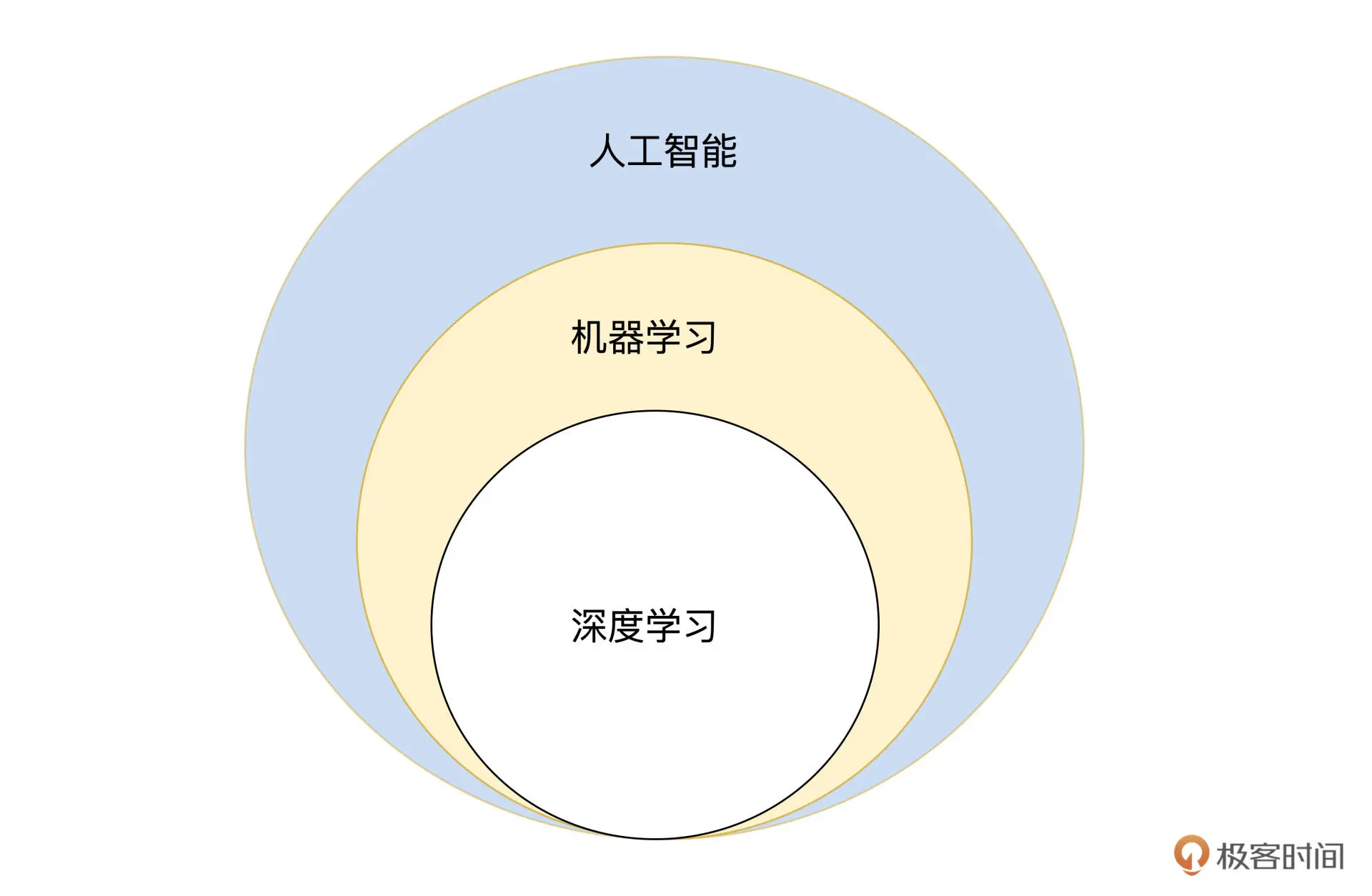
基本概念
机器学习开发的步骤:
1.数据处理:主要包括数据清理、数据预处理、数据增强等,就是构建让模型使用的训练集与测试集。
2.模型训练:确定网络结构、损失函数、优化方法。
3.模型评估:使用各种评估指标来评估模型的好坏。
其中,模型训练部分又分为以下几步:
1.确定网络结构:机器学习中回归算法、SVM等,深度学习中的VGG、ResNet、SENet等各种网络结构。
2.确定损失函数:损失函数衡量的是当前模型预测结果与真实标签之间的差距。
3.确定优化方法:与损失函数搭配,更新模型中的参数。
环境搭建
- 安装python和pip
- 安装pytorch:pip install torch
- 验证pytorch:在terminal中输入python,进入repl,输入import torch,回车没有报错就说明已经装好了
- 安装jupyter notebook:pip install jupyter
numpy
数组库。
安装:pip install numpy
numpy数组的特点:
- 长度不可变
- 元素的类型必须一致
- 计算速度快,内存占用少
以下的API对numpy做了别名:import numpy as np
| API | 用途 | 参数 | 示例 |
|---|---|---|---|
| np.asarray() | 创建数组,浅拷贝 | 数组, [数据类型] | np.asarray([[1, 2], [3, 4]]) |
| np.array() | 创建数组,深拷贝 | 数组, [数据类型] | np.array([[1, 2], [3, 4]]) |
| np.ones() | 创建数组,元素全为1 | 形状 | np.ones(shape=(2,3)) |
| np.zeros() | 创建数组,元素全为0 | 形状 | np.zeros(shape=(2,3)) |
| np.arange() | 创建数组,元素是一个序列 | [start, ]stop, [step, ] | np.arange(5) # array([0, 1, 2, 3, 4]) |
| np.linspace() | 创建数组,元素是一个序列 | start, stop, num=50 | np.linspace(start=2, stop=10, num=3) # array([ 2., 6., 10.]) |
| a.view() | 浅拷贝 | ||
| a.copy() | 深拷贝 | ||
| a.ndim | 数组的维度 | a.ndim # 2 | |
| a.shape | 数组的形状,即各维度上的长度 | a.shape # (2, 2) | |
| a.reshape() | 改变数组的形状 | 表示形状的元组 | a.reshape((4, 1)) |
| a.size | 数组中元素的个数 | ||
| a.dtype | 数组中元素的类型,⚠️不要设置这个属性 | a.dtype # dtype(‘int64’) | |
| a.astype() | 返回一个改变了元素数据类型后的新数组 | 元素数据类型 | a.astype(‘int32’) |
| a.sum() | 求和 | 数组, 轴 | np.sum(arr_2d, axis=0) # [2, 3, 4] |
| a.mean() | 求平均值 | 轴 | arr_2d.mean(axis=0) # [2, 3, 4] |
| a.max() | 求最大值 | 轴 | |
| a.min() | 求最小值 | 轴 | |
| a.argmax() | 求最大值下标 | 轴 | |
| a.argmin() | 求最小值下标 | 轴 | |
| np.argsort() | 排序,返回排序后的索引数组 | 数组,轴 | |
| a[:, :, 0] | 索引(降维) | ||
| a = a[:, :, np.newaxis] | 升维 | ||
| a[:, :, 0:1] | 切片 | ||
| np.concatenate() | 拼接,维度不变 | (a1, a2, …), axis=0 |
pillow
图片处理库。
pillow提供了广泛的文件格式支持,强大的图像处理能力,主要包括图像储存、图像显示、格式转换以及基本的图像处理操作等。
安装:pip install pillow
from PIL import Imageim = Image.open('jk.jpg')im.size # (318, 116)
提取图片的RGB通道
# pillow方式读取图片
from PIL import Image
im = Image.open('jk.webp') # 读取图片文件
import numpy as np
im_pillow = np.asarray(im) # 转换成numpy类型
im_pillow_c1 = im_pillow[:, :, 0] # 提取RGB通道
im_pillow_c2 = im_pillow[:, :, 1]
im_pillow_c3 = im_pillow[:, :, 2]
zeros = np.zeros((im_pillow.shape[0], im_pillow.shape[1], 2)) # 构建单通道图片
im_pillow_c1 = im_pillow_c1[:, :, np.newaxis] # 将2维数组升成3维数组
im_pillow_c1_3ch = np.concatenate((im_pillow_c1, zeros), axis=2) # 拼接R通道
