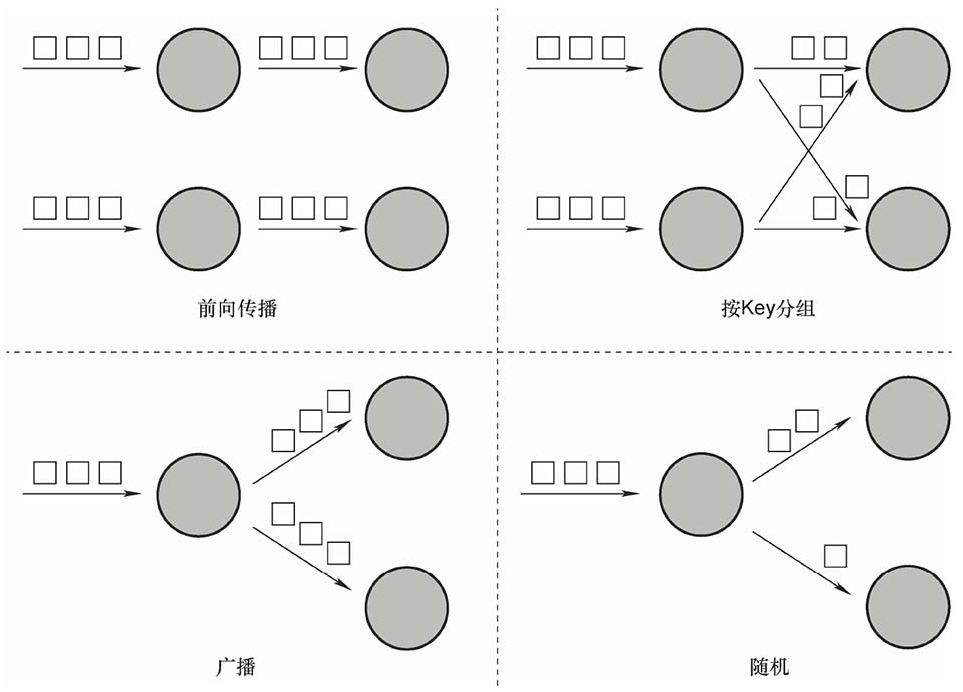
数据交换策略
Flink分布式架构与核心组件
Flink跟其他大数据框架一样,采用了主从(Master-Worker)架构。Flink执行时主要包括如下两个组件。
- Master是一个Flink作业的主进程。它起到了协调管理的作用。
- TaskManager,又被称为Worker或Slave,是执行计算任务的进程。它拥有CPU、内存等计算资源。Flink作业需要将计算任务分发到多个TaskManager上并行执行。
Flink作业提交过程
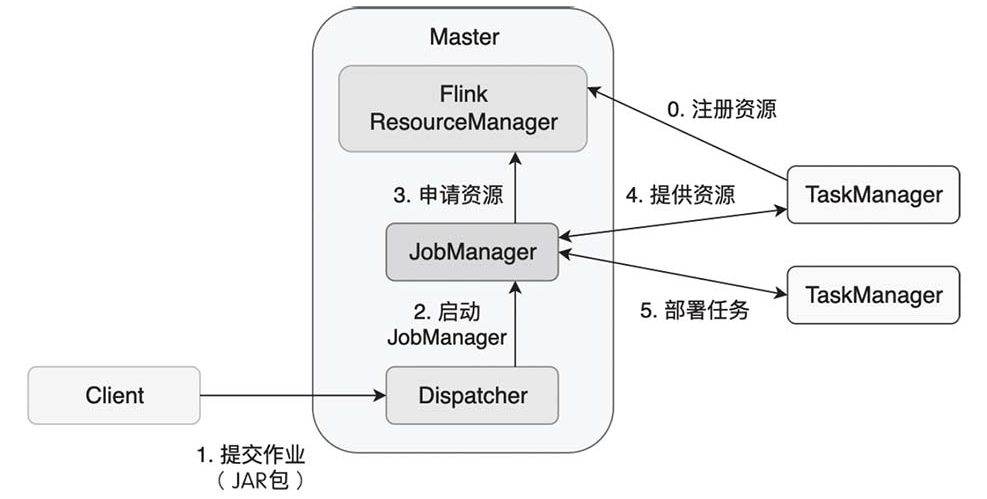
Flink核心组件
- Dispatcher:可以接收多个作业,每接收一个作业,Dispatcher都会为这个作业分配一个JobManager。
- JobManager:是单个Flink作业的协调者,一个作业会有一个JobManager来负责。
- ResourceManager:Flink现在可以部署在Standalone、YARN或Kubernetes等环境上,不同环境中对计算资源的管理模式略有不同,Flink使用一个名为ResourceManager的模块来统一处理资源分配上的问题。在Flink中,计算资源的基本单位是TaskManager上的任务槽位(Task Slot,简称Slot)。ResourceManager的职责主要是从YARN等资源提供方获取计算资源,当JobManager有计算需求时,将空闲的Slot分配给JobManager。当计算任务结束时,ResourceManager还会重新收回这些Slot。
- TaskManager:是实际负责执行计算的节点。
Flink组件栈

任务执行与资源划分
再谈逻辑视图到物理执行图
从逻辑视图转化为物理执行图的过程,该过程可以分成4层:StreamGraph→JobGraph→ExecutionGraph→物理执行图。
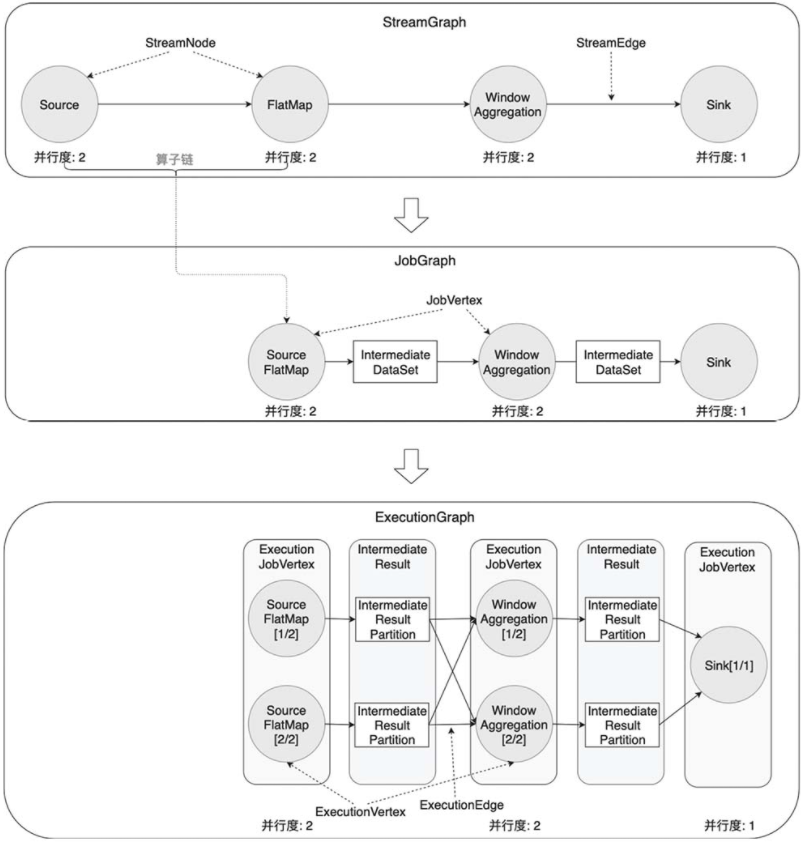
StreamGraph:根据用户编写的代码生成的原始图。
JobGraph:JobGraph是被提交给JobManager的数据结构。主要的优化为,将多个符合条件的节点链接在一起作为一个JobVertex节点,这样可以减少数据交换所需要的传输开销。
ExecutionGraph:ExecutionGraph是JobGraph的并行化版本。
物理执行图:JobManager根据ExecutionGraph对作业进行调度后,在各个TaskManager上部署具体的任务,物理执行图并不是一个具体的数据结构。
