数据仓库简介
什么是数据仓库
数据仓库之父Bill Inmon将数据仓库描述为一个面向主题的、集成的、随时间变化的、非易失的数据集合,用于支持管理者的决策过程。
面向主题:操作型系统面向业务功能,数据仓库面向业务分析和决策。
集成:需要把多种数据源集成在一起,通过多个侧面分析一个主题。
随时间变化:分析大量历史数据,反映趋势。
非易失:数据仓库中的数据不会更新。
操作型系统与分析型系统
操作型系统用于处理组织中的业务,目标是尽可能快地处理事务,同时维护数据的一致性和完整性。而分析型系统的主要作用是,通过数据分析评估组织的业务经营状况,辅助决策。
操作型系统
操作型系统是专门用于管理面向事务的应用的信息系统。
事务是工作于数据库管理系统(或类似系统)中的一个逻辑单元,该逻辑单元中的操作被以一种独立于其他事务的可靠方式所处理。
事务具有原子性、一致性、隔离性、持久性的特点。
操作型系统的数据库操作:
在数据库使用上,操作型系统常用的操作是增、改、查,并且通常是插入与更新密集型的,同时会对数据库进行大量并发查询,而删除操作相对较少。
操作型系统的数据库设计:
操作型系统的特征是大量短的事务,并强调快速处理查询。每秒事务数是操作型系统的一个有效度量指标。
分析型系统
分析型系统是一种快速回答多维分析查询的实现方式。
分析型系统的数据库操作:
在数据库层面,分析型系统操作被定义成少量的事务,复杂的查询,处理归档和历史数据。
分析型系统的数据库设计:
分析型系统的特征是相对少量的事务,但查询通常非常复杂并且会包含聚合计算。对于分析型系统,吞吐量是一个有效的性能度量指标。
操作型系统和分析型系统对比
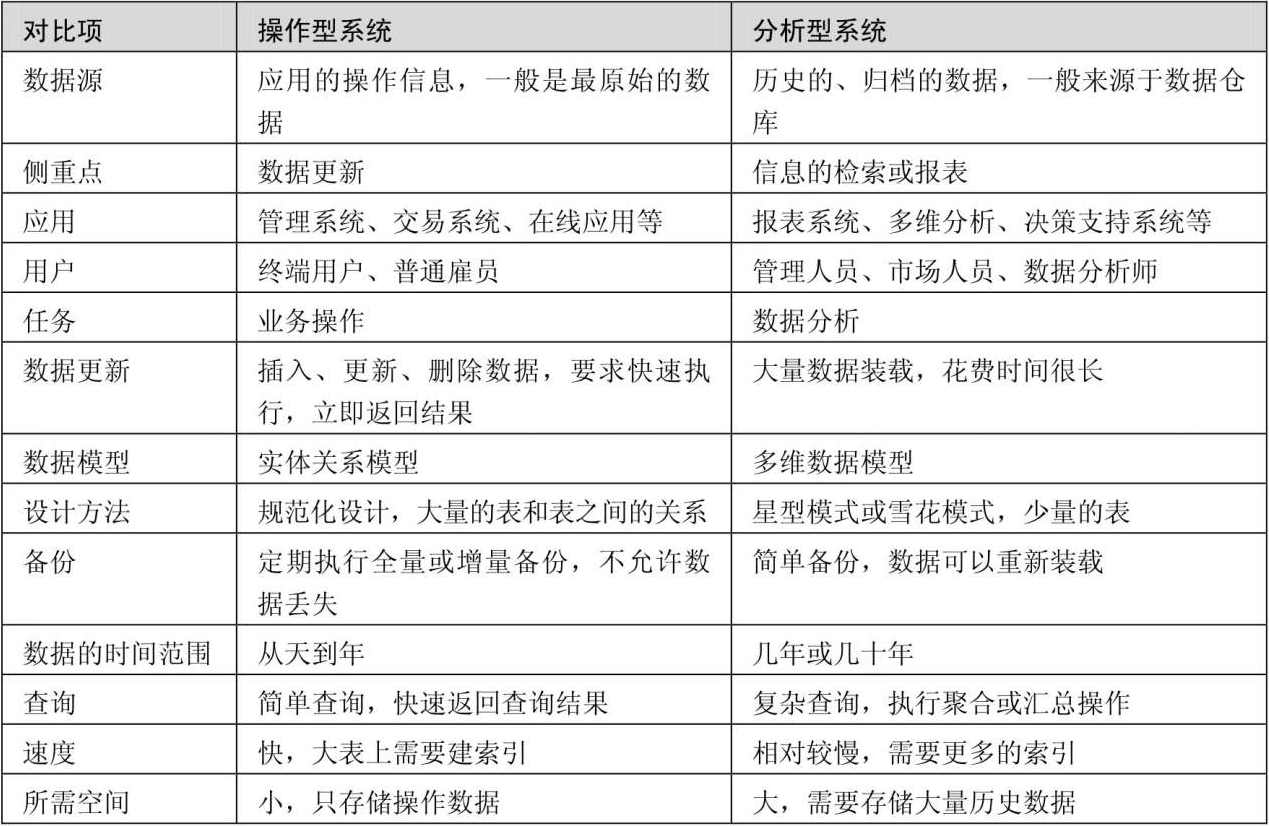
数据仓库架构
ETL:Extract、Transform、Load,数据抽取、转换和装载。
RDS:RAW DATA STORES,原始数据存储,和操作性系统中的数据保持一致。
TDS:TRANSFORMED DATA STORES,转换后的数据存储。
数据目录:元数据存储,它可以提供一份数据仓库中数据的清单。
抽取-转换-装载
ETL是建立数据仓库最重要的处理过程,也是最体现工作量的环节,一般会占到整个数据仓库项目工作量的一半以上。
数据抽取
数据抽取一般不能侵入源系统。
逻辑抽取类型:全量抽取和增量抽取。
物理抽取类型:联机抽取和脱机抽取。
增量抽取的方法有时间戳、快照、触发器和日志四种。其中日志的方式没有侵入性,同时也最复杂。