im_pillow_c2_3ch = np.zeros(im_pillow.shape) # G、B通道使用赋值的方式构建
im_pillow_c2_3ch[:,:,1] = im_pillow_c2
im_pillow_c3_3ch = np.zeros(im_pillow.shape)
im_pillow_c3_3ch[:,:,2] = im_pillow_c3
# 展示通道
from matplotlib import pyplot as plt
plt.subplot(2, 2, 1)
plt.title('Origin Image')
plt.imshow(im_pillow)
plt.axis('off')
plt.subplot(2, 2, 2)
plt.title('Red Channel')
plt.imshow(im_pillow_c1_3ch.astype(np.uint8))
plt.axis('off')
plt.subplot(2, 2, 3)
plt.title('Green Channel')
plt.imshow(im_pillow_c2_3ch.astype(np.uint8))
plt.axis('off')
plt.subplot(2, 2, 4)
plt.title('Blue Channel')
plt.imshow(im_pillow_c3_3ch.astype(np.uint8))
plt.axis('off')
plt.savefig('./rgb_pillow.png', dpi=150)

OpenCV
图片处理库。
演示如何提取图片的RGB通道:
# cv2方式读取图片
import cv2
im_cv2 = cv2.imread('jk.webp') # 读取图片文件,直接得到numpy类型,不需要转换
# 反转通道顺序,cv2读取图片后通道顺序是BGR,在这里逆转一下顺序
im_cv2_copy = im_cv2.copy() # 深拷贝
im_cv2_copy[:, :, 0] = im_cv2[:, :, 2]
im_cv2_copy[:, :, 2] = im_cv2[:, :, 0]
im_cv2 = im_cv2_copy
# 提取通道
im_cv2_c1_3ch = im_cv2.copy()
im_cv2_c1_3ch[:, :, 1:] = 0
im_cv2_c2_3ch = im_cv2.copy()
im_cv2_c2_3ch[:, :, 0] = 0
im_cv2_c2_3ch[:, :, 2] = 0
im_cv2_c3_3ch = im_cv2.copy()
im_cv2_c3_3ch[:, :, :1] = 0
# 展示通道
from matplotlib import pyplot as plt
plt.subplot(2, 2, 1)
plt.title('Origin Image')
plt.imshow(im_cv2)
plt.axis('off')
plt.subplot(2, 2, 2)
plt.title('Red Channel')
plt.imshow(im_cv2_c1_3ch.astype(np.uint8))
plt.axis('off')
plt.subplot(2, 2, 3)
plt.title('Green Channel')
plt.imshow(im_cv2_c2_3ch.astype(np.uint8))
plt.axis('off')
plt.subplot(2, 2, 4)
plt.title('Blue Channel')
plt.imshow(im_cv2_c3_3ch.astype(np.uint8))
plt.axis('off')
plt.savefig('./rgb_cv2.png', dpi=150)

Tensor
张量,是包含了标量、向量、矩阵等等的一种数据结构,并提供了GPU加速能力
| API | 用途 | 参数 |
|---|---|---|
| torch.tensor() | 创建tensor 不要写成torch.Tensor() |
data:标量、元组、数组、np数组 dtype=None device=None requires_grad=False |
| torch.from_numpy() | 创建tensor,从np数组 | |
| torch.zeros() | 创建tensor,全0 | *size, dtype=None… |
| torch.ones() | 创建tensor,全1 | |
| torch.eye() | 创建tensor,单位矩阵 | |
| torch.rand() | 创建随机tensor,0-1均匀分布 | size |
| torch.randint() | 创建随机tensor,x-y均匀分布 | low, high, size |
| torch.randn() | 创建随机tensor,(0, 1)正态分布 | size |
| torch.normal() | 创建随机tensor,(x, y)正态分布 | mean, std, size |
| a.item() | torch => 标量 | |
| a.numpy() | torch => np | |
| a.numpy().tolist() | torch => 数组 | |
| a.shape | 获取tensor的形状 | |
| a.size() | 获取tensor的形状 | |
| a.numel() | 获取tensor的元素个数 | |
| a.permute() | 返回转置后的tensor,所有维度 | 形状下标 |
| a.transpose() | 返回转置后的tensor,两个维度 | 形状下标 |