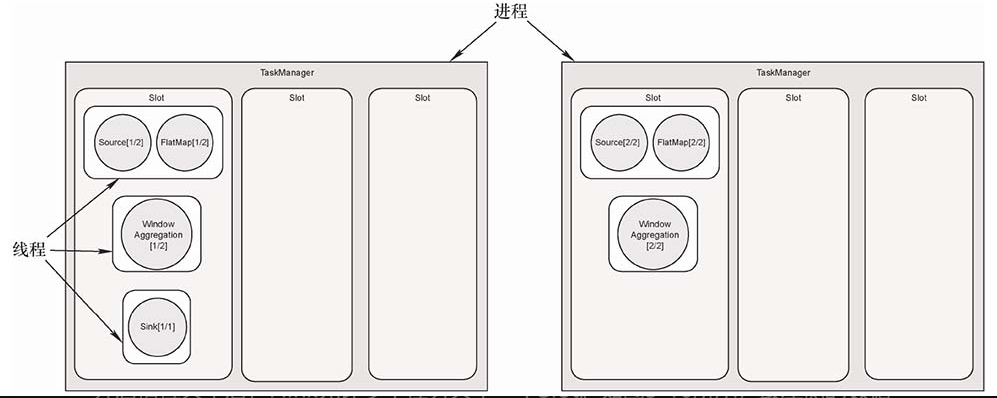
Slot与计算资源
一个TaskManager是一个进程,TaskManager可以管理一至多个任务,每个任务是一个线程,占用一个Slot。
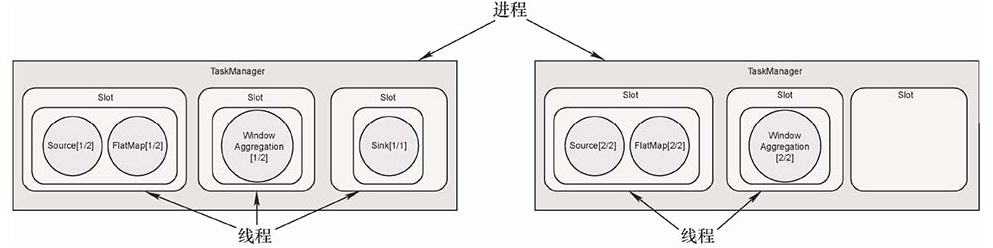
默认情况下,Flink还提供了一种槽位共享(Slot Sharing)的优化机制,进一步减少数据传输开销,充分利用计算资源。
DataStream API的介绍和使用
Flink程序的骨架结构
Flink程序的核心步骤:
- 设置执行环境。
- 读取一到多个数据源。
- 根据业务逻辑对数据流进行转换。
- 将结果输出到Sink。
- 调用作业执行函数。
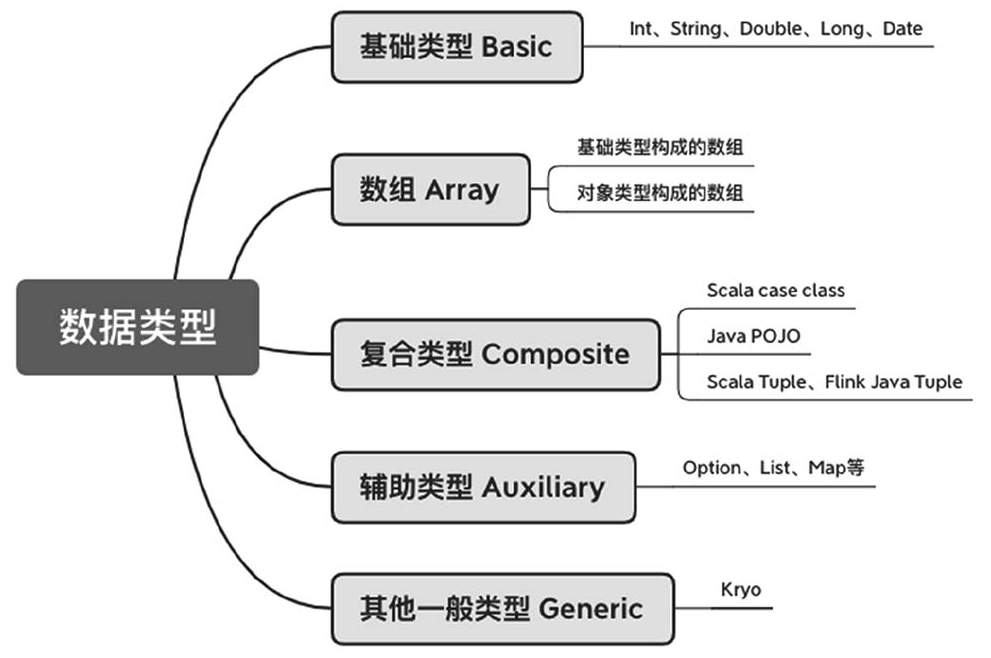
数据类型和序列化
几乎所有的大数据框架都要面临分布式计算、数据传输和持久化问题。数据传输过程前后要进行数据的序列化和反序列化。
Flink选择重新开发了自己的序列化框架,因为序列化和反序列化关乎整个流处理框架各方面的性能,对数据类型了解越多,可以更早地完成数据类型检查,节省数据存储空间。
Flink支持的数据类型
TypeInformation
TypeInformation的一个重要的功能就是创建TypeSerializer序列化器,为该类型的数据做序列化。每种类型都有一个对应的序列化器来进行序列化。
注册类
如果传递给Flink算子的数据类型是父类,实际执行过程中使用的是子类,子类中有一些父类没有的数据结构和特性,将子类注册可以提高性能。
使用其他序列化框架
Avro、Kryo、Thrift和Protobuf。
时间和窗口
Flink的时间语义
我们经常会遇到这样的需求:给定一个时间窗口,比如一个小时,统计时间窗口内的数据指标。
Flink的3种时间语义
Event Time
Event Time指的是数据流中每个元素或者每个事件自带的时间属性,一般是事件发生的时间。
使用Event Time意味着事件到达有可能是乱序的。
在实际应用中,当涉及对事件按照时间窗口进行统计时,Flink会将窗口内的事件缓存下来,直到接收到一个Watermark,Watermark假设不会有更晚到达的事件。
一个基于Event Time的Flink程序中必须定义:每条数据的Event Time时间戳;如何生成Watermark。
Processing Time