数据转换
数据从操作型源系统获取后,需要进行多种转换操作。如统一数据类型、处理拼写错误、消除数据歧义、解析为标准格式等。
数据装载
ETL的最后步骤是把转换后的数据装载进目标数据仓库。这步操作需要重点考虑两个问题,一是数据装载的效率问题,二是一旦装载过程中途失败了,如何再次重复执行装载过程。
提高装载效率,装载过程禁用约束和索引。处理装载失败,记录失败点,只重新装载失败的数据。
数据仓库需求
基本需求:安全性、可访问性和自动化。
数据需求:准确性、时效性和历史可追溯性。
数据仓库设计基础
关系数据模型
关系数据模型中的结构
关系、属性、属性域、元组、关系数据库。
关系数据模型中的键:超键、候选键、主键、外键。
关系完整性
空值(NULL):表示一个列的值目前还不知道,或者对于当前记录来说不可用。
关系完整性规则:实体完整性、参照完整性。
规范化
规范化方法对表进行分解,以消除数据冗余,避免异常更新,提高数据完整性。
第一范式(1NF):表中的列只能含有原子性(不可再分)的值。
第二范式(2NF):满足第一范式,并且没有部分依赖。
第三范式(3NF):满足第二范式,并且没有传递依赖。
维度数据模型
事实和维度是两个维度模型中的核心概念。事实表示对业务数据的度量,而维度是观察数据的角度。事实通常是数字类型的,可以进行聚合和计算,而维度通常是一组层次关系或描述信息,用来定义事实。
维度规范化
对维度的规范化(又叫雪花化),可以去除冗余属性。一个非规范化维度对应一个维度表,规范化后,一个维度会对应多个维度表,维度被严格地以子维度的形式连接在一起。
维度数据模型的特点
易理解:信息按业务种类或维度进行分组。
高性能:维度模型更倾向于非规范化,因为这样可以优化查询的性能。
可扩展:由于允许冗余,更容易容纳不可预料的新增数据。
星型模式
星型模式是维度模型最简单的形式,也是数据仓库以及数据集市开发中使用最广泛的形式。星型模式由事实表和维度表组成,一个星型模式中可以有一个或多个事实表,每个事实表引用任意数量的维度表。
事实表:记录了特定事件的数字化的考量,一般由数字值和指向维度表的外键组成。
维度表:维度表的记录数通常比事实表少,但每条记录包含有大量用于描述事实数据的属性字段。
优点:较少的表连接,简化查询,提升查询性能,快速聚合。
缺点:不能保证数据完整性,分析需求来说不够灵活。
雪花模式
所谓的“雪花化”就是将星型模式中的维度表进行规范化处理。
Data Vault模型
