神经网络的结构可以从线性分类器扩展而来。
最简单的两层神经网络可以表示成s = W2 max(0, W1x)
假设输入向量x的形状是[3072, 1],则W1可以是一个[100, 3072]的矩阵,W1x就是一个[100, 1]向量
然后经过max(0, x)将所有的负元素变为0,这是一个非线性化的操作。如果不做非线性化,则两个权重矩阵可以合并成一个矩阵。这里的max函数即整流线性单位函数(Rectified Linear Unit, ReLU)。
第二个权重矩阵W2是一个[10, 100]矩阵,最终得到的结果是[10, 1]向量,即打分结果。
神经网络可以继续扩展到三层:s = W3 max(0, W2 max(0, W1x)),中间向量的维度都是超参数。
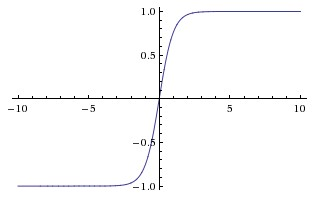
神经元与权重矩阵中的一个行向量之间的类比如下图,激活函数可以选择sigmoid,将实数域压缩到[0, 1],或上面的ReLU。
一些类比:
| 大脑 | 神经网络 |
|---|---|
| 前一个神经元的轴突 | 输入向量的一个元素 |
| 神经元的树突 | 权重向量的一个元素 |
| 突触连接 | 以上两者相乘,以权重表征连接强度,以正负表征激活还是抑制 |
| 神经元内部整合 | 乘积相加 |
| 传递出信号的速率 | 激活函数的结果 |
需要注意这一类比是非常粗略的,真实的突触并非以线性方式处理传递来的信号,而神经冲动输出的时机而非速率在真实的神经系统中更加重要。
激活函数
| Sigmoid | Tanh | ReLU | 泄漏ReLU |
|---|---|---|---|
 |
 |
 |
 |
激活函数的作用是提供非线性。常用的激活函数有:
- Sigmoid:σ(x)=1/(1+e-x) ,R => [0, 1],历史上用于模拟神经信号发射速率,因为有容易饱和和均值非0这两个问题,现在已很少使用。
- Tanh:R => [-1, 1],解决了均值非0的问题,但仍有饱和问题。