对于某个算子来说,Processing Time指使用算子的当前节点的操作系统时间。在Processing Time的时间窗口场景下,无论事件什么时候发生,只要该事件在某个时间段到达了某个算子,就会被归结到该窗口下,它不需要Watermark机制。
Processing Time在时间窗口下的计算会有不确定性。
Ingestion Time
Ingestion Time是事件到达Flink Source的时间。
分布式环境下Watermark的传播
由于上游各分区的处理速度不同,到达当前算子的Watermark也会有先后、快慢之分,每个算子子任务会维护来自上游不同分区的Watermark(Partition Watermark)信息,这是一个列表。Flink会遍历Partition Watermark列表中的所有时间戳,选择最小的时间戳作为该算子子任务的Event Time。
一旦发现某个数据流不再生成新的Watermark,我们要在SourceFunction中的SourceContext里调用markAsTemporarilyIdle()来设置该数据流为空闲状态,避免空转。

平衡延迟和准确性
Watermark是一种在延迟和准确性之间平衡的策略:
Watermark与事件的时间戳贴合较紧,一些重要数据有可能被当成迟到数据,影响计算结果的准确性;
Watermark设置得较大,整个应用的延迟增加,更多的数据会先被缓存以等待计算,会增加内存的压力。
窗口算子的使用
在批处理场景下,数据已经按照某个时间维度分批次地存储了。
在流处理场景下,我们要对数据进行处理时,也需要明确一个时间窗口,划分窗口是流处理需要解决的问题。
窗口程序的骨架结构
stream.keyBy(<KeySelector>).window(<WindowAssigner>)[.trigger(<Trigger>)][.evictor(<Evictor>)].reduce/aggregate/process()
窗口的生命周期:
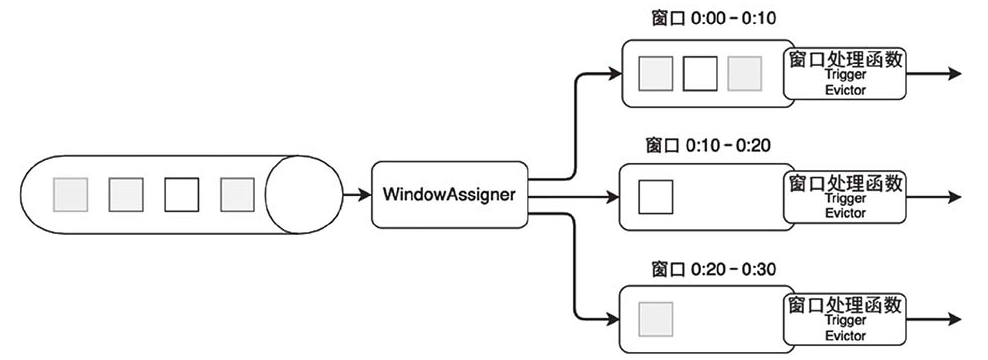
内置的3种窗口划分方法
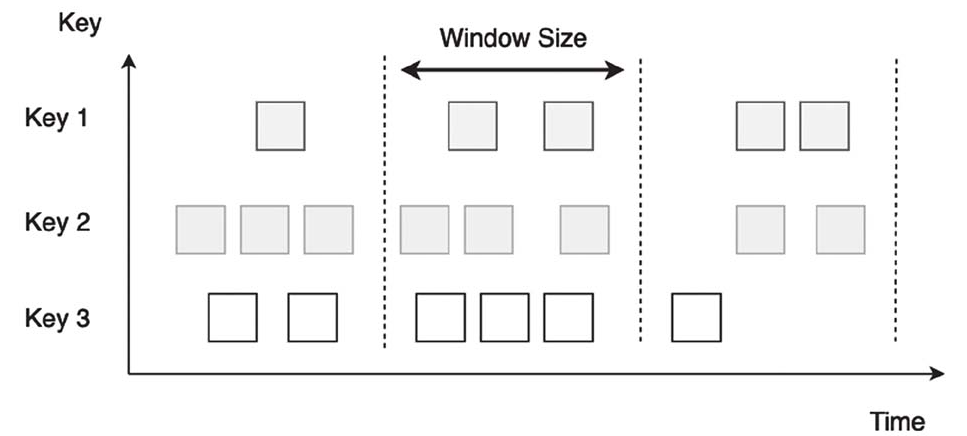
滚动窗口
窗口之间不重叠,且窗口长度(Window Size)是固定的。
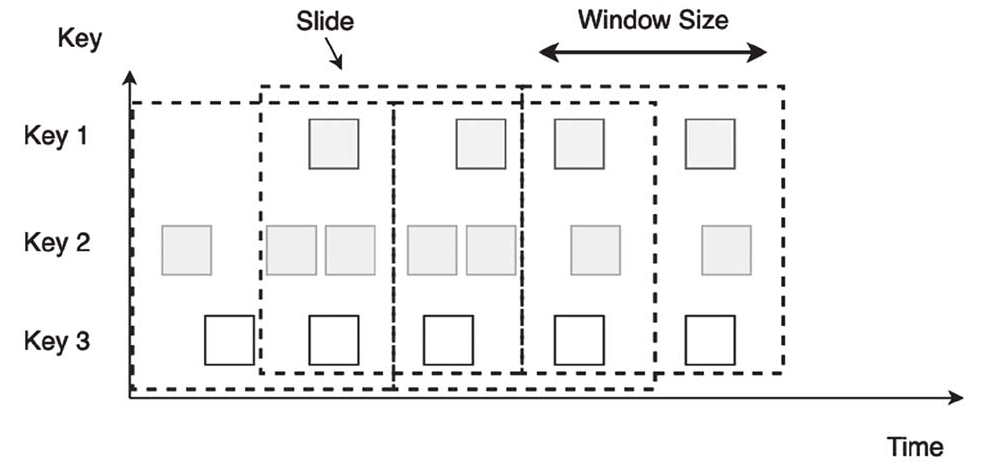
滑动窗口
滑动窗口以一个步长(Slide)不断向前滑动,窗口的Size固定。使用时,我们要设置Slide和Size。Slide的大小决定了Flink以多快的速度来创建新的窗口,Slide较小,窗口的个数会很多。Slide小于Size时,相邻窗口会重叠,一个元素会被分配到多个窗口;Slide大于Size时,有些元素可能被丢掉。