Data Vault不区分数据在业务层面的正确与错误,它保留操作型系统的所有时间的所有数据,装载数据时不做数据验证、清洗等工作,这点明显有别于其他数据仓库建模方法。对数据的解释将推迟到整个架构的后一个阶段(数据集市)。
Data Vault模型的构成
Data Vault模型有中心表(Hub)、链接表(Link)、附属表(Satellite)三个主要组成部分。中心表记录业务主键,链接表记录业务关系,附属表记录业务描述。
数据仓库实施步骤
实施一个数据仓库项目的主要步骤是:定义项目范围、收集并确认业务需求和技术需求、逻辑设计、物理设计、从源系统向数据仓库装载数据、使数据可以被访问以辅助决策、管理和维护数据仓库。
物理设计
物理数据库结构需要优化以获得最佳的性能。比较通用的数据仓库优化方法有位图索引和表分区。
访问数据
访问步骤是要使数据仓库的数据可以被使用,使用的方式包括:数据查询、数据分析、建立报表图表、数据发布等。
为前端工具建立一个中间层。把数据库的结构和对象转化成业务术语。
管理和维护这个业务接口。
建立和管理数据仓库里的中间表和汇总表,提升分析性能。
Hadoop生态圈与数据仓库
大数据定义
现在普遍认可的大数据是具有4V,即Volume、Velocity、Variety、Veracity特征的数据集合。Volume,生成和存储的数据量大,Velocity,数据产生和处理速度快,Variety,数据源和数据种类多样,Veracity,数据的真实性和高质量。
Hadoop简介
Hadoop包括以下四个基本模块:
- Hadoop基础功能库:支持其他Hadoop模块的通用程序包。
- HDFS:一个分布式文件系统,能够以高吞吐量访问应用的数据。
- YARN:一个作业调度和资源管理框架。
- MapReduce:一个基于YARN的大数据并行处理程序。
Hadoop的主要特点:
- 扩容能力
- 低成本
- 高效率
- 可靠性
Hadoop基本组件
HDFS
除了追加和清除操作外,HDFS中的文件在任何时候都是严格地一次写入。
HDFS使用所谓的“机架感知”策略放置数据块副本。
元数据存储:HDFS命名空间的元数据由NameNode负责存储。NameNode使用一个叫做EditLog的事务日志持久化记录文件系统元数据的每次变化。整个文件系统的命名空间,包括数据块和文件的映射关系、文件系统属性等,存储在一个叫做FsImage的文件中。
MapReduce
