为了解决KNN算法的问题,我们现在开发一种新的算法,即线性分类。从线性分类开始我们将逐渐演进到神经网络,以及卷积神经网络。线性分类包含两个主要组件:
- 打分函数:将图像映射到一组类别概率得分
- 损失函数:量化预测值与真实值的偏差
这样就将分类问题转换成了一个优化问题:调整打分函数的参数,使损失函数值最小。
线性打分函数:从图片到标签打分的参数化映射
我们定义线性分类器打分函数:
其中
- f是我们定义的打分函数,形状是[K, 1],K是类别数
- xi是扁平化的图像向量,形状是[whc, 1]
- W是权重矩阵,形状是[K, whc],每行代表一个类别的分类器
- b是偏移量向量,形状是[K, 1]
最后得到一个[K, 1]的向量,即各个类别的得分。
与KNN相比,在训练完成后即可丢弃掉所有训练数据,减少了空间复杂度;每次预测只需要计算一次矩阵乘法和加法,减少了时间复杂度。
计算本质上是对每个像素点的每个通道值做一个线性计算,再求和得到一个分值。
权重矩阵代表了分类器对每个像素点颜色的偏好。
分类器可以理解为对高维空间的线性分割,权重使分割旋转,偏移量使分割平移。
分类器还可以理解成对每个类别训练出一张代表性的图片(模版),即权重,然后使用最近邻居算法,只不过距离是待预测图片与模版的点积再加偏移量。CIFAR-10得出的模板如下:
可见,模板体现了每个类别的颜色,但线性分类对于不同颜色的同类物体分类能力是很弱的。
一个简化计算的技巧:将输入向量增加一个1,将W与b合并成一个矩阵,这样计算就变成了一次矩阵乘法。
数据预处理:图像数据需要减去一张平均图片,然后再映射到[-1, 1]区间。处理后所有图片相加得到全零矩阵。
SVM损失函数
我们定义每个图片的损失: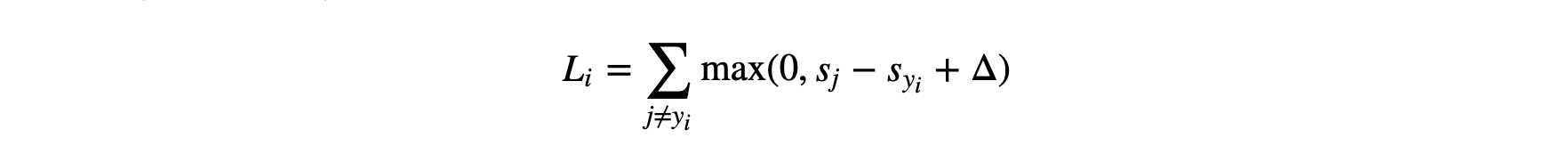
其中
- Li是第i张图片的损失,每一项max(…)称为铰链损失,hinge loss
- sj是第j个错误类别的得分
- syi是正确类别的得分
- Δ是一个固定的margin值,是一个超参数
综上,损失函数值就是每个错误类别得分减去正确类别得分,再加上Δ后,与0取最大值,再求和。有时会使用二次方的形式,即取最大值后做一次平方,称为L2-SVM。
当正确类型比每个错误类型的得分都高出Δ以上时,损失为0。
当损失为0时,将W乘以一个大于1的数后损失仍为0,为了限制W的大小,引入了代表W每个元素大小的损失,称为正则化损失,regularization loss: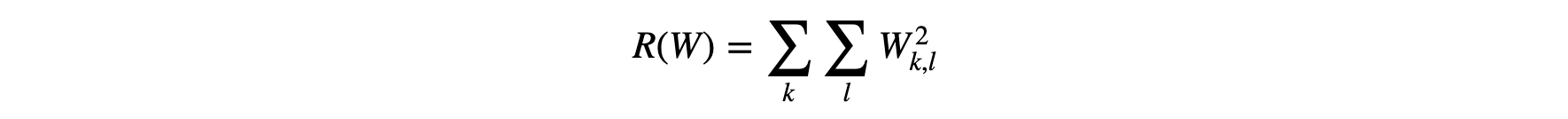
即W中每个元素的平方和。这样我们就得到SVM损失函数的完整形式,即数据损失+正则化损失: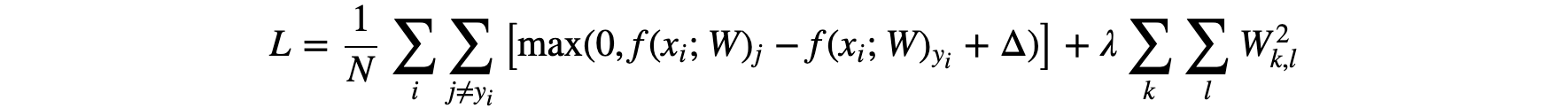
其中对每个图片的损失做了平均,在加上代表W大小的损失,λ是一个超参数,通过交叉验证来确定。引入正则化损失还可以使模型的泛化能力更好,减少过拟合。
由于Δ和λ都是用来平衡数据损失和正则化损失两者的贡献,所以Δ可以固定取1,只需调整λ。
交叉熵损失函数
交叉熵损失函数是另一种常见的损失函数,是将SVM中的铰链损失替换成交叉熵损失,cross entropy:
其中Li是第i张图片的损失,fyi是正确类别得分,fj是所有类别得分。
括号内的部分称为softmax函数,用于将一个向量压缩成一个值在[0, 1]区间的向量,且元素之和为1。
而交叉熵是指两个分布之间的相似程度,表达式如下:
其中p是真实分布[0, … 1, … , 0],q是预测分布,即打分再softmax处理后的结果,只有正确类别那一项保留下来,其他项都为0。所以每张图片的损失是打分函数-softmax-交叉熵,这样得出的。每张图片的损失取平均,再加上正则化损失就是完整的损失函数。
注意,softmax得出的“概率分布”受正则化损失系数λ的影响,不算是真正的概率。
对比

SVM分类器和Softmax分类器都使用Wx+b的矩阵乘法计算出类别分值,区别是:
- SVM使用铰链损失
- Softmax使用交叉熵损失
SVM在打分差异足够大时,损失就不再降低;而Softmax则永不满足。

若有收获,就点个赞吧
0 人点赞
