Java基础
面向对象
- 面向过程:面向过程是一种以事件为中心的编程思想,编程的时候注重执行过程,然后用函数将这些步骤一步一步的实现
- 面向对象:面向对象是基于面向过程的编程思想,是一种万物皆对象的编程思想,将整个需求划分为不同的类,每个类具有不同的属性和行为。
面向对象的三大特性:
- 封装:遵循开闭原则,通常认为封装是把数据和操作数据的方法封装起来,对数据的访问只能通过已定义的接口
- 继承:继承是从已有类得到继承信息创建新的类的过程。提供继承信息的类称为父类
- 多态:多态是同一个行为具有不同的表现形式或形态的能力,多态又分为编译时多态(重载)和运行时多态。
- 在运行时判断任意一个对象所属的类
- 在运行时构造任意一个类的对象
- 在运行时判断任意一个对象所具有的成员变量和方法
-
IO
涉及到的涉及模式:
装饰者模式:所谓装饰,就是把这个装饰者套在被装饰者之上,从而动态扩展被装饰者的功能。装饰者的方法有一部分是自己的,这属于它的功能,然后调用被装饰者的方法实现,从而也保留了被装饰者的功能。常见的IO模型
同步阻塞IO、同步非阻塞IO、IO多路复用、信号驱动IO、异步IO
BIO
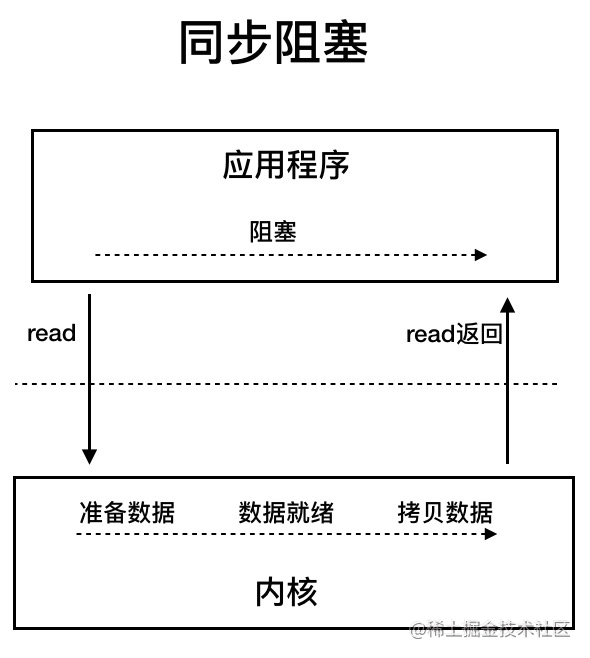
BIO-阻塞IO:(阻塞IO)应用程序发起read调用的时候,会一直阻塞,知道内核把数据拷贝到用户空间
NIO
- NIO-非阻塞IO(自旋IO):提供了Channel,selector,Buffer等抽象,它是支持面向缓冲的,基于通道的IO操作方法。对于高负载、高并发场景,应使用NIO
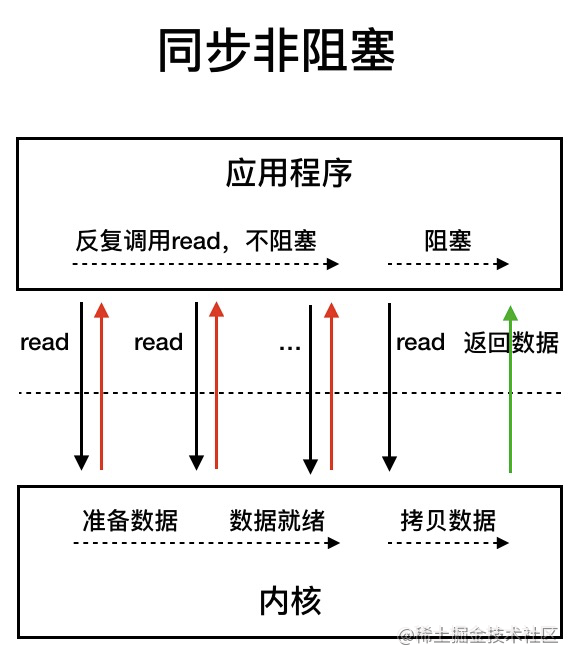
同步非阻塞IO模型中,应用程序会一直发起read调用,等待数据从内核空间拷贝到用户空间的这段时间,线程依然是阻塞的,知道在内核把数据拷贝到用户空间。
相比于同步阻塞IO模型,同步非阻塞IO模型确实有了很大的改进。通过轮询操作(自旋式的读取),避免了一直阻塞,但是这种IO模型同样存在问题:应用程序不断进行IO系统调用通过轮询数据是否已经准备好的过程是十分消耗CPU资源的。
这个时候IO多路复用模型就上场了
IO复用
IO复用:使用select或者poll、epoll等待数据,并且可以等待多个套接字中的任何一个变为刻度,这一过程会被阻塞,当某个套接字可读时返回。之后再使用recvfrom把数据从那个复制到进程中。
IO复用让单个进程具有处理多个IO事件的能力。又被称为事件驱动IO
相当于是阻塞的等待多个socket,BIO是等待一个,NIO是轮询,SIO信号驱动是等待信号
信号驱动IO
应用程序下使用sigaction系统调用,内核立即返回,应用进程可以继续执行,也就是说等待数据节点应用进程是非阻塞的。内核再数据到达时向应用进程发送SIGIO信号,应用进程收到之后再信号处理程序中调用recvfrom将数据从内核复制到应用进程中。
AIO异步IO
异步IO是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会阻塞在那里,当后台处理完成操作系统会通知相应的线程进行后续的操作。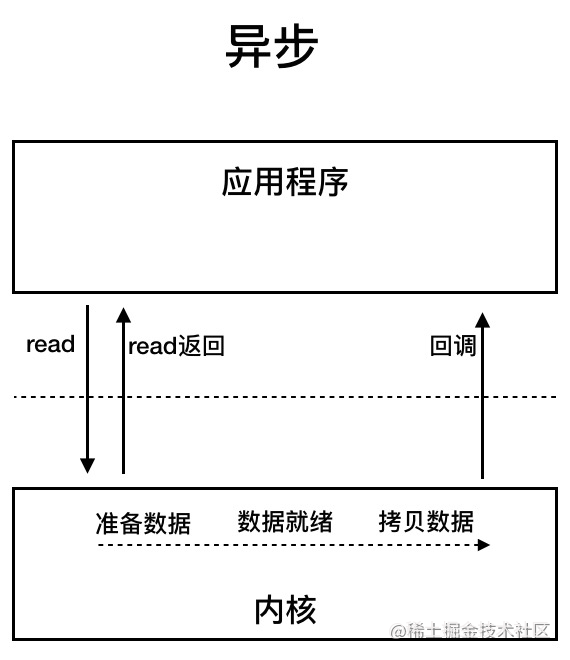
JVM
并发多线程
并发三要素
来源:
- 因为CPU处理速度和缓存读写速度的差异;会导致可见性的问题
- 操作系统增加了进程和线程,以时分复用CPU,进而均衡CPU于IO设备的速度差异,会导致原子性的问题