| a.view() | 返回变形后的tensor,必须连续 | 形状 |
| a.reshape() | 返回变形后的tensor,不必连续 | 形状 |
| a.squeeze() | 降维,删除一个长度为1的维度 | 形状下标 |
| a.unsqueeze() | 升维,插入一个长度为1的维度 | 形状下标 |
| torch.cat() | 合并,维度不变 | (a1, a2…), 轴 |
| torch.stack() | 合并,升维 | (a1, a2…), 轴 |
| torch.chunk() | 拆分,维度不变 | a, 分几块, 轴 |
| torch.split() | 拆分,维度不变 | a, 每块长, 轴 |
| torch.unbind() | 拆分,降维 | a, 轴 |
| a[:, 1] | 索引,降维 | |
| a[:, 0:2] | 切片,维度不变 | |
| torch.index_select() | 过滤,维度不变 | tensor, dim, index |
| torch.masked_select() | 过滤,返回一维数组 | a, mask |
Torchvision
与pytorch配合使用的图片处理库,包括了常用数据集+常见网络模型+常用图像处理方法。Torchvision依赖pillow进行图片处理。
安装:pip install torchvision
Dataset抽象类
pytorch中的Dataset抽象类是对数据集的抽象
import torch
from torch.utils.data import Dataset
# 实现一个自定义的数据集类,继承Dataset
class MyDataset(Dataset):
# 构造函数
def __init__(self, data_tensor, target_tensor):
self.data_tensor = data_tensor
self.target_tensor = target_tensor
# 返回数据集大小,配合全局len()使用
def __len__(self):
return self.data_tensor.size(0)
# 返回索引的数据与标签,配合索引语法使用
def __getitem__(self, index):
return self.data_tensor[index], self.target_tensor[index]
# 生成数据
data_tensor = torch.randn(10, 3)
target_tensor = torch.randint(2, (10,)) # 标签是0或1
# 将数据封装成Dataset
my_dataset = MyDataset(data_tensor, target_tensor)
# 查看数据集大小
print('Dataset size:', len(my_dataset)) # Dataset size: 10
# 使用索引调用数据
print('tensor_data[0]: ', my_dataset[0])
DataLoader类
pytorch中的DataLoader类用于将Dataset中包含的数据加载到内存中,能够多进程、迭代地加载数据。本身是一个迭代器。
# DataLoader的用法
from torch.utils.data import DataLoader
tensor_dataloader = DataLoader(dataset=my_dataset, # 传入的数据集
batch_size=2, # 每次取几条数据
shuffle=True, # 数据是否打乱
num_workers=0) # worker进程数, 0表示只有主进程
# 以循环形式输出
for data, target in tensor_dataloader:
print(data, target)
# 输出一个batch,可以无限次调用
print('One batch tensor data: ', iter(tensor_dataloader).next())
数据读取
torchvision.datasets包提供的所有数据集参见:Datasets — Torchvision 0.12 documentation
这些数据集都是Dataset类的子类,可以被DataLoader处理。
MNIST是一个手写数字数据集,常用来进行深度学习的入门。
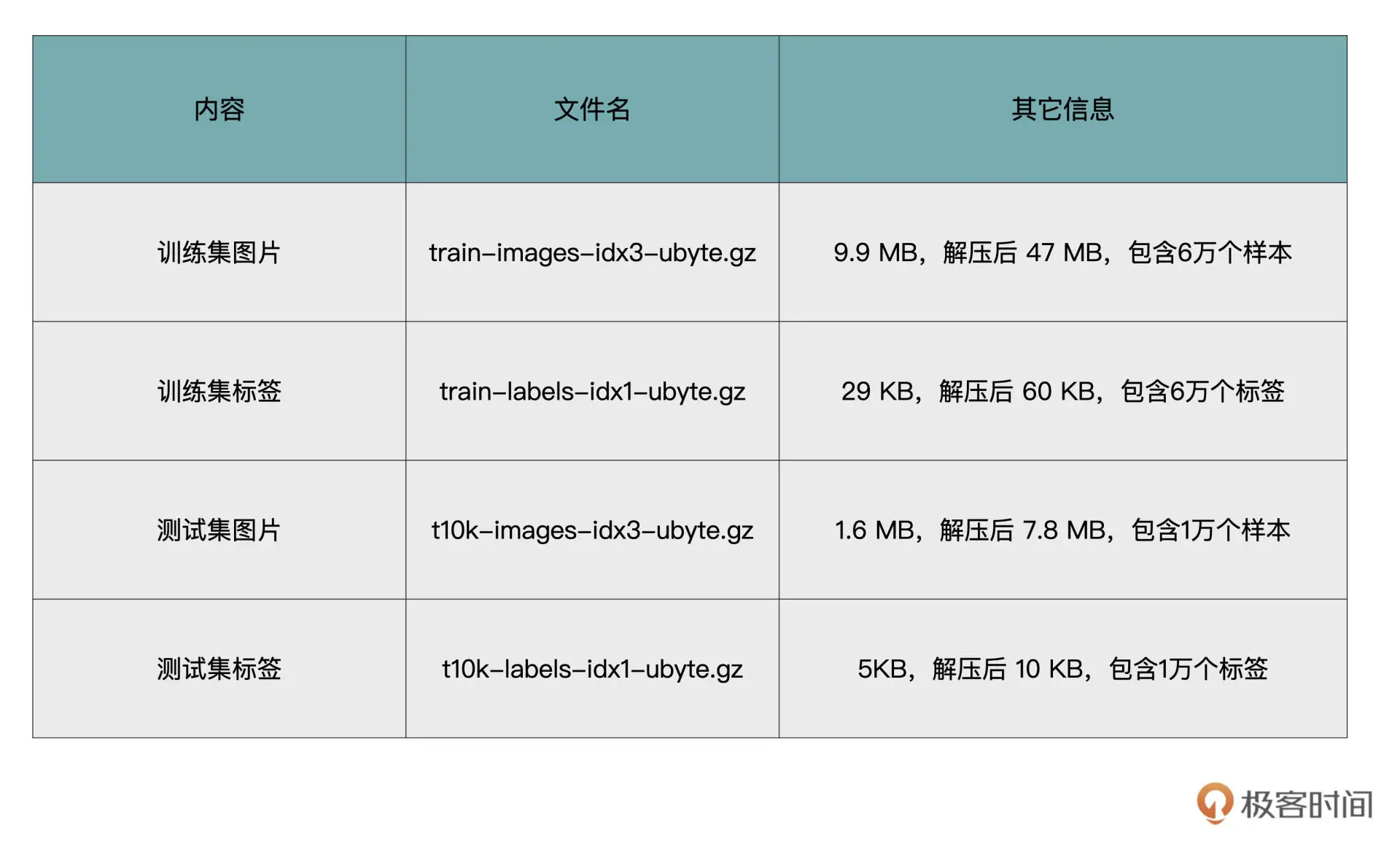
使用数据集api,完成对数据的下载、解压,返回值是Dataset类的子类实例。
使用torchvision.datasets的其他方法,即可下载其他数据集。
如果要使用官方数据集以外的自定义数据集,可以使用torchvision.datasets.ImageFolder
import torchvision
mnist_dataset = torchvision.datasets.MNIST(root='./data', # 文件保存目录
train=False, # 加载训练集 or 测试集
transform=None, # 图片预处理
target_transform=None, # 标签预处理
download=True) # 是否下载
mnist_dataset_list = list(mnist_dataset) # 将数据集转换成list
print(mnist_dataset_list) # [(图片数据, 标签)]
display(mnist_dataset_list[0][0]) # 显示第一张图片
print("Image label is:", mnist_dataset_list[0][1]) # 第一张图片的标签 7