会话窗口
会话窗口模式下,两个窗口之间有一个间隙,称为Session Gap。当一个窗口在大于Session Gap的时间内没有接收到新数据时,窗口将关闭。

窗口处理函数
窗口处理函数主要分为两种,一种是增量计算,如reduce()和aggregate(),一种是全量计算,如process()。
增量计算指的是窗口保存一份中间数据,每流入一个新元素,新元素与中间数据两两合一,生成新的中间数据,再保存到窗口中。全量计算指的是窗口先缓存所有元素,等触发条件后才对窗口内的全量元素执行计算。
双流连接
批处理经常要解决的问题是将两个数据流连接,或者称为Join。Flink支持流处理上的Join,只不过Flink在一个时间窗口上来进行两个数据流的Join。
思考:Flink把所有的源数据看成流,不知道在Join的时候,Join或者Filter能不能下沉到数据源,只选择需要的数据,而不是等数据流到Flink之后再过滤。
处理迟到数据
目前Flink有如下3种处理迟到数据的方式:
- 直接将迟到数据丢弃。
- 将迟到数据发送到另一个数据流。
- 重新执行一次计算,将迟到数据考虑进来,更新计算结果。
更新计算结果:allowedLateness()允许用户先得到一个结果,如果在一定时间内有迟到数据,迟到数据会和之前的数据一起被重新计算,以得到一个更准确的结果。使用这个功能时需要注意,原来窗口中的状态数据在窗口已经触发的情况下仍然会被保留,否则迟到数据到来后也无法与之前的数据融合。另一方面,更新的结果要以一种合适的形式输出到外部系统,或者将原来结果覆盖,或者被复制为多份数据同时保存,且每份数据都有时间戳。
每出现一个迟到数据,迟到数据就会被加入ProcessWindowFunction的缓存中,窗口的Trigger会触发一次FIRE,窗口处理函数也会被重新调用一次,计算结果得到一次更新。
状态和检查点
实现有状态的计算
分布式状态管理
获取和更新状态的逻辑其实并不复杂,但流处理框架还需要注意以下3点:
- 数据的产出要保证实时性,延迟不能太高。
- 需要保证数据不丢失、不重复,恰好被计算一次,尤其是当状态数据量非常大或者应用出现故障需要恢复时,要保证状态不出任何错误。
- 一般流处理任务是持续运行的,程序的可靠性非常高。
作为一个计算框架,Flink提供了有状态的计算,封装了一些底层的实现,比如状态的高效存储、Checkpoint和Savepoint持久化备份机制、计算资源扩/缩容算法等。
Flink中几种常用的状态