- ReLU:max(0, x) ,不会饱和,运算量少,收敛快,使用广泛。学习率过大时会使神经元“死掉”。
- 泄漏ReLU:解决尝试神经元死亡问题,但效果不稳定。
- Maxout:计算出两个点积,取最大值。保留ReLU线性、不会饱和的优点,解决了死亡问题,但参数量过大。
神经网络的结构
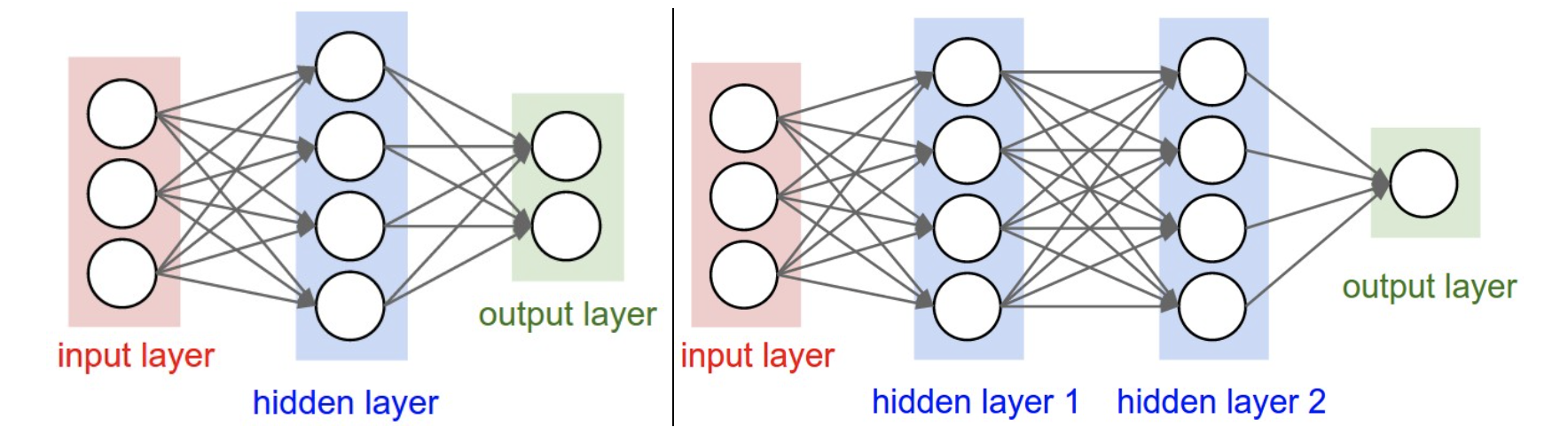
- 神经网络由一层层神经元构成
- 说到神经网络的层数时,不算输入层
- 相邻两层神经元之间两两连接,称为全连接层
- 由全连接层构成的神经网络也称作“Artificial Neural Networks” (ANN) 或 “Multi-Layer Perceptrons” (MLP)
- 输入层和输出层之间的层称为隐藏层
- 输出层不使用激活函数,输出喂给损失函数
- 现代卷积神经网络的参数量可达100M,层数10-20,所以称为深度学习
可以证明,至少有一个隐藏层的神经网络可以认为是对任何连续函数的近似。
3层网络的表现要好于2层网络,但继续增加层数基本上不会再提升表现。
使用更多的神经元可以表达更复杂的函数,但也容易过拟合,受数据噪音的影响更大。
更多的神经元带来更大的过拟合:
通过增加正则化系数来抑制过拟合: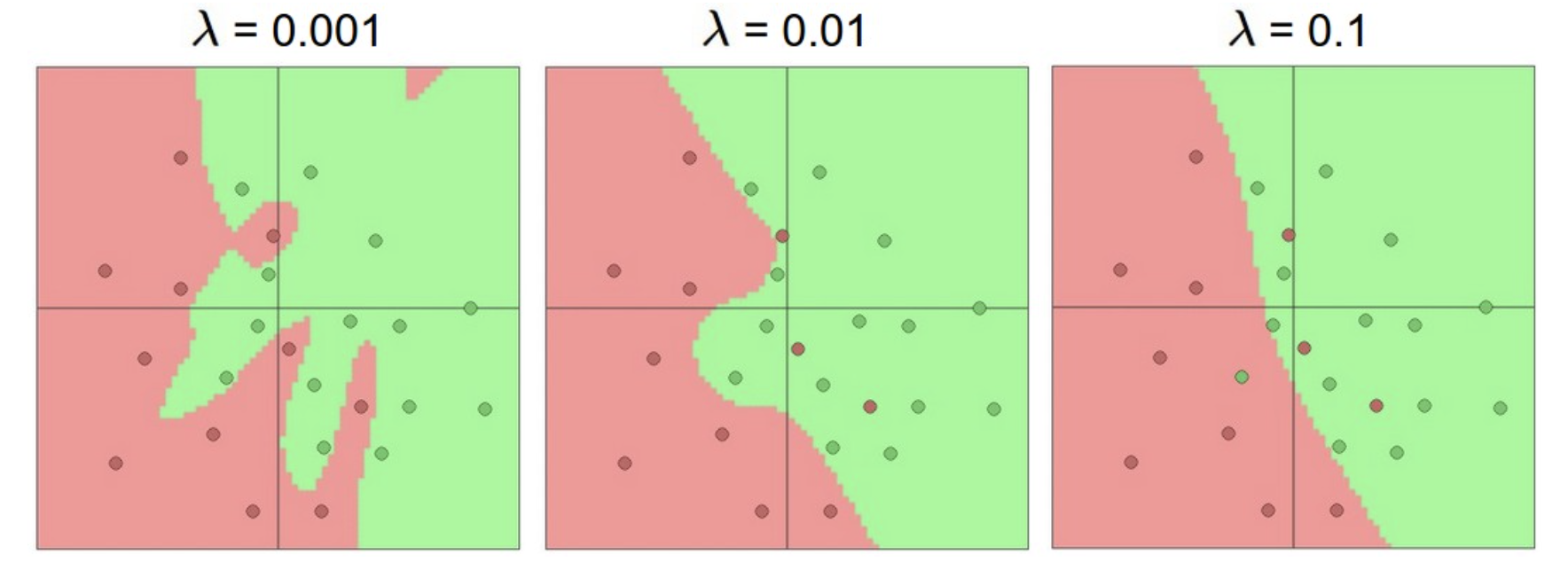
数据预处理
减平均值(对中)、除标准差(归一化):常规操作
PCA(降维)、白化(归一化):在卷积神经网络中并不使用这两种方法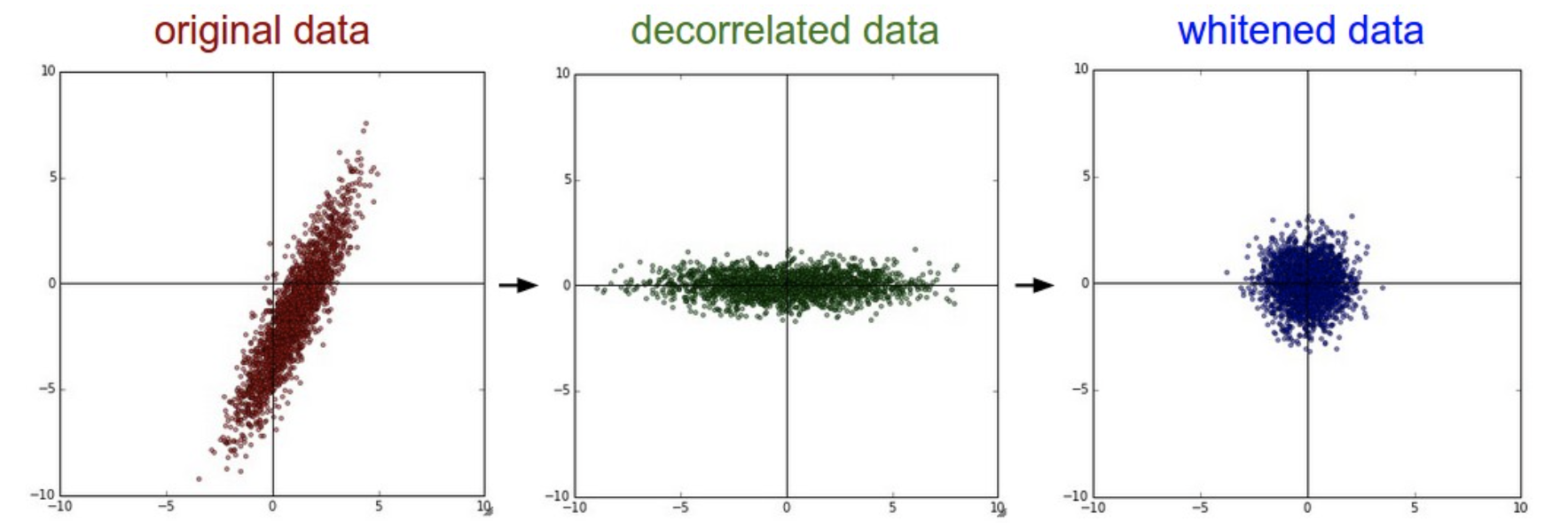
权重初始化
不要使用全0矩阵,因为会使神经元以相同的方式更新。一般使用小的随机数作为初始值。对于使用ReLU的神经网络,还需要除以根号(2/输入数量)。
偏移量可以简单用0来初始化。
批次归一化(Batch Normalization,BN),BN层位于卷积层和非线性之间。BN可以认为是将初始化整合进了网络中,使用BN可以有效减少初始化引入的各种问题。
选择正则化:减少过拟合