数据转换
此时已经完成了图片的读取,但得到的是图片类型,接下来需要转换成tensor类型才能用于计算。
torchvision.transforms提供了类型转换的能力:
- transforms.ToTensor():图片 => tensor
- transforms.ToPILImage():tensor => 图片
还可以对图片和tensor进行以下处理:
- transforms.Resize():变形
- transforms.CenterCrop():中心剪裁
- transforms.RandomCrop():随机剪裁
- transforms.FiveCrop():中心和四角剪裁
- transforms.RandomHorizontalFlip(p=0.5):以概率p随机水平翻转
- transforms.RandomVerticalFlip(p=0.5):以概率p随机垂直翻转
只针对tensor的操作
- transforms.Normalize():归一化,减去通道平均值,再除以标准差。
以上的操作还可以串联起来:
- transforms.Compose(),组合后的操作可以传给datasets.MNIST等方法,在数据读取时就可以一并完成转换
网络模型
torchvision包含的网络模型可以完成四类任务:图像分类、物体检测、图像分割和视频分类
GoogLeNet是一个Google推出的基于Inception模块的深度神经网络模型。所有模型参见pytorch文档。
使用已经预训练的模型,再用自己的数据集进行微调,只训练最后的全连接层,可以快速得到一个效果较好的模型。这样比从头训练一个随机初始化的模型,速度更快而且效果更好。import torchvision.models as models # 初始化一个模型,参数都是随机的,需要训练后才能使用 googlenet = models.googlenet() # 或者使用ImageNet预训练的模型,可以直接使用;初次调用会下载模型参数 # 下载位置由TORCH_MODEL_ZOO来指定 googlenet = models.googlenet(pretrained=True)
预训练的googlenet模型是基于ImageNet数据集的,它有1000个分类。如果我们自己的任务只有10个分类,可以这样做: ```python import torch import torchvision.models as models
加载预训练模型
googlenet = models.googlenet(pretrained=True)
提取分类层的输入参数
fc_in_features = googlenet.fc.in_features print(“fc_in_features:”, fc_in_features) # fc_in_features: 1024
查看分类层的输出参数
fc_out_features = googlenet.fc.out_features print(“fc_out_features:”, fc_out_features) # fc_out_features: 1000
修改预训练模型的输出分类数
googlenet.fc = torch.nn.Linear(fc_in_features, 10)
torchvision.utils.make_grid()可以将图片拼接成网格,便于查看数据集
```python
import torchvision
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
# 加载MNIST数据集
mnist_dataset = datasets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor(),
target_transform=None,
download=True)
# 取32张图片的tensor
tensor_dataloader = DataLoader(dataset=mnist_dataset,
batch_size=32)
data_iter = iter(tensor_dataloader)
img_tensor, label_tensor = data_iter.next()
print(img_tensor.shape) # torch.Size([32, 1, 28, 28]) [batch大小,通道数,高,宽]
# 将32张图片拼接在一个网格中
grid_tensor = torchvision.utils.make_grid(img_tensor, nrow=8, padding=2)
print(grid_tensor.shape) # torch.Size([3, 122, 242])
grid_img = transforms.ToPILImage()(grid_tensor)
display(grid_img)

torchvision.utils.save_image()可以将tensor保存为图片文件,省去了将tensor转换成图片数据的步骤
# 输入为一张图片的tensor,直接保存,结果同上面的图片
torchvision.utils.save_image(grid_tensor, 'grid.jpg')
# 输入为List,调用grid_img函数后保存,结果如下图
torchvision.utils.save_image(img_tensor, 'grid2.jpg', nrow=5, padding=2)

卷积
卷积用于对图片进行特征提取。卷积具有两个特点:
- 稀疏连接:使参数的数量变得很少
- 平移不变性:图形的位置不影响计算结果