MapReduce数据处理分为Split、Map、Shuffle和Reduce 4个步骤。
Split:当一个记录跨越了块边界时怎么办呢?如果最后一个记录是不完整的,input split中包含下一个块的位置信息,还有完整记录所需的字节偏移量。
Shuffle:只有当所有的map任务都结束时,reduce任务才会开始处理。
Reduce:map任务的输出写入所在节点的本地磁盘,reduce任务的输出写入分布式hdfs文件系统。
计算向数据迁移,仅适用于map任务,reduce任务涉及多个节点的数据整合,使用数据向计算迁移。
YARN
YARN的基本思想是将资源管理、调度和监控功能从MapReduce分离出来,用独立的后台进程实现。
ResourceManager,全局资源管理器,包括调度器和应用管理器。
NodeManager,节点管理器,工作节点的代理,监控工作节点的资源情况。
ApplicationMaster,具体应用的抽象,可以运行在任意工作节点。
Hadoop与数据仓库
Hadoop生态圈的工具能够比关系数据库处理更多的数据,因为数据和计算都是分布式的。
关系数据库的可扩展性瓶颈
可扩展性可分为向上扩展(Scale up)和向外扩展(Scale out)。
向上扩展有时也称为垂直扩展,它意味着采用性能更强劲的硬件设备。
向外扩展有时也称为横向扩展或水平扩展,由多台廉价的通用服务器实现分布式计算,分担某一应用的负载。关系数据库的向外扩展主要有Shared Disk和SharedNothing两种实现方式。Shared Disk的各个处理单元使用自己的私有CPU和内存,共享磁盘系统,典型的代表是OracleRAC。Shared Nothing的各个处理单元都有自己私有的CPU、内存和硬盘,不存在共享资源,各处理单元之间通过协议通信,并行处理和扩展能力更好,MySQL Fabric采用的就是Shared Nothing架构。
CAP理论
关系数据库的可扩展性,随着分布式数据库技术的出现而有所缓解,但还是无法像Hadoop一样轻松在上千个节点上进行分布式计算。究其原因,就不得不提到CAP理论。
CAP的困境在于允许数据变更,每次变更就得数据同步,保持一致性,这样系统就变得很复杂。然而对于数据仓库这样的应用来说,数据就是客观存在的,不可变,只能增加和查询。任何的变更都是增加记录,通过对所有记录的操作进行合并,从而得到最终记录。
CAP理论从出现到被证明,再到饱受质疑和重新定义,我们应该如何看待它呢?