L2正则化,最常用,就是将权重的平方和计入损失函数。直观的解释是,使权重更加分散,从而能够更加全局的感知输入数据。
其次是L1正则化,取权重的绝对值而非平方,能够有效减少噪音数据的影响。
Max norm设置权重的上限
Dropout,在训练时随机将神经元关闭(输出为0),测试时全部打开。与此类似,可以随机将权重置为0。卷积神经网络中也有类似的做法,比如随机池化、分级池化、数据增强等。
实践中,一般将L2正则化和Dropout结合使用。
选择损失函数:预测vs真实
最常用的是SVM和交叉熵
给图片加多个标签这种分类任务,可以对每个标签训练一个二元分类器。
回归任务需要对一个输入值预测一个输出值,可以用预测值与真实值之差的平方和做损失函数。离散值的情况也可以转化成分类任务。
梯度检查:梯度是否正确实现
用数据梯度来校验分析梯度,数值梯度考虑两侧的变化量。
要使用相对误差,一般要求10层网络小于1e-2。要使用双精度浮点数。可以打印出梯度结果,检查是否过小(小于1e-10),以避免精度问题。不可导点会带来梯度误差,使用很少的数据点可以减少这个问题的影响。步长h不要太小,会有精度问题。梯度检查要在几轮优化后再进行。正则化损失可能会掩盖错误的实现。
冒烟测试:整个网络是否正确实现
对损失值有一个估计,检查计算出的第一个损失值是否符合预期。
增加正则损失项,应该会看到损失值增加。
关闭正则损失项,对很小的一部分数据做训练,损失应该可以降为0。
监控训练过程:损失、准确率
损失函数在前向传播过程中的变化
左:不同学习率的影响。右:一个实际的例子,batch过小使曲线毛刺很多
使用y轴也可以使用对数坐标
准确率曲线,反映是否过拟合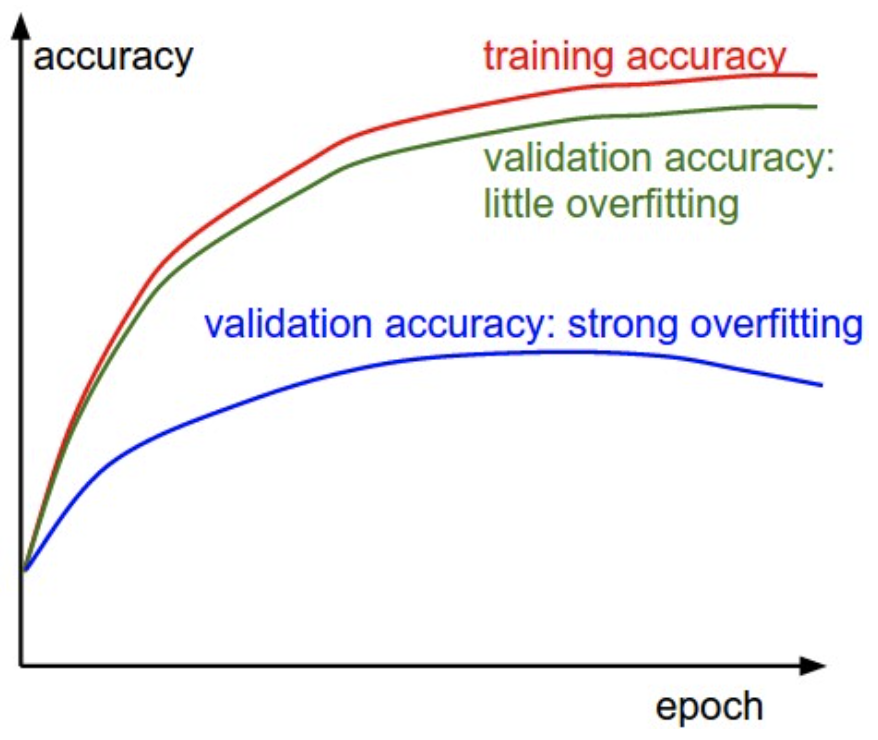
权重变化量/权重一般要在1e-3左右
每层的输出需要在其值域中均匀分布
对权重做可视化也可以帮助判断是否有异常,右图是正常结果
权重更新过程:优化器
基本的SGD:权重 -= 梯度 * 学习率,最原始的版本,性能比较差
动量
- 可以使用物理上的类比,加速度 - 速度 - 位置 => 权重。
