CAP&BASE
CAP
Consistence(一致性):所有节点访问同一份最新的数据副本
Availablity(可用性):非故障节点在合理的时间内返回合理的响应(不是错误或者超时的响应)
Partition Tolerance(分区容错性):分布式系统出现网络分区的时候,仍然能够对外提供服务
网络分区:分布式系统种,多个节点的网络本来是连通的,但是因为某些故障(比如部分节点网络出现了问题),导致某些节点之间不连通了,出现了几块分区,这就叫网络分区

CAP 理论中分区容错性 P 是一定要满足的,在此基础上,只能满足可用性 A 或者一致性 C。
这个可以防止分布式系统出现脑裂,例如在dubbo中就是采用过半同意选举leader
- ZooKeeper 保证的是 CP。 任何时刻对 ZooKeeper 的读请求都能得到一致性的结果,但是, ZooKeeper 不保证每次请求的可用性比如在 Leader 选举过程中或者半数以上的机器不可用的时候服务就是不可用的。
- Eureka 保证的则是 AP。 Eureka 在设计的时候就是优先保证 A (可用性)。在 Eureka 中不存在什么 Leader 节点,每个节点都是一样的、平等的。因此 Eureka 不会像 ZooKeeper 那样出现选举过程中或者半数以上的机器不可用的时候服务就是不可用的情况。 Eureka 保证即使大部分节点挂掉也不会影响正常提供服务,只要有一个节点是可用的就行了。只不过这个节点上的数据可能并不是最新的。
- Nacos 不仅支持 CP 也支持 AP。
如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA
BASE理论
- Basically Available(基本可用) 、Soft-state(软状态) 和 Eventually Consistent(最终一致性)
- base理论是对CAP理论中C和A的权衡
- 核心思想:即使无法做到强一致性,但每个应用都可以根据自身业务的特点,采用适当的方式来使系统达到最终一致性。
也就是牺牲数据的一致性来满足系统的高可用性,系统中一部分数据不可用或者不一致时,仍需要保持系统整体“主要可用”。
1. 基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。但是,这绝不等价于系统不可用。
什么叫允许损失部分可用性呢?响应时间上的损失: 正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3 s。
- 系统功能上的损失:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的部分非核心功能无法使用。
2. 软状态