首先肯定的是,CAP理论并不是神话,它并不适合再作为一个适应任何场景的定理,它的正确性更加适合基于原子读写的NoSQL场景。
其次,无论如何C、A、P这三个概念始终存在于任何分布式系统,只是不同的模型会对其有不同的呈现,可能某些场景对三者之间的关系敏感,而另一些不敏感。
最后,作为开发者,一方面不要将精力浪费在如何设计能满足三者的完美分布式系统,而是应该进行取舍。另一方面,分布式系统还有很多特性,如优雅降级、流量控制等,都是需要考虑的问题,而不仅是CAP三者。
Hadoop数据仓库工具
RDS和TDS:Hive
抽取过程:Sqoop和Flume
转换与装载过程:Hive
过程管理和自动化调度:Falcon和Oozie
数据目录:HCatalog
查询引擎和SQL层:Hive、SparkSQL、Presto、Impala
用户界面:Hue和Zeppelin
建立数据仓库模型
Hive相关配置
使用Hive作为多维数据仓库的主要挑战是处理渐变维(SCD)和生成代理键。处理渐变维需要配置Hive支持行级更新,并在建表时选择适当的文件格式。生成代理键使用自增函数。
选择文件格式
Hive中常用的数据文件格式有4种:TEXTFILE、SEQUENCEFILE、RCFILE、 ORCFILE。
不同文件格式的主要区别在于它们的数据编码、压缩率、使用的空间和磁盘I/O。
应该依据数据需求选择适当的文件格式,例如:
- 如果数据有参数化的分隔符,那么可以选择TEXTFILE格式。
- 如果数据所在文件比块尺寸小,可以选择SEQUENCEFILE格式。
- 如果想执行数据分析,并高效地存储数据,可以选择RCFILE格式。
- 如果希望减小数据所需的存储空间并提升性能,可以选额ORCFILE格式。
支持行级更新
为了在HDFS上支持事务,Hive将表或分区的数据存储在基础文件中,而将新增的、修改的、删除的记录存储在一种称为delta的文件中。每个事务都将产生一系列delta文件。在读取数据时Hive合并基础文件和delta文件,把更新或删除操作应用到基础文件中。
Hive已经支持完整ACID特性的事务语义,增加了以下使用场景:
- 获取数据流:支持事务功能后,应用(Flume)就可以向Hive表中持续插入数据行,避免产生太多的文件,并且向用户提供数据的一致性读。
- 处理渐变维:支持修改历史记录,某个字段。
- 数据修正:行级别的delete,insert,update。
Hive表分类