卷积的计算过程是,将输入特征图与卷积核做卷积计算(逐个相乘再相加),得到输出特征图中的一个元素。然后向右、向下移动计算区域,就可得出输出特征图中的每个元素。在下图的例子中,每次移动的步长(stride)为1,步长一般是1或2。
标准卷积
上面是最简单的情况,扩展到标准情况下后,输入特征图有m个通道,卷积核也有m个通道;每个卷积核在卷积计算后得到输出特征图的一个通道,n个卷积核就得到了输出特征图的n个通道: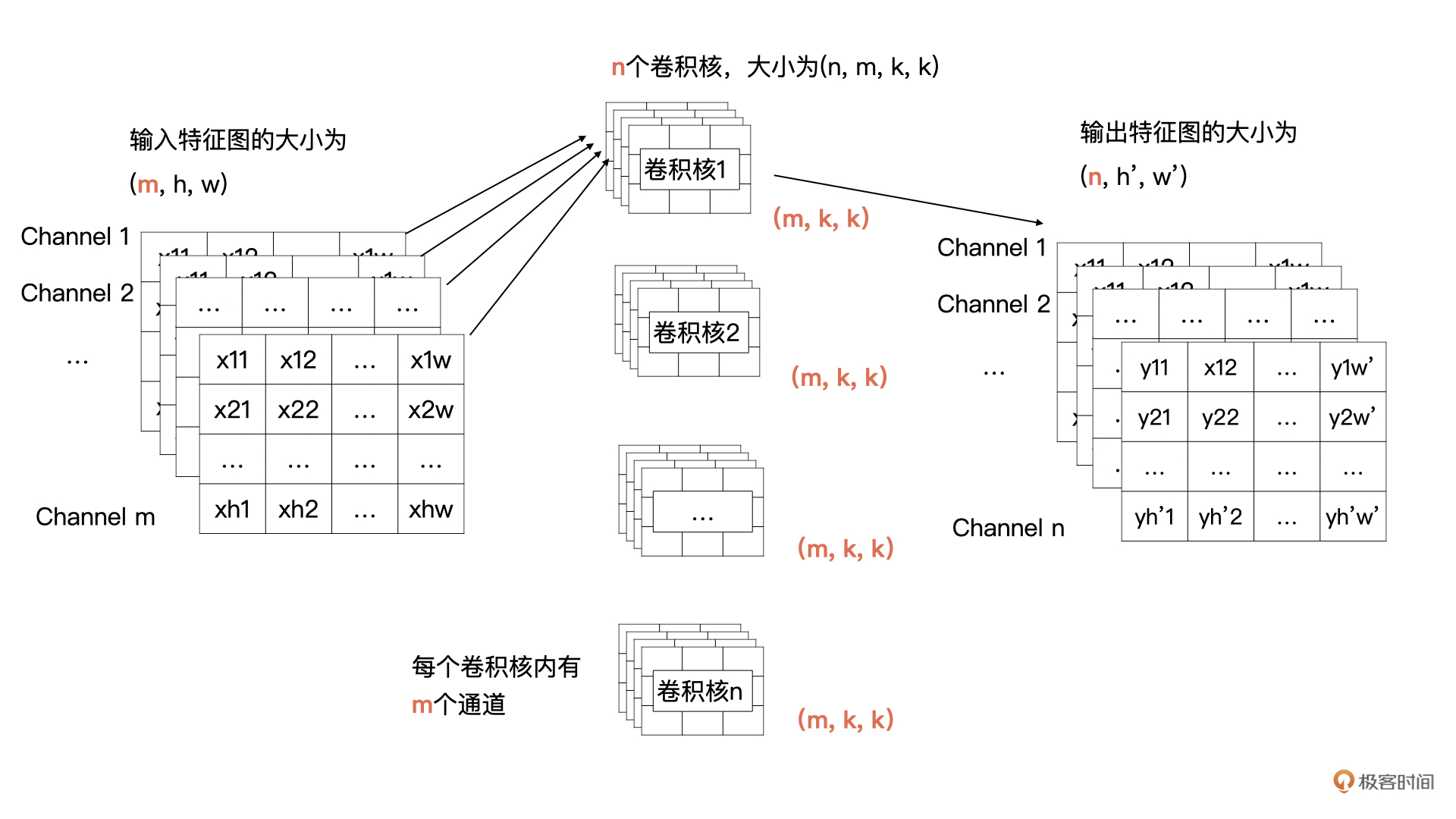
卷积操作会让特征图越来越小,为了避免或者减慢这种特征图变小的过程,可以做padding操作,就是在结果的周围补几圈0,或者在输入特征图中右侧和下方补0,使输出和输入一致。
import torch
import torch.nn as nn
# 输入特征图
# shape = (batch_size,通道数,高,宽)
a = [[4, 1, 7, 5], [4, 4, 2, 5], [7, 7, 2, 4], [1, 0, 2, 4]]
input = torch.tensor(a, dtype=torch.float32).unsqueeze(0).unsqueeze(0)
# 卷积操作
# 输入通道数1,输出通道数1,卷积核大小(2, 2),步长1,补0,加偏移
conv2d = nn.Conv2d(1, 1, (2, 2), stride=1, padding='same', bias=True)
# 输出特征图
# shape = (batch_size,通道数,高,宽)
output = conv2d(input)
深度可分离卷积
深度可分离卷积(Depthwise Separable Convolution)体积小、速度快、精度稍低,适合用在移动端。
第一步是Depthwise(DW)卷积
第二步是Pointwise(PW)卷积
使用深度可分离卷积的话,计算量只有标准卷积的1/k^2
通过nn.Conv2d的groups参数可以实现DW,即对输入特征图进行分组卷积,groups即为通道数
import torch
import torch.nn as nn
# 生成一个3通道的5*5特征图
input_feat = torch.rand((3, 5, 5)).unsqueeze(0)
print(input_feat.shape) # torch.Size([1, 3, 5, 5])
# 请注意DW中,输入特征通道数与输出通道数是一样的
in_channels_dw = input_feat.shape[1]
out_channels_dw = input_feat.shape[1]
# 一般来讲DW卷积的kernel_size为3
kernel_size = 3
# DW卷积groups参数与输入通道数一样
dw = nn.Conv2d(
in_channels_dw,
out_channels_dw,
kernel_size,
groups=in_channels_dw)
# 然后创建PW卷积
in_channels_pw = out_channels_dw
out_channels_pw = 4
kernel_size_pw = 1
pw = nn.Conv2d(in_channels_pw, out_channels_pw, kernel_size_pw, stride)
output = pw(dw(input_feat))
print(output.shape) # torch.Size([1, 4, 3, 3])
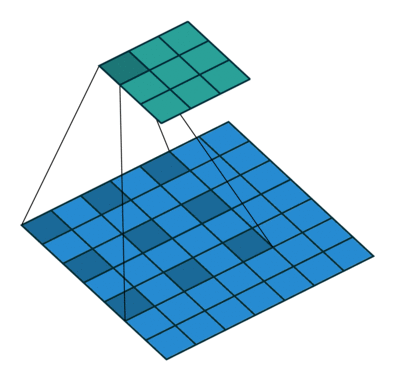
空洞卷积
既保证有比较大的感受野,同时又不用缩小特征图,用于图像分割任务,动图参见github。
通过nn.Conv2d的dilation参数来实现空洞卷积。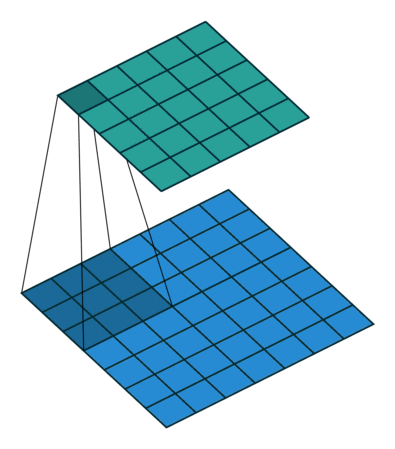
损失函数
单个样本点上,模型预测值和真实值之间的误差,称为损失函数。
模型学习的过程,就是让损失函数值不断减少的过程。
以平方损失函数为例:
所有样本点的误差平均值,称为代价函数。
设真实值为F(x),模型预测值为f(x),一些常用的损失函数有:
- 0-1损失函数:预测值与真实值相等时为0,不相等时为1

- 平方损失函数
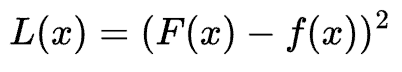
- 均方差损失函数(Mean Squared Error,MSE)
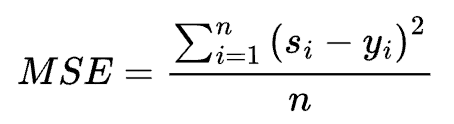
s为目标值的向量表示,y为预测值的向量表示。
- 平均绝对误差损失函数(Mean Absolute Error,MAE)
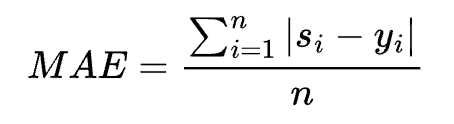
- 交叉熵损失函数(Cross entropy loss)

- softmax函数:用于将输入映射到0-1之间
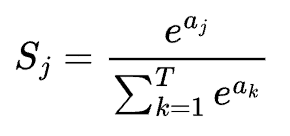
- sigmoid函数
梯度、前向传播、反向传播
前向传播:输入数据逐层、单向地经过各层,最终达到输出层。
导数: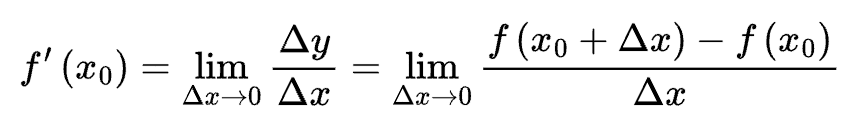
偏导数:
梯度,即函数所有偏导数构成的向量: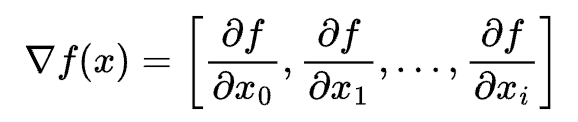
梯度向量的方向即为函数值增长最快的方向,所以模型学习的过程就是沿着损失函数的梯度的相反方向进行,即损失函数减少最快的方向,最终达到损失函数的最小值。
我们的目标是计算损失函数的梯度: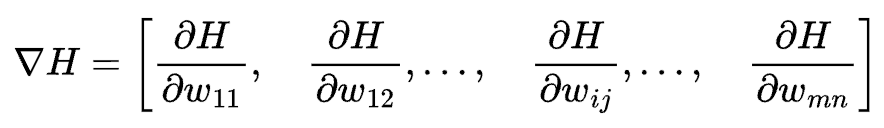