软状态指允许系统中的数据存在中间状态(CAP 理论中的数据不一致),并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。3. 最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。分布式一致性的三种级别:
- 强一致性 :系统写入了什么,读出来的就是什么。
- 弱一致性 :不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
- 最终一致性 :弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。
Paxos算法
Paxos 不是一致性算法而是共识算法,一致性和共识并不是一个概念。
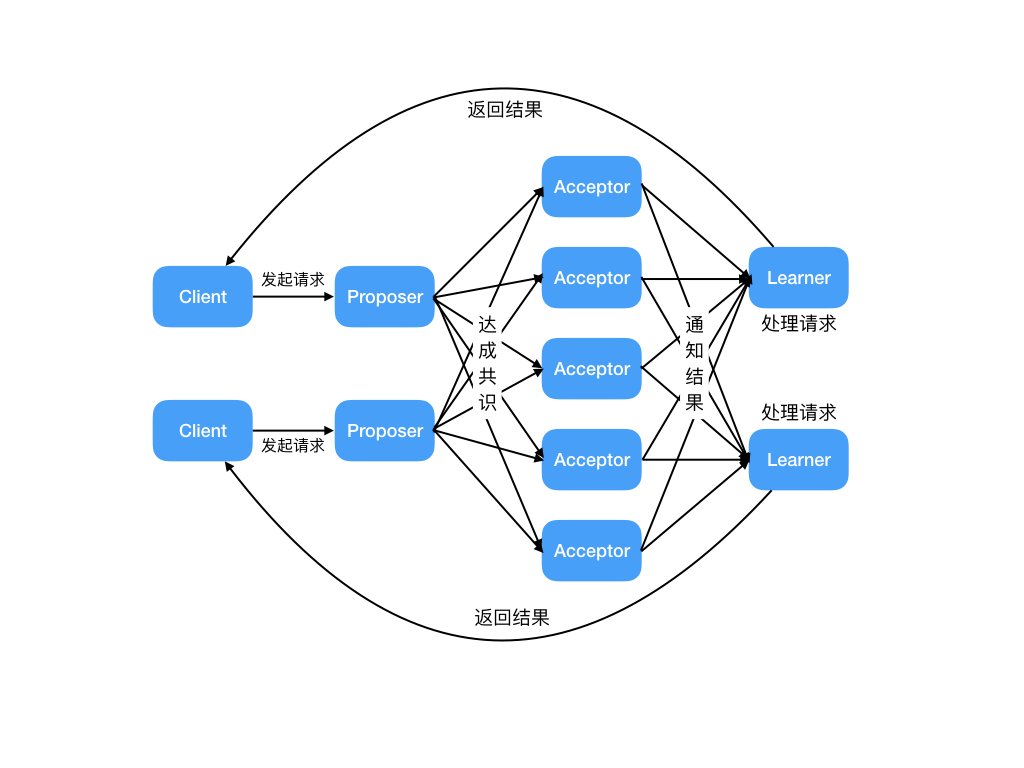
Basic Paxos 中存在 3 个重要的角色:
- 提议者(Proposer):也可以叫做协调者(coordinator),提议者负责接受客户端发起的提议,然后尝试让接受者接受该提议,同时保证即使多个提议者的提议之间产生了冲突,那么算法都能进行下去;
- 接受者(Acceptor):也可以叫做投票员(voter),负责对提议者的提议投票,同时需要记住自己的投票历史;
- 学习者(Learner):如果有超过半数接受者就某个提议达成了共识,那么学习者就需要接受这个提议,并就该提议作出运算,然后将运算结果返回给客户端。
Raft算法
拜占庭将军问题
先在所有的将军中选出一个大将军,用来做出所有的决定。
举例如下:假如现在一共有 3 个将军 A,B 和 C,每个将军都有一个随机时间的倒计时器,倒计时一结束,这个将军就把自己当成大将军候选人,然后派信使传递选举投票的信息给将军 B 和 C,如果将军 B 和 C 还没有把自己当作候选人(自己的倒计时还没有结束),并且没有把选举票投给其他人,它们就会把票投给将军 A,信使回到将军 A 时,将军 A 知道自己收到了足够的票数,成为大将军。在有了大将军之后,是否需要进攻就由大将军 A 决定,然后再去派信使通知另外两个将军,自己已经成为了大将军。如果一段时间还没收到将军 B 和 C 的回复(信使可能会被暗杀),那就再重派一个信使,直到收到回复。
共识算法
即使面对故障,服务器也可以在共享状态上达成一致。
共识算法允许一组节点像一个整体一样一起工作,即使其中的一些节点出现故障也能够继续工作下去,其正确性主要是源于复制状态机的性质:一组Server的状态机计算相同状态的副本,即使有一部分的Server宕机了它们仍然能够继续运行。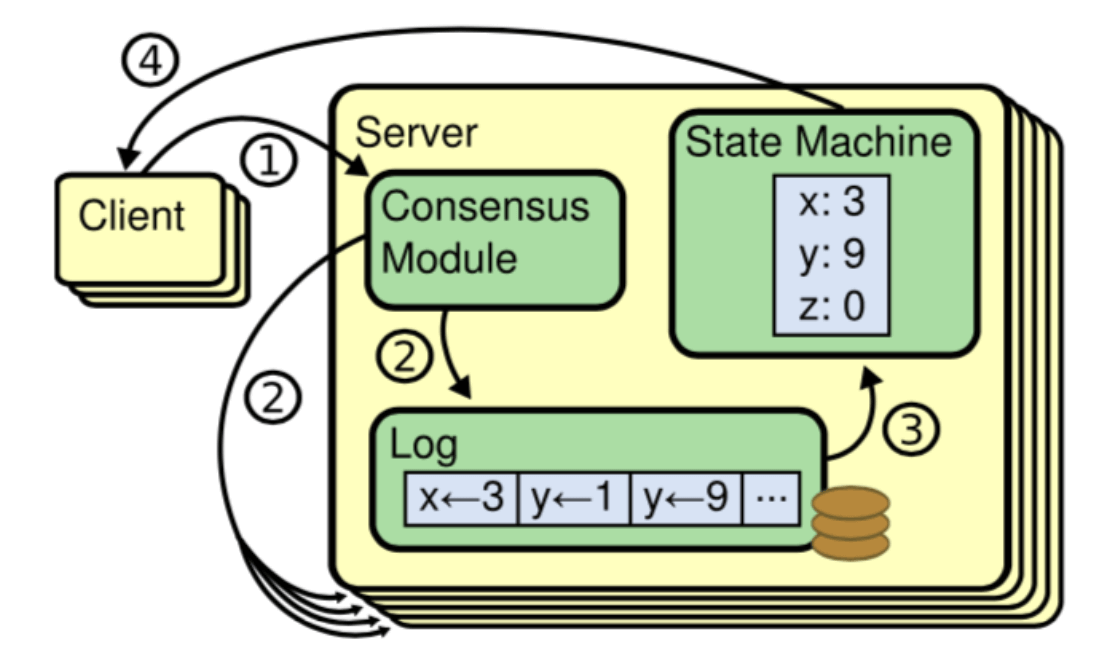
网关
一个系统被拆分为多个服务,但是像安全认证,流量控制,日志,监控等功能是每个服务都需要的,没有网关的话,我们就需要在每个服务中单独实现,这使得我们做了很多重复的事情并且没有一个全局的视图来统一管理这些功能。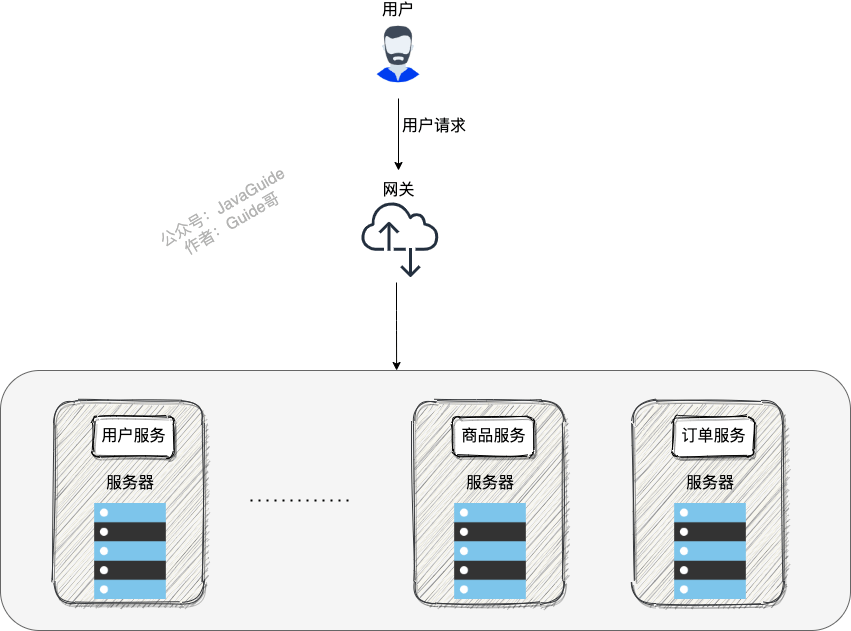

若有收获,就点个赞吧
0 人点赞