- 编译器程序优化指令执行顺粗,使得缓存能够更加合理的使用,会导致有序性的问题
Redis和Mysql的数一致性
- 一般情况下,Redis是用来作为数据库和应用之间进行读操作的缓存层,主要的目的是去减少数据库的IO,提升IO的整体性能。
- 整体架构:当应用程序需要去读取数据的时候,
- 他会先去查询缓存,如果命中缓存,则从缓存中直接加载数据
- 如果没有命中缓存,则从数据库中加载数据
- 并将读取的写入缓存中
- 这里会存在一个问题就是,一份数据保存在两个地方(数据库和缓存中),当数据发生变化的时候需要他是更新redis和MySQL,由于更新操作是有先后顺序的,如果是在单线程的程序中不会存在问题,但是在多线程环境中它并不满足对MySQL单独操作的ACID特性,所以就会产生数据一致性的问题。
- 方案:
- 先更新数据库再更新缓存:如果缓存更新失败,就会导致数据库和缓存中的数据是不一致的
- 先删除缓存再更新数据库:理想情况下,是利用下次对redis访问数据的时候,如果发现数据是空的,然后再将数据加载到redis中。理论上是一致的
- 但是在极端情况下,如果是在删除缓存和更新数据库之间,有另外一个线程发起了对该数据的访问,则会将数据再次写入缓存,此时数据库完成更新。出现数据不一致的情况。
- 为了解决这个极端情况,就只能采用最终一致性方案了:消息队列
- 基于MQ的可靠消息通信;
- 更新数据库的数据
- 写入缓存
- 失败请求写入MQ事务消息,异步充实执行,确保成功
- 会存在短期不一致的问题,如果不能接收短期不一致那就只能采取别的方案了。
AQS
AQS是多线程同步器,他是JUC包中多个组件的底层试下,人Lock,ReentrantLock,CountDownLatch,Semaphore等都用到了AQS。
核心思想:如果被访问的共享资源空闲,那么就将当前访问的线程设置为有效工作线程,并且将共享资源设定为锁定状态;如果被请求的共享资源被占用,那么就需要一套线程阻塞阻塞等待和被唤醒后锁分配的机制。这个机制AQS是用CLH双向队列来实现的。
从本质上来说,AQS提供了两种锁机制,分别是排它锁和共享锁。
- 排它锁,就是存在多线程竞争统一共享资源时同一时刻只允许一个线程访问该共享资源,也就是说多个线程只允许一个线程获得所资源
- 共享锁也称为读锁,就是在同一时刻允许多个线程他是获得资源。
在AQS的整个设计体系中需要解决三个核心的问题:
- 互斥变量的设计,以及如何保证多线程同时更新互斥量的时候多线程访问的数据安全性
- 未竞争到锁的线程的等待以及竞争到锁资源释放锁之后的唤醒
-
AQS设计细节
AQS 采用了一个int类型的互斥变量‘state’用来记录锁竞争的状态,0表示当前没有任何线程资源竞争锁资源,而大于等于1表示已经有n个线程获取到共享资源。
- 一个线程获取锁资源的时候,会先去判断state是否为0,也就是判断是否有线程持有锁对象,如果是则把state更新为1,表示占用到锁,采用CAS操作更新。
- 为获取到锁资源的线程将会被加入到CLH双向队列中,并按照先进先出原则排序等待。
- 当获取到锁资源的线程释放所之后,AQS会从CLH队列的头节点去唤醒下一个等待的线程,再去竞争锁
- 这个时候关于锁竞争的公平性问题,在竞争锁资源的时候,公平锁需要去判断双向列表中是否有阻塞的线程,如果有则需要去排队等待,而非公平锁的处理方式是,不管线程中是否存在等待的阻塞线程那么他都会去直接尝试更改state。
volatile关键字