管理表
也称为内部表。Hive会控制这些表中数据的生命周期。
管理表的主要问题是只能用Hive访问,不方便和其他系统共享数据。
外部表
外部表方便对已有数据的集成。在对外部表执行删除操作时,只是删除掉描述表的元数据信息,并不会删除表数据。
管理表和外部表之间的差异要比看起来的小得多。即使对于管理表,用户也可以指定数据是存储在哪个路径下的,因此用户也可以使用其他工具(如hdfs的dfs命令等)来修改甚至删除管理表所在路径下的数据。
分区表
管理表和外部表都可以创建相应的分区表,分别称之为管理分区表和外部分区表。外部分区表是管理大型生产数据集最常见的方式。
对数据进行分区,最重要的原因就是为了更快地查询。
一个强烈建议的安全措施是将Hive设置为严格mapred模式,这样如果对分区表进行查询而WHERE子句没有加分区过滤的话,将会禁止提交这个查询。
向Hive表装载数据
向非分区表中装载数据
load与load overwrite的区别是:load每次执行生成新的数据文件,文件中是本次装载的数据。load overwrite如表(或分区)的数据文件不存在则生成,存在则重新生成数据文件内容。
向分区表中装载数据
分区表比非分区表多了一种alter table … add partition的数据装载方式。
动态分区插入
先把数据写入非分区表,再通过HiveQL插入分区表。
数据抽取
sqoop,略
数据转换与装载
数据清洗
数据清洗是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
处理“脏数据”:
残缺数据:记录到日志,要求业务方补全
错误数据:记录到日志,要求业务方修正
重复数据:自动查重去重
差异数据:与业务方讨论数据标准
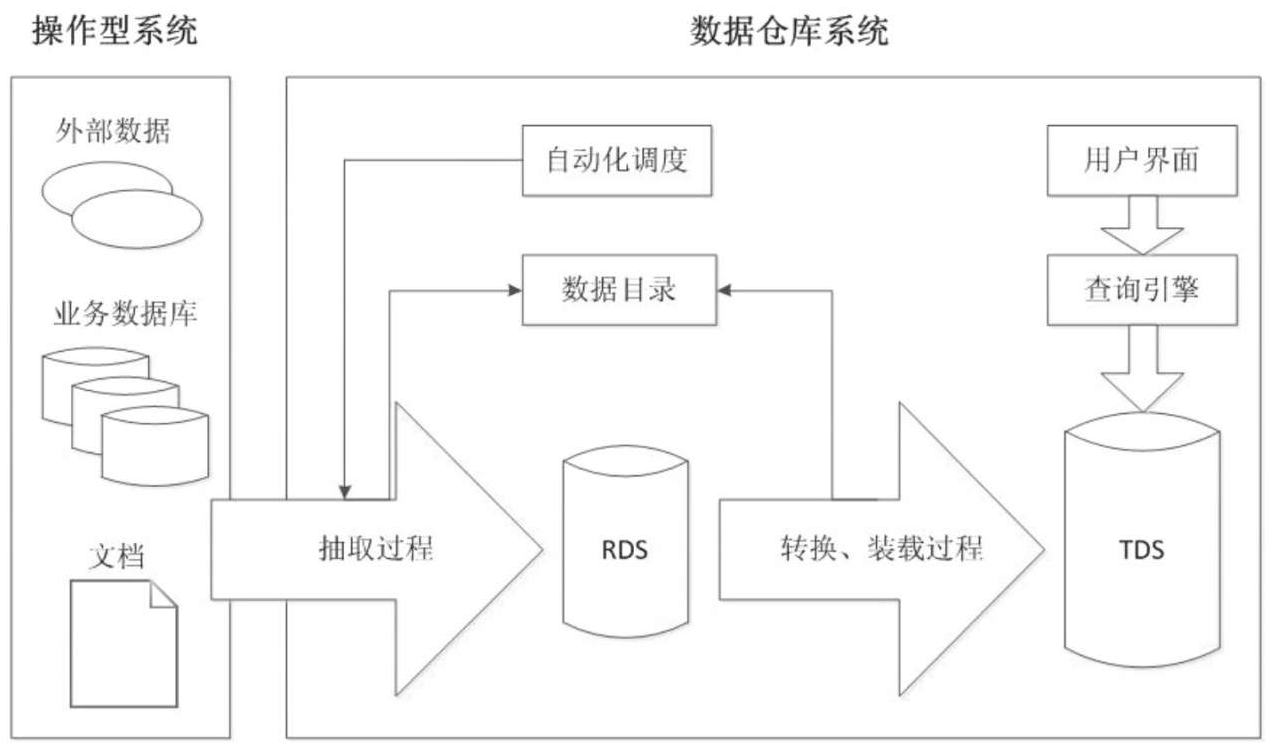
Hive简介
Hive是Hadoop生态圈的数据仓库软件,使用类似于SQL的语言读、写、管理分布式存储上的大数据集。
Hive包括HCatalog和WebHCat两个组件。HCatalog是Hadoop的表和存储管理层,允许使用Pig和MapReduce等数据处理工具的用户更容易读写集群中的数据。WebHCat提供了一个服务,可以使用HTTP接口执行MapReduce(或YARN)、Pig、Hive作业或元数据操作。
Hive的体系结构
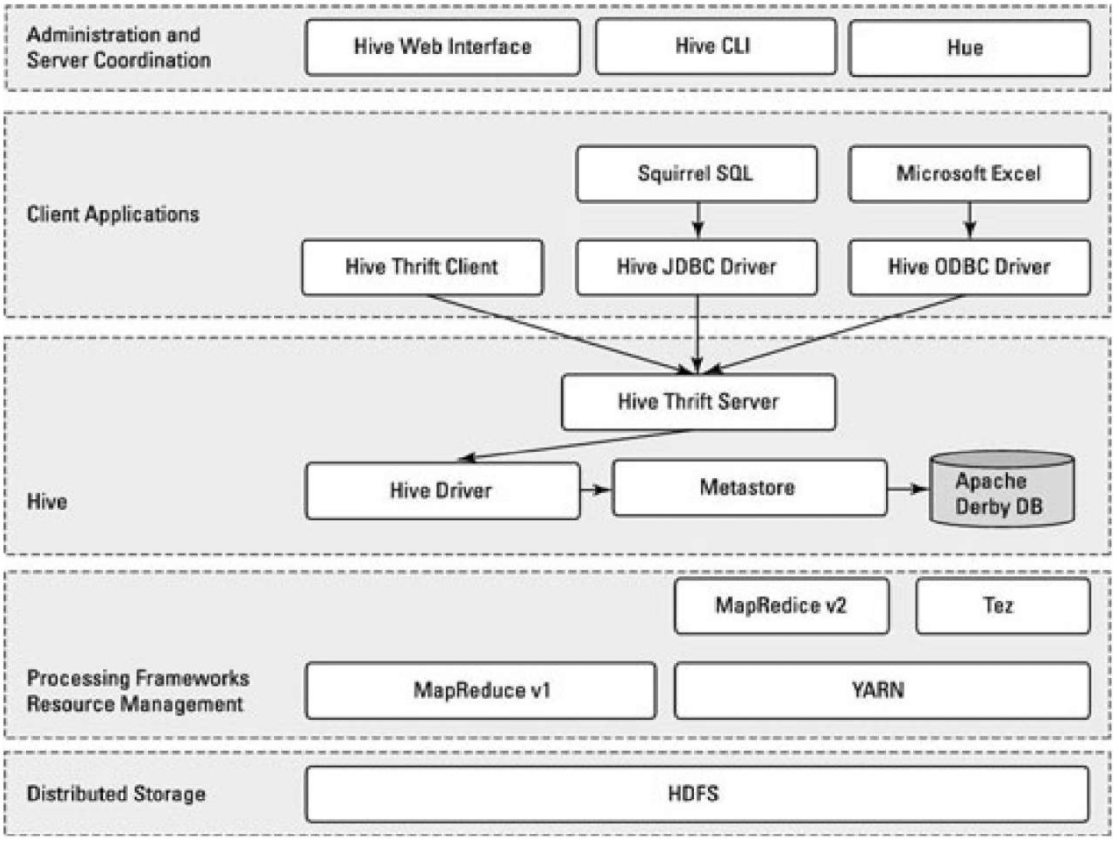