Flink有两种基本类型的状态:托管状态(Managed State)和原生状态(RawState)。从名称中也能读出两者的区别:Managed State是由Flink管理的,Flink负责存储、恢复和优化;Raw State是由开发者管理的,需要自己进行序列化。
对Managed State继续细分,它又有两种类型的状态:Keyed State和OperatorState。Keyed State是KeyedStream上的状态,每个Key对应一个自己的状态。Operator State可以用在所有算子上,每个算子子任务共享一个状态,流入这个算子子任务的所有数据都可以访问和更新这个状态。
无论是Keyed State还是Operator State,Flink的状态都是基于本地的,即每个算子子任务维护着自身的状态,不能访问其他算子子任务的状态。
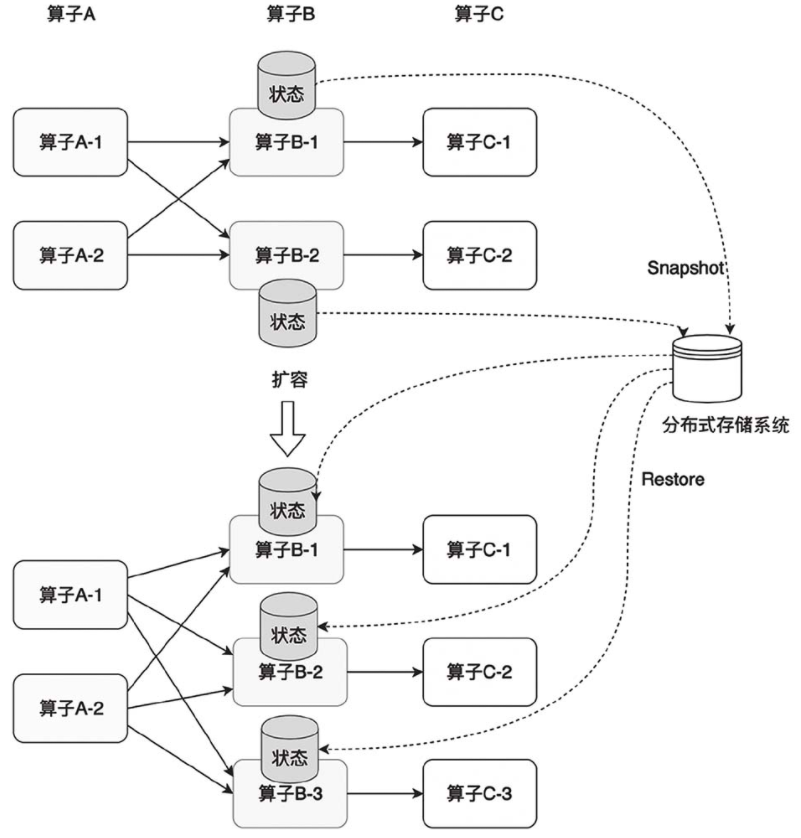
横向扩展问题
Flink的Checkpoint可以辅助迁移状态数据。算子的本地状态将数据生成快照(Snapshot),保存到分布式存储系统(如HDFS)上。横向扩展后,算子子任务数变化,子任务重启,相应的状态从分布式存储系统上重建(Restore)。
对于横向扩展问题,Keyed State会自动在多个并行子任务之间迁移。OperatorState有两种状态分配方式:一种是均匀分配;另一种是将所有状态合并,再分发给每个算子子任务。
算子扩容后的状态迁移:
Checkpoint机制
Flink定期保存状态数据到存储空间上,故障发生后从之前的备份中恢复,这个过程被称为Checkpoint机制。Checkpoint为Flink提供了Exactly-Once的投递保障。
Flink分布式快照流程
Checkpoint机制的大致流程:
- 暂停处理新流入数据,将新数据缓存起来。
- 将算子子任务的本地状态数据复制到一个远程的持久化存储空间上。
- 继续处理新流入的数据,包括刚才缓存起来的数据。
检查点分界线(CheckpointBarrier):
Checkpoint Barrier被插入数据流中,它将数据流切分成段。Flink的Checkpoint机制逻辑是,一段新数据流入导致状态发生了变化,Flink的算子接收到Checpoint Barrier后,对状态进行Snapshot。每个Checkpoint Barrier有一个ID,表示该段数据属于哪次Checkpoint。
Checkpoint Barrier对齐(BarrierAlignment):