wij表示第i层的第j个节点对应的权重值
但损失函数的表达式可能很复杂,为了简化求导运算,我们需要借助链式法则:两个函数组合起来的复合函数,导数等于内层函数代入外层函数值的导数,乘以内层函数的导数。可表述为:
或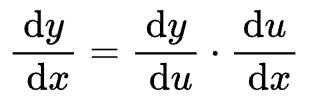
例如,对于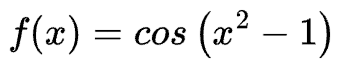
可以分解为 f(x)=cos (x) 和 g(x)=x2-1
其中, f(x)=cos (x) 的导数是 f(x)=-sin(x),g(x)=x2-1 的导数是 g(x) = 2x,所以原函数的导数是: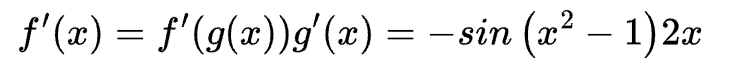
反向传播算法(Backpropagation)是目前训练神经网络最常用且最有效的算法。其基本过程是:
- 前向传播:数据逐步经过输入层、隐藏层、输出层。
- 计算误差并传播:计算模型输出结果和真实结果之间的误差,并将这种误差通过某种方式反向传播,即从输出层向隐藏层传递并最后到达输入层。
迭代:在反向传播的过程中,根据误差不断地调整模型的参数值,并不断地迭代前面两个步骤,直到达到模型结束训练的条件。
优化方法
优化方法:将误差反向传播并调整模型参数,使模型效果达到最优的过程。
主要有三种优化方法:批量梯度下降法(Batch Gradient Descent,BGD),使用训练集的全部数据,效率较低
- 随机梯度下降(Stochastic Gradient Descent,SGD),每次使用一条数据,容易陷于局部最优
- 小批量梯度下降(Mini-Batch Gradient Descent, MBGD),对前两者的折中,最常用
模型搭建和训练
下面以线性回归为例,演示模型的搭建和训练过程 ```python首先构建训练用的数据
import numpy as np import random from matplotlib import pyplot as plt
w = 2 # weight b = 3 # bias xlim = [-10, 10] x_train = np.random.randint(low=xlim[0], high=xlim[1], size=30) # 训练集
y_train = [w * x + b + random.randint(0,2) for x in x_train] # 标签
plt.plot(x_train, y_train, ‘bo’)
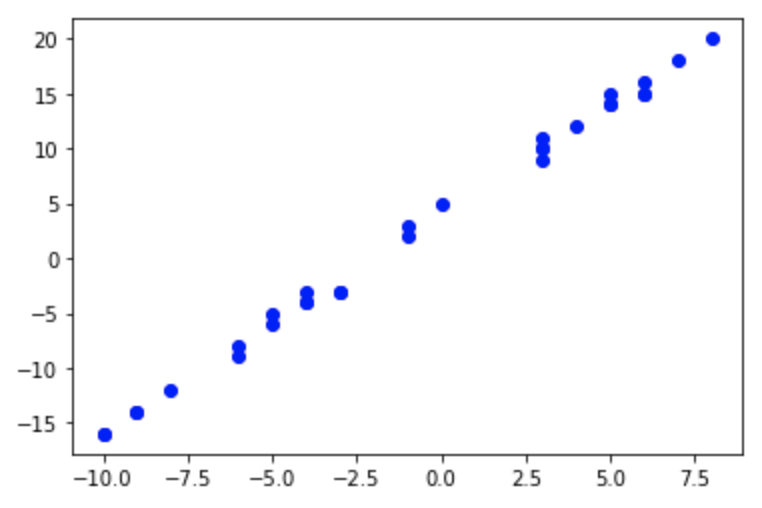
```python
import torch
from torch import nn
# 定义模型,需要继承nn.Module类
class LinearModel(nn.Module):
# 构造函数,需要学习参数的层要放在这里
def __init__(self):
super().__init__() # 必须先调用父类的构造方法
self.weight = nn.Parameter(torch.randn(1)) # nn.Parameter()返回可训练的参数
self.bias = nn.Parameter(torch.randn(1))
# 前向传播,提供输出;该类的实例是一个函数,被调用时就会调用forward()
def forward(self, input):
return (input * self.weight) + self.bias
# 实例化模型
model = LinearModel()
# 优化方法选择SGD
optimizer = torch.optim.SGD(
model.parameters(),
lr=1e-4,
weight_decay=1e-2,
momentum=0.9
)
y_train = torch.tensor(y_train, dtype=torch.float32)
# 训练1000个Epoch
for _ in range(1000):
input = torch.from_numpy(x_train)
output = model(input)
loss = nn.MSELoss()(output, y_train) # 损失函数使用MSE
model.zero_grad()
loss.backward()
optimizer.step()
for parameter in model.named_parameters():
print(parameter)
# 输出:
# ('weight', Parameter containing:
# tensor([1.9803], requires_grad=True))
# ('bias', Parameter containing:
# tensor([3.4471], requires_grad=True))
至此就完成了模型的训练,得出了模型的参数。
模型中反复出现的部分,还可以提取成子模型,供其他模型调用。
训练好的模型可以保存起来,供以后使用。我们可以只保存参数:
# 保存模型参数到一个pth文件
torch.save(model.state_dict(), './linear_model.pth')
# 重新实例化一个模型
linear_model = LinearModel()
# 加载保存的参数
linear_model.load_state_dict(torch.load('./linear_model.pth'))
linear_model.eval() # 使模型进入测试状态
for parameter in linear_model.named_parameters():