Hive的工作流程
初始装载
使用HiveQL。
定期装载
使用HiveQL,考虑渐变维的处理(修改或新增),记录增量装载的点。
使用Hive定期装载非常慢,没有更好的工具?
Hive优化
- 启用压缩。MapReduce是I/O密集型操作,减少I/O就能加快查询。
- 优化连接
- 避免使用order by全局排序
- 启用Tez执行引擎
- 优化limit操作
- 启用并行执行
- 启用MapReduce严格模式
- 使用单一Reduce执行多个Group By
- 控制并行Reduce任务
- 启用向量化
- 启用基于成本的优化器
- 使用ORC文件格式
定期自动执行ETL作业
使用Oozie定义ETL作业工作流,通过触发器定期执行。
维度表技术
包括:增加列、维度子集、角色扮演维度、层次维度、退化维度、杂项维度、维度合并、分段维度。
事实表技术
包括:周期快照、累积快照、无事实的事实表、迟到的事实和累积度量。
联机分析处理
联机分析处理简介
概念
联机分析处理又被称为OLAP,是英文On-Line Analytical Processing的缩写。OLAP允许以一种称为多维数据集的结构,访问业务数据源经过聚合和组织整理后的数据。
在计算领域,OLAP是一种快速应答多维分析查询的方法,也是商业智能的一个组成部分,与之相关的概念还包括数据仓库、报表系统、数据挖掘等。
OLAP由三个基本的分析操作构成:合并(上卷)、下钻和切片。切片是从不同的维度观察特定的数据。
分类
MOLAP(multi-dimensional online analytical processing),将数据存储在一个经过优化的多维数组中,而不是存储在关系数据库中。提前聚合,查询速度快,装载速度慢。
ROLAP,直接使用关系数据库存储数据,不需要执行预计算。基础的事实数据及其维度表作为关系表被存储,而聚合信息存储在新创建的附加表中。
HOLAP,因为在额外的ETL开发成本与缓慢的查询性能之间难以选择,现在大部分商业OLAP工具都使用一种混合型(Hybrid)方法,它允许模型设计者决定哪些数据存储在MOLAP中,哪些数据存储在ROLAP中。
性能
不管哪种方法,大数据分析的效率是个关键问题。
Hive、SparkSQL、Impala比较
Hive:适合大规模数据批处理
SparkSQL:统一的数据抽象DataSet和DataFrame
Impala:适合实时交互式分析查询

若有收获,就点个赞吧
0 人点赞