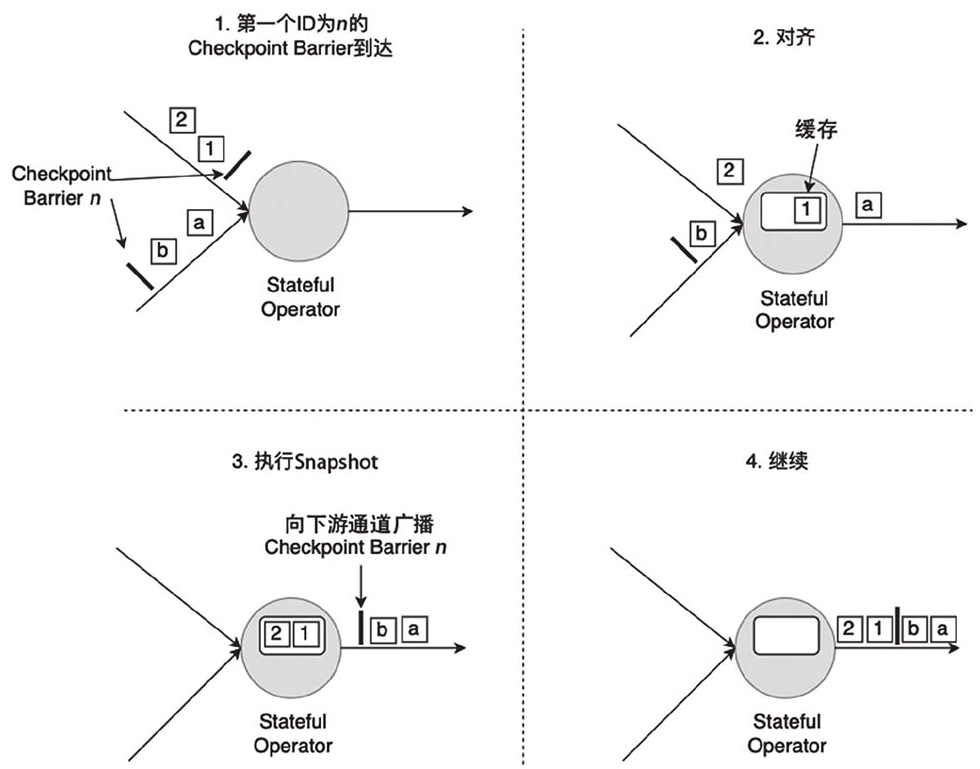
进行对齐,主要是为了保证一个Flink作业中所有算子的状态是一致的。也就是说,一个Flink作业前前后后所有算子写入State Backend的状态都基于同样的数据。
分布式快照性能优化方案
两个问题:
- 每次进行Checkpoint前,都需要暂停处理新流入的数据,然后开始执行Snapshot。假如状态数据量比较大,一次Snapshot处理时间可能长达几秒甚至几分钟。
- Checkpoint Barrier对齐时,必须等待所有上游通道都处理完,假如某个上游通道处理速度很慢,这可能造成整个数据流堵塞。
对应解决方案:
- 对于第一个问题,Flink提供了异步快照(Asynchronous Snapshot)的机制。
- 对于第二个问题,Flink允许跳过对齐。为了保证数据一致性,Flink必须对那些较晚流入的数据流中的数据也一起执行Snapshot,一旦作业重启,这些数据会被重新处理一遍。
Savepoint机制
目前,Checkpoint机制和Savepoint机制在代码层面使用的分布式快照逻辑基本相同,生成的数据也近乎一样,那它们到底有哪些功能性的区别呢?
Checkpoint机制的目的是为了故障重启,使得作业中的状态数据与故障重启之前的保持一致,是一种应对意外情况的有力保障。
Savepoint机制的目的是手动备份数据,以便进行调试、迁移、迭代等,是一种协助开发者的支持功能。
Checkpoint机制设计初衷为:第一,Checkpoint过程是轻量级的,尽量不影响正常数据处理;第二,故障恢复越快越好。
Savepoint机制主要考虑的是:第一,刻意备份;第二,支持修改状态数据或业务逻辑。Savepoint相关操作是有计划的、人为的。
Flink连接器
在实际生产环境中,数据可能存放在不同的系统中,比如文件系统、数据库或消息队列。一个完整的Flink作业包括Source和Sink两大模块,Source和Sink肩负着Flink与外部系统进行数据交互的重要功能,它们又被称为外部连接器(Connector)。
Flink端到端的Exactly-Once保障
故障恢复与一致性保障
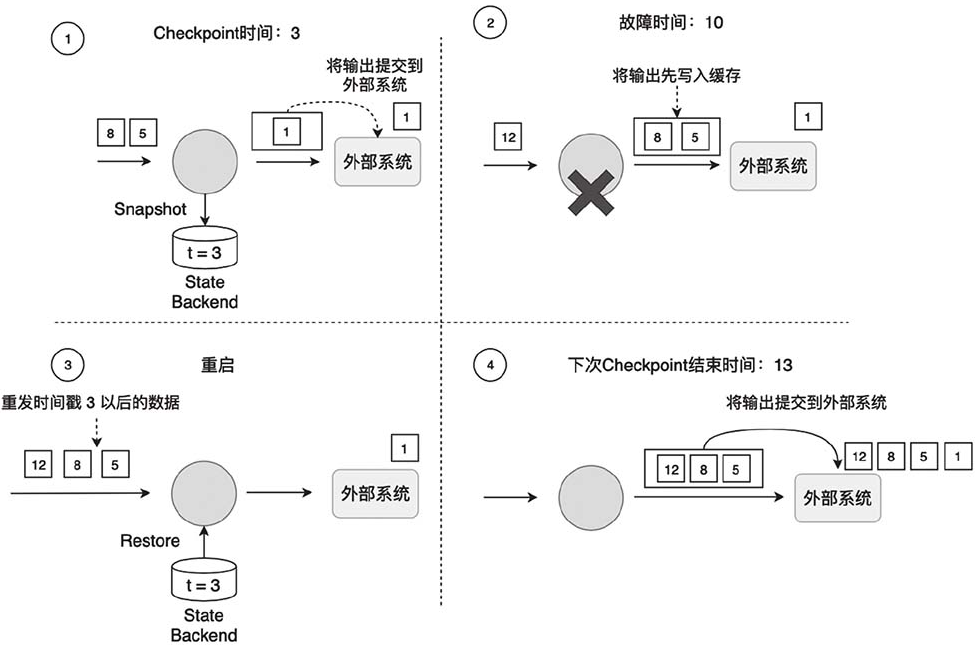
Flink的Checkpoint过程保证了一个作业内部的数据一致性,主要是因为Flink对如下两类数据做了备份。①作业中每个算子的状态。②输入数据的偏移量Offset。

但是这引发了一个问题,那就是时间戳3至10之间的数据被重发了。故障发生之前,这部分数据已经被一些算子处理了,甚至可能已经被发送到外部系统了,重启后,这些数据又被重新发送一次。