volatile主要有两个作用:
- 保证多线程环境下对共享变量访问的可见性
- 通过增加内存屏障防止多个指令之间的重排序问题
对于可见性的理解
- 当一个线程对一个共享资源的修改,其他线程可以立即看到本次修改
- 本质上是由几个方面造成的:CPU层面的高速缓存,
- CPU设计了三级缓存去解决CPU运算效率和IO效率的问题,但是也带来了缓存一致性问题,多线程环境下,缓存一致性问题也就会带来可见性问题
- 对于增加了volatile的共享变量,虚拟机会在cpu层面自动为其添加一个#Lock指令
- 而这个指令会更加CPU型号自动添加总线锁或者缓存锁
- 总线锁是锁定CPU前端总线,从而去导致同一时刻只能有一个线程和内存通信
- 第二个是缓存所,缓存所是基于MESI缓存一致性协议,只会对缓存的数据加锁
对于指令重排序
- 指令在编写的顺和执行顺序是不一致的,会对于满足as-if-serial语义的语句进行指令重排序,从而提升CPU的执行性能,这在单线程环境下是没有问题的,但是在多线程环境下会导致可见性问题
- 指令重排序本质是CPU对程序的一种优化方法,来自于几个方面:
分布式锁是一种跨进程,跨互斥节点的一种互斥锁,它可以用来保证多个机器节点对共享资源访问的排他性。
本质和单线程锁是一样的:线程锁的生命周期是单进程多线程,分布式锁是多进程多线程
数据结构
红黑树
二叉树:每个节点都有两个子树
二叉查找树:在二叉树的基础上,根节点上的元素会大于左子树的子节点的值,小于右子树
二叉平衡查找树:在BST的基础上做了平衡,任意两个叶子节点的差的绝对值不会大于1
平衡多路查找树:多叉的平衡二叉查找树。
红黑树:https://zhuanlan.zhihu.com/p/273829162
- 红黑树是对概念模型2-3-4树(B树)的一种实现

红黑树的五条定义:
- 节点颜色右红色和黑色
- 根节点必为黑色
- 所有叶子节点都是黑色(此处所提到的叶子节点其实是空连接)
- 任意节点到叶子节点经过的黑色节点数目相同(平衡性质)
- 不会有连续的红色节点
左旋和右旋
左旋:把当前节点的右节点作为父节点,把右节点的左节点作为当前节点的右节点
右旋:把当前节点的左节点作为当前节点的父节点,把左节点的右节点作为当前节点的左节点。
红黑树的调整
1. 新插入红黑树的节点一定是红色
2. 若新插入节点的爸爸是黑色节点,红黑树不需要调整
3. 若新插入节点的爸爸和它叔叔都是红色节点,红黑树只需要变色,不需要旋转
4. 若新插入节点的爸爸是红色,但是它叔叔是黑色(可能为null,但是null是叶子节点,正儿八经的黑色),这时,一定是变色+旋转
B树和B+树
B树是一颗多路查找树
- 二叉查找树是在二叉树的基础上增加了一个规则,左子树的所有子节点小于根节点,而右子树的根节点都要大于根节点。在极端情况下,二叉树会出先斜树的问题从而出现出退化成链表的情况导致时间复杂度增加。
- 平衡二叉树:在BST的基础上新增了一个规则:左右子树的高度差的绝对值不能超过1。为了达到平衡,平衡二叉树引入了左旋和右旋的操作来维持树的平衡
- B树:多路查找树,满足平衡二叉树的规则同时每个跟节点可以有多个子树,子树的数量取决于关键树的数量。减少二叉树的高度
- B+树在B树的基础上做了增强:B树的数据存储在每个节点上,但是B+树通过增加一定的冗余,在叶子节点维护所有数据,同时通过链表将所有数据进行连接,第二个B+树的子树数量是等于根节点的关键字数量的(遵循左闭右开)

若有收获,就点个赞吧
0 人点赞
