- 全局唯一 :ID 的全局唯一性肯定是首先要满足的!
- 高性能 : 分布式 ID 的生成速度要快,对本地资源消耗要小。
- 高可用 :生成分布式 ID 的服务要保证可用性无限接近于 100%。
- 方便易用 :拿来即用,使用方便,快速接入!
除了这些之外,一个比较好的分布式 ID 还应保证:
- 安全 :ID 中不包含敏感信息。
- 有序递增 :如果要把 ID 存放在数据库的话,ID 的有序性可以提升数据库写入速度。并且,很多时候 ,我们还很有可能会直接通过 ID 来进行排序。
- 有具体的业务含义 :生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)。
- 独立部署 :也就是分布式系统单独有一个发号器服务,专门用来生成分布式 ID。这样就生成 ID 的服务可以和业务相关的服务解耦。不过,这样同样带来了网络调用消耗增加的问题。总的来说,如果需要用到分布式 ID 的场景比较多的话,独立部署的发号器服务还是很有必要的
常见分布式ID
| 名称 | 介绍 | 优点 | 缺点 |
|---|---|---|---|
| UUID | 生成全局唯一ID | 一行代码搞定,生成逻辑简单 | 无序字符串,不具备自增性 没有具体的业务逻辑 长度过长,存储和查询成本大 |
| 基于数据库的自增ID | 对于插入数据时自增 | ID单调自增,简单 查询速度快 |
存在单点宕机风险 |
| 基于数据库的集群模式 | 解决上述方案的单点故障问题: 设置起始值和自增步长 |
解决单点故障 | 不利于后续扩容 |
| 基于数据库的号段模式 | 批量获取ID存入内存中,滴滴开源框架Tinyid | ID有序递增,存储空间小 | 单点宕机 |
| 基于redis模式 | 利用redis的自增主键实现ID的原子性自增 | RDB持久化或者AOF持久化可能出现重复的情况 | |
| 基于雪花算法 | 专门用于分布式ID生成算法 |
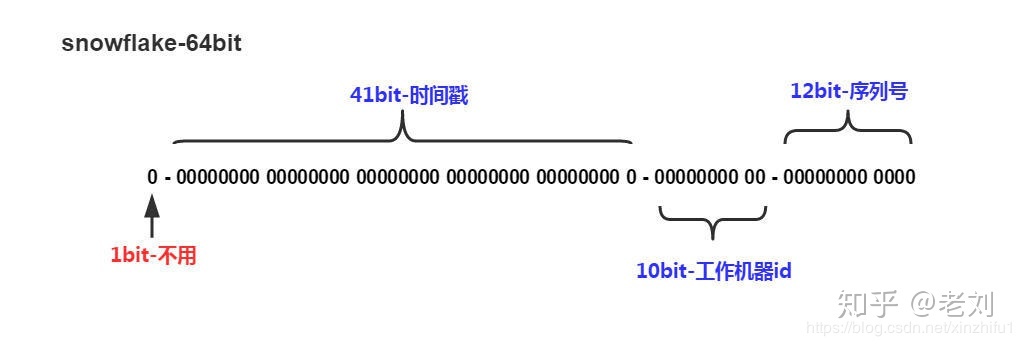
雪花算法

若有收获,就点个赞吧
0 人点赞