print(parameter)
# 输出:
# ('weight', Parameter containing:
# tensor([1.9803], requires_grad=True))
# ('bias', Parameter containing:
# tensor([3.4471], requires_grad=True))
还可以把模型和参数都保存起来:
# 保存整个模型
torch.save(model, './linear_model_with_arc.pth')
# 加载模型,不需要创建网络了
linear_model_2 = torch.load('./linear_model_with_arc.pth')
linear_model_2.eval()
for parameter in linear_model_2.named_parameters():
print(parameter)
# 输出:
# ('weight', Parameter containing:
# tensor([1.9803], requires_grad=True))
# ('bias', Parameter containing:
# tensor([3.4471], requires_grad=True))
在实际开发中,基本上不需要自己搭建网络,一般都是使用torchvision内置的网络,在其基础上做微调来加快收敛速度。这里使用的微调方式是,修改全连接层输出的数目,使用预训练模型的参数作为初始化参数,重新训练整个网络。以AlexNet为例:
# 首先,导入网络
import torchvision.models as models
alexnet = models.alexnet(pretrained=True)
# 然后,验证模型是否正确加载
from PIL import Image
import torchvision
import torchvision.transforms as transforms
im = Image.open('corgi.jpg') # 一张柯基的图片
transform = transforms.Compose([
transforms.RandomResizedCrop((224,224)),
transforms.ToTensor(),
# imageNet要求的标准化方式
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
input_tensor = transform(im).unsqueeze(0) # imageNet要求的形状,增加了batch的维度
alexnet(input_tensor).argmax() # 263,对应柯基的标签
输出263说明模型已经正确加载,下面来做微调。torchvision内置的模型都是基于imageNet训练的,有1000个类别,我们现在使用的alexnet同样也是。如果我们想将这个模型应用在CIFAR-10数据集上(只有10个类别),那么我们需要将模型最后的全连接层输出修改为10,并重新训练模型:
print(alexnet) # 最后的全连接层输出为1000个单元
# AlexNet(
# ...
# (classifier): Sequential(
# ...
# (6): Linear(in_features=4096, out_features=1000, bias=True)
# ...
# 提取分类层的输入参数
fc_in_features = alexnet.classifier[6].in_features
# 修改预训练模型的输出分类数为10
alexnet.classifier[6] = torch.nn.Linear(fc_in_features, 10)
# 加载CIFAR-10数据
transform = transforms.Compose([
transforms.RandomResizedCrop((224,224)), # torchvision最小训练尺寸
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
cifar10_dataset = torchvision.datasets.CIFAR10(root='./data',
train=False,
transform=transform,
target_transform=None,
download=True)
dataloader = DataLoader(
dataset=cifar10_dataset, # 传入的数据集, 必须参数
batch_size=32, # 输出的batch大小
shuffle=True, # 数据是否打乱
num_workers=2 # worker进程数, 0表示只有主进程
)
# 优化器
optimizer = torch.optim.SGD(
alexnet.parameters(),
lr=1e-4,
weight_decay=1e-2,
momentum=0.9
)
# 训练3个Epoch
for epoch in range(3):
for item in dataloader:
output = alexnet(item[0]) # 预测值
target = item[1] # 真实值
loss = nn.CrossEntropyLoss()(output, target) # 使用交叉熵损失函数
print('Epoch {}, Loss {}'.format(epoch + 1 , loss))
alexnet.zero_grad()
loss.backward()
optimizer.step()