端到端的Exactly-Once,Flink内部状态的一致性主要依赖Checkpoint机制,外部交互的一致性主要依赖Source和Sink提供的功能。Source需要支持重发功能,Sink需要采用一定的数据写入技术,比如幂等写或事务写。
幂等写
幂等写(Idempotent Write)是指,任意多次向一个系统写入数据,只对目标系统产生一次结果影响。
像Cassandra、HBase和Redis这样的Key-Value数据库一般用来作为Sink,用以实现端到端的Exactly-Once保障。
Key-Value数据库作为Sink还可能遇到时间闪回的问题。在重启过程中,Key-Value数据库里的数据在某段时间内很有可能是不一致的,当数据重发完成后,数据才恢复一致性,这时它才可以提供端到端的Exactly-Once保障。
事务写
Flink的事务写(Transaction Write)是指,Flink先将待输出的数据保存下来,暂时不向外部系统提交;等到Checkpoint结束,Flink上、下游所有算子的数据都一致时,将之前保存的数据全部提交到外部系统。换句话说,只有经过Checkpoint确认的数据才向外部系统写入。
在事务写的具体实现上,Flink目前提供了两种方式:预写日志(Write-Ahead-Log,WAL)和两阶段提交(Two-Phase-Commit,2PC)。
这两种方式的主要区别在于:Write-Ahead-Log方式使用Operator State缓存待输出的数据;如果外部系统自身支持事务,比如Kafka,就可以使用Two-Phase-Commit方式,待输出数据被缓存在外部系统。
Table API & SQL
Flink基于DataStream/DataSet API提供了一个更高层的关系型数据库式的API——Table API & SQL。
SQL在效率方面有很大优势:用户可以更关注业务逻辑,执行优化可以交给Flink。
Table API & SQL综述
Table API & SQL程序的骨架结构
主要步骤:
- 创建执行环境(ExecutionEnvironment)和表环境(TableEnvironment)。
- 获取表。
- 使用Table API或SQL在表上做查询等操作。
- 将结果输出到外部系统。
- 调用execute(),执行作业。
获取表
Flink使用表表示广义上的表。它包括物理上确实存在的表,也包括基于物理表经过一些计算而生成的虚拟表,虚拟表又被称为视图(View)。