- 改进版:Nesterov动量,使用未来的梯度。
学习率可以随时间衰减
- 可以在高学习率下观察到收敛后再降低学习率
- 也可以按照台阶、对数、倒数函数的方式自动降低学习率
二次方法
- 使用二阶偏导数(梯度是一阶偏导数),优点是不需要超参数。缺点是时间和空间复杂度巨大。
- 改进版是采用了近似的L-BFGS,但需要使用整个训练集来计算,而SGD只需要一个小的batch。
此外,还有一些对权重的每个元素区别对待的更新方法
- Adagrad:使用累计梯度来衰减学习率,由于学习率是单调递减的,在深度学习中表现不佳
- RMSprop:修改了Adagrad的衰减方式,学习率不再是单调递减
- Adam:结合了RMSprop和动量,是目前最优选择。Nesterov-SGD也是不错的选择
以上优化器的可视化对比:https://cs231n.github.io/assets/nn3/opt2.gif
在马鞍面上的对比,亚稳态:https://cs231n.github.io/assets/nn3/opt1.gif
超参数调优
一些主要的超参数:初始学习率,学习率衰减方式,正则化损失系数等。使用验证集来选择最优的超参数。
主从结构:
- 若干worker负责尝试不同的超参数、训练模型、每个epoch后记录checkpoint
- 一个master负责管理worker,绘图
调整超参数时,有些用乘法,有些用加法。随机尝试优于等间距尝试。注意不要让最终结果处于尝试的边界。
尝试应当从粗而浅,到细而深,开始时使用尽量少的计算量。
贝叶斯优化是一个高效进行超参数优化的算法领域,但在卷积神经网络的实践中,表现并不及随机尝试。
模型组团
实践中,可以将训练多种模型,测试时将它们的结果取平均,可以将整体表现提高几个百分点。
有以下几种组合方式:
- 使用最优的超参数,不同的随机初始化
- 使用前几名的超参数
- 使用同一个模型的不同checkpoint
使用组合的缺点是,使用模型的开销变高了。

若有收获,就点个赞吧
0 人点赞

{kind=link}
{kind=link}