# Epoch 1, Loss 2.3692712783813477
# Epoch 1, Loss 2.2741799354553223
# ...
# Epoch 1, Loss 1.3783353567123413
# Epoch 2, Loss 1.33861243724823
# ...
# Epoch 2, Loss 0.5767470598220825
# Epoch 3, Loss 1.2658960819244385
# ...
# Epoch 3, Loss 1.0122954845428467 结束
训练过程可视化监控
通过可视化可以在模型训练的过程中监控参数、评价指标等。下面介绍Tensorboard和Visdom
Tensorboard
Tensorboard是TensorFlow内置的可视化工具,为了与pytorch配合使用,我们需要TensorboardX的帮助。pytorch 1.8版本之后自带TensorboardX,无需安装。
# 安装tensorboard
pip install tensorboard
使用Tensorboard时,首先将训练过程中产生的数据写到日志文件中,然后再从浏览器页面读取并绘制这些数据。(数据有更新时,只能手动刷新页面么?)
首先将训练过程的数据写到日志文件中:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
# 创建一个SummaryWriter的实例
# 负责在日志中写入数值或图像
# 可选参数是日志保存的位置,默认./runs/当前时间_主机名
writer = SummaryWriter()
# 写入数据
for step in range(100):
# 参数为数据名称,数值,步数
writer.add_scalar('Loss/train', np.random.random(), step)
writer.add_scalar('Loss/test', np.random.random(), step)
writer.add_scalar('Accuracy/train', np.random.random(), step)
writer.add_scalar('Accuracy/test', np.random.random(), step)
# 构建一张图片
img = np.zeros((3, 100, 100))
img[0] = np.arange(0, 10000).reshape(100, 100) / 10000
img[1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
# 写入图片,参数为数据名称,数值,步数
writer.add_image('my_image', img, 0)
writer.close()
然后在终端启动Tensorboard:
tensorboard —logdir=runs
最后在浏览器中打开http://localhost:6006,就可以看到刚才写入的数据和图片了。
前面的alexnet微调的例子可以得到下面的收敛过程:(2个epoch)
Visdom
Visdom是Facebook开源的一个专门用于PyTorch的交互式可视化工具。
# 安装
pip install visdom
# 运行
python3 -m visdom.server
打开http://localhost:8097,即可进入Visdom的界面。Visdom不需要Tensorboard那样先写日志文件再绘制,启动服务开始训练后直接就可以看到图形,而且当数据更新时页面会自动更新👍
# visdom
from visdom import Visdom
import numpy as np
import time
# 1. 将窗口类实例化
viz = Visdom()
# 2. 创建窗口并初始化,创建折线图
viz.line([0.], [0], win='train_loss', opts=dict(title='train_loss'))
# 更新折线图
for n_iter in range(10):
# 随机获取loss值
loss = 0.2 * np.random.randn() + 1
# 3. 更新窗口图像
viz.line([loss], [n_iter], win='train_loss', update='append')
time.sleep(0.5)
# 创建图像
img = np.zeros((3, 100, 100))
img[0] = np.arange(0, 10000).reshape(100, 100) / 10000
img[1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
# 展示图像
viz.image(img)


分布式训练
分布式的目的是提高训练速度。
可以将数据和模型“分布”。
有两个相关的API:
- DP,即torch.nn.DataParallel:
- 适用于单机多卡。
- 单进程。
- 数据均分到各个GPU。
- 在网络前向传播时,模型会从主GPU复制到其它GPU上,但会有一个主GPU负责计算所有的loss。
- 在反向传播时,每个GPU上的梯度会汇总到主GPU上,求得梯度均值更新模型参数后,再复制到其它GPU,以此来实现并行。会有负载不均衡的问题。
- DDP,即torch.nn.DistributedDataParallel:
- 既能用于单机多卡,也能用于多机多卡,是更推荐的方式。
- 为每个GPU创建一个进程。每个GPU角色相同,不分主从。
- 使用分布式数据采样器(DistributedSampler)加载数据,确保数据在各个进程之间没有重叠。
- 反向传播时,各GPU梯度计算完成后进行广播,然后每个进程在各自的GPU上进行梯度更新。
DDP的训练过程:
- 初始化进程组
- torch.distributed.init_process_group
- 模型并行化:将模型分发到各主机
- torch.nn.parallel.DistributedDataParallel
- 创建分布式数据采样器:每个主机从硬盘上的数据集中挑选出自己负责的那部分数据



- VGG
- 证明了随着模型深度的增加,模型效果也会越来越好。
- 使用较小的3x3卷积核,代替了AlexNet中的11x11、7x7以及5x5的大卷积核。
- GoogLeNet
- 考虑到物体在图片中占比不同,使用了不同大小的卷积核来提取特征。
- 使用了1x1卷积来降维,以降低计算成本。
ResNet
分类
- 情感分析:判断文本是好评还是差评,基于LSTM网络(在RNN基础上改进而来,RNN适合处理变长的、序列相关的数据)
- 文本分类:新闻是经济、社会、医疗还是体育,基于BERT。演进过程:统计 - 贝叶斯方法 - SVM(支持向量机) - LDA - BERT。BERT能够解决类别多、数据不平衡和多语言问题。
- 生成
- 摘要生成:基于BART
- 自动问答
- 机器翻译
分词可以使用jieba(结巴还行😭)
文本表示传统上使用One-hot,在深度学习领域则使用Word Embedding
关键词提取主要使用无监督学习,可以通过统计法、词图模型法和主题模型法来完成
注意力模型为文本中的不同部分分配了不同的注意力,来区分其重要程度。该领域最重要的论文是《Attention is All You Need》。BERT就是基于注意力模型。

若有收获,就点个赞吧
0 人点赞