如果想在Flink中使用表来查询数据,最重要的一步是将数据(数据库、文件或消息队列)读取并转化成一个表。我们可以在Flink作业运行时注册一个新的表,也可以获取已创建好的常驻集群的表。在每个Flink作业启动后临时创建的表是临时表(Temporary Table),随着Flink作业的结束,该表也被销毁,它只能在一个Flink Session中使用。 但是在更多的情况下,我们想跟传统的数据库一样提前创建好表,这些表后续可以为整个集群上的所有用户和所有作业提供服务,这种表被称为常驻表(Permanent Table)。常驻表可以在多个Flink Session中使用。
在表上执行语句
Table API或者SQL。
获取表的具体方式
两种方式:
- 在程序中使用代码编程配置。
- 使用声明式的语言,如SQL的数据库定义语言(Data Definition Language,DDL)或YAML文件。
无论哪种方式,都需要配置外部系统的必要参数、序列化方式和Schema。
动态表和持续查询
批处理关系型查询与流处理的区别

在数据流上应用关系型查询是非常有挑战性的:数据流是无界的,一次查询启动后,需要持续对数据流做处理,查询结果根据新流入数据而不断更新。
流处理上的关系型查询借鉴了物化视图的实现思路,将外部系统中的数据缓存起来,当数据流入时,物化视图随之更新。
动态表上的持续查询
Flink提出了动态表(DynamicTable)的概念,旨在解决如何在数据流上进行关系型查询。
动态表用来表示不断流入的数据表,数据流是源源不断流入的,动态表也是随着新数据的流入而不断更新的。在动态表上进行查询,被称为持续查询(ContinuousQuery),因为底层的计算是持续不断的。一个持续查询的结果也是一个动态表,它会根据新流入的数据不断更新结果。
动态表的两种输出模式
计算结果的输出会有两种模式。一种是在结果末尾追加,我们称这种模式为追加(Append-only)模式;一种是既在结果末尾追加,又对已有数据更新,这种模式被称为更新(Update)模式。对数据更新又细分为两种模式,可以先将旧数据撤回,再添加新数据,这种模式被称为撤回(Retract)模式;或者直接在旧数据上做更新,这种模式被称为插入更新(Upsert)模式。
Join
Flink提供了3种基于动态表的Join:时间窗口Join(Time-windowedJoin)、临时表Join(Temporal Table Join)和传统意义上的Join(RegularJoin)。
思考:对于传统的Join,Flink可以把Filter下沉到数据源吗?

若有收获,就点个赞吧
0 人点赞
