序
看看下面的 Hello World(Demo.java 文件),是不是很熟悉?
public class Demo {public static void main(String[] args) {System.out.println("Hello world!");}}
一旦在装有 JRE 的机器上运行上述的代码就会在得到「Hello world!」的输出结果。
背景知识 JDK = JRE + Java 开发工具 JRE = JVM + 核心类库
那么你是否想过这个过程是怎么实现的?
开始解答这个问题之前,我们先来看看 Java 语言的跨平台特性—— JVM 屏蔽了底层操作系统的差异,得以让编译之后的 Java 代码(字节码)统一运行在 JVM 上。换句话说 JVM 是运行在底层操作系统上的一个进程,Java 字节码是在 JVM 上执行的,实现跨平台的其实是 JVM。 
如上图所示,Java 代码会先编译成 Java 字节码,然后由 JVM 加载执行。
这个过程中有两个重点,分别是字节码文件和 JVM。
1. Java 字节码
我们可以通过命令 javac Demo.java 得到 Demo.class 文件,然后使用命令 javap -verbose -p Demo.class 得到反编译之后的字节码信息,内容如下:
Classfile /Users/zhangxin/Documents/work_space/JAVA-000/out/production/JAVA-000/Demo.classLast modified 2020-10-17; size 516 bytesMD5 checksum 465925dfeffab3462cbef628a9078832Compiled from "Demo.java"public class Demominor version: 0major version: 52flags: ACC_PUBLIC, ACC_SUPERConstant pool:#1 = Methodref #6.#20 // java/lang/Object."<init>":()V#2 = Fieldref #21.#22 // java/lang/System.out:Ljava/io/PrintStream;#3 = String #23 // Hello world!#4 = Methodref #24.#25 // java/io/PrintStream.println:(Ljava/lang/String;)V#5 = Class #26 // Demo#6 = Class #27 // java/lang/Object#7 = Utf8 <init>#8 = Utf8 ()V#9 = Utf8 Code#10 = Utf8 LineNumberTable#11 = Utf8 LocalVariableTable#12 = Utf8 this#13 = Utf8 LDemo;#14 = Utf8 main#15 = Utf8 ([Ljava/lang/String;)V#16 = Utf8 args#17 = Utf8 [Ljava/lang/String;#18 = Utf8 SourceFile#19 = Utf8 Demo.java#20 = NameAndType #7:#8 // "<init>":()V#21 = Class #28 // java/lang/System#22 = NameAndType #29:#30 // out:Ljava/io/PrintStream;#23 = Utf8 Hello world!#24 = Class #31 // java/io/PrintStream#25 = NameAndType #32:#33 // println:(Ljava/lang/String;)V#26 = Utf8 Demo#27 = Utf8 java/lang/Object#28 = Utf8 java/lang/System#29 = Utf8 out#30 = Utf8 Ljava/io/PrintStream;#31 = Utf8 java/io/PrintStream#32 = Utf8 println#33 = Utf8 (Ljava/lang/String;)V{public Demo();descriptor: ()Vflags: ACC_PUBLICCode:stack=1, locals=1, args_size=10: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnLineNumberTable:line 1: 0LocalVariableTable:Start Length Slot Name Signature0 5 0 this LDemo;public static void main(java.lang.String[]);descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=2, locals=1, args_size=10: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;3: ldc #3 // String Hello world!5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V8: returnLineNumberTable:line 3: 0line 4: 8LocalVariableTable:Start Length Slot Name Signature0 9 0 args [Ljava/lang/String;}SourceFile: "Demo.java"
从关键字可以看出内容里面有「常量池」、「类定义」、「方法」、「参数」等等,而上面的内容仅仅是实现了输出一句 「Hello world!」,可以想象程序的业务越复杂,生成的字节码内容也会更多。比如加减乘除、逻辑控制等操作都会在字节码里面有对应的操作符,想要读懂字节码就得熟悉这些操作符,好在这些操作符是固定的,也不算很多(目前为止共 200 多个左右)。
看不懂也没关系,一般情况下用不着关心这个字节码,只需要明白 Java 程序代码会先被编译成字节码文件,然后由 JVM 去加载执行就够了。
如果你的工作涉及到字节码编程,那就需要好好了解字节码技术了。字节码编程可以算是 Java 语言里面的黑科技,比如可以通过字节码修改技术直接注入到别人的代码中实现统计、监控等功能而无需修改源代码。
关于字节码相关的知识可能会单独写一篇文章来详细说明,这里就先略过。
2. JVM 内存模型
JVM 的主要作用是加载执行字节码和垃圾回收,不过要了解这两块知识,需要先了解 JVM 的内存模型。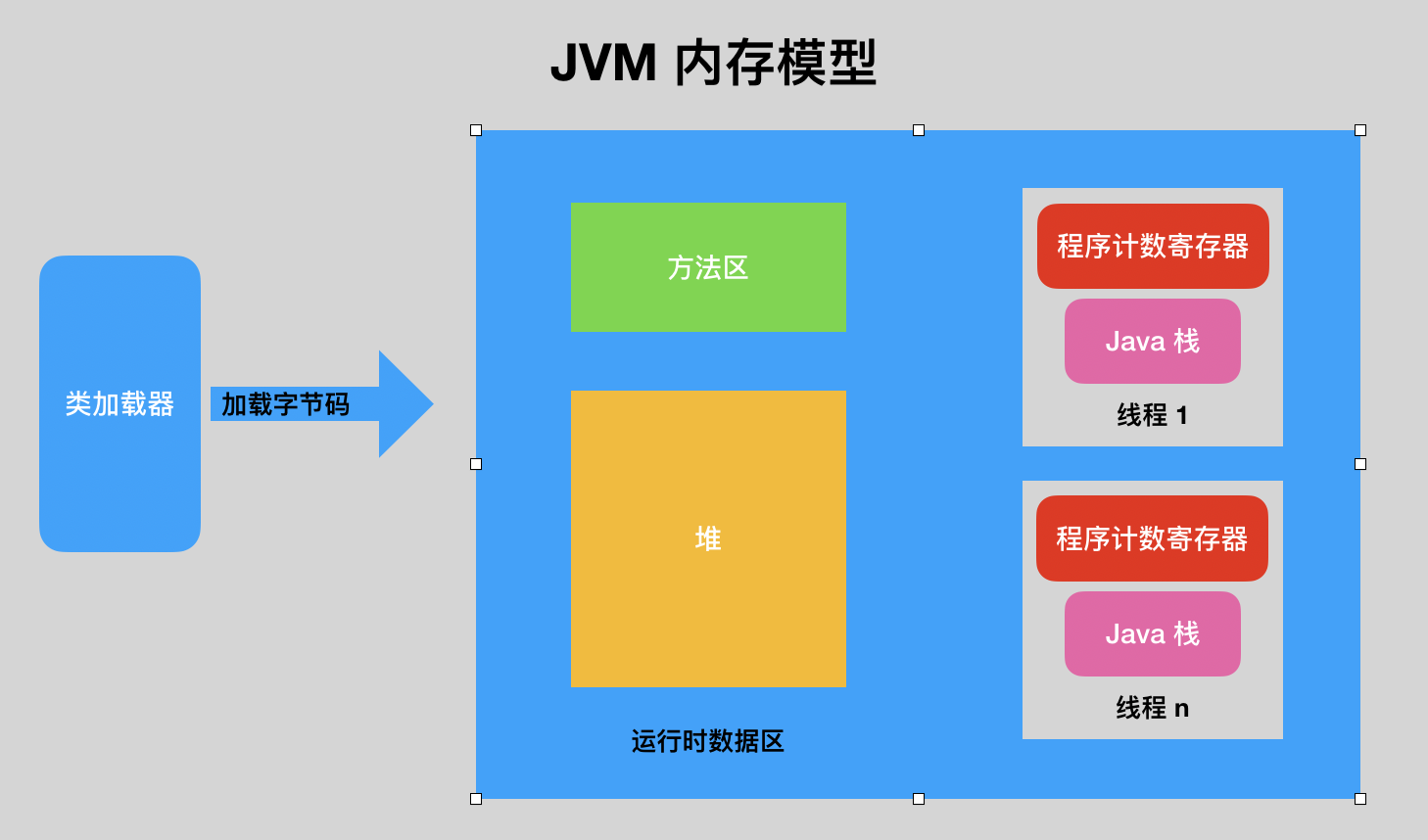
主要的模块有类加载器,负责加载字节码到运行时数据区;运行时数据区主要分为三个部分,方法区主要存储字节码信息(比如类定义),堆负责管理对象实例的内存,这两者都是对线程共享的;线程是程序运行的基本单位,每个线程里面有自己的程序计数寄存器(负责记录当前程序运行的位置)和 Java 栈(栈里存放着方法运行期的局部变量)。
用上面的 Hello world 程序举个例子,JVM 会先加载 class 文件到方法区,然后创建主线程执行 main 方法,方法里面的参数和局部变量会被压入 Java 栈。
如果 main 方法里面创建了一个新对象实例,这个对象实例会被存储到堆中,Java 栈里面只会记录该对象实例的引用。
程序计数寄存器记录了 main 方法第一行的位置,JVM 会根据位置去方法区执行对应的代码。如果这过程中调用了其他的方法,就会生成一个新的栈帧压入 Java 栈,等到这个新方法执行完成就执行出栈继续执行之前的方法。
从 Java 栈的角度谈谈线程安全的问题吧。
- 方法内部定义的变量都会存储在 Java 栈中,由于线程是相互隔离的,所以这些变量一定是线程安全的。
- 如果方法内创建了一个对象实例,但是只有当前方法引用了该对象,就算该对象实例存储在堆中,也不会有线程安全问题。
- 如果方法内创建的对象被其他线程引用了,才可能会出现线程安全问题,因为对象可能是无状态的,不会涉及到对象的成员变量冲突。
因此,在处理线程安全的问题上,从 JVM 模型上出发会更好理解一些。
3. JVM 垃圾回收
JVM 的垃圾回收主要是在堆内存,因为堆内存里面存放了对象实例、成员变量等数据,而这些都是在程序运行过程中创建的,有些可能用过一两次就不会再使用了,但是依然占据着内存,如果不清理就会导致新的对象没法存放引起内存溢出。
因此,要了解 JVM 垃圾回收机制,首先得弄清楚堆内存的模型,如下图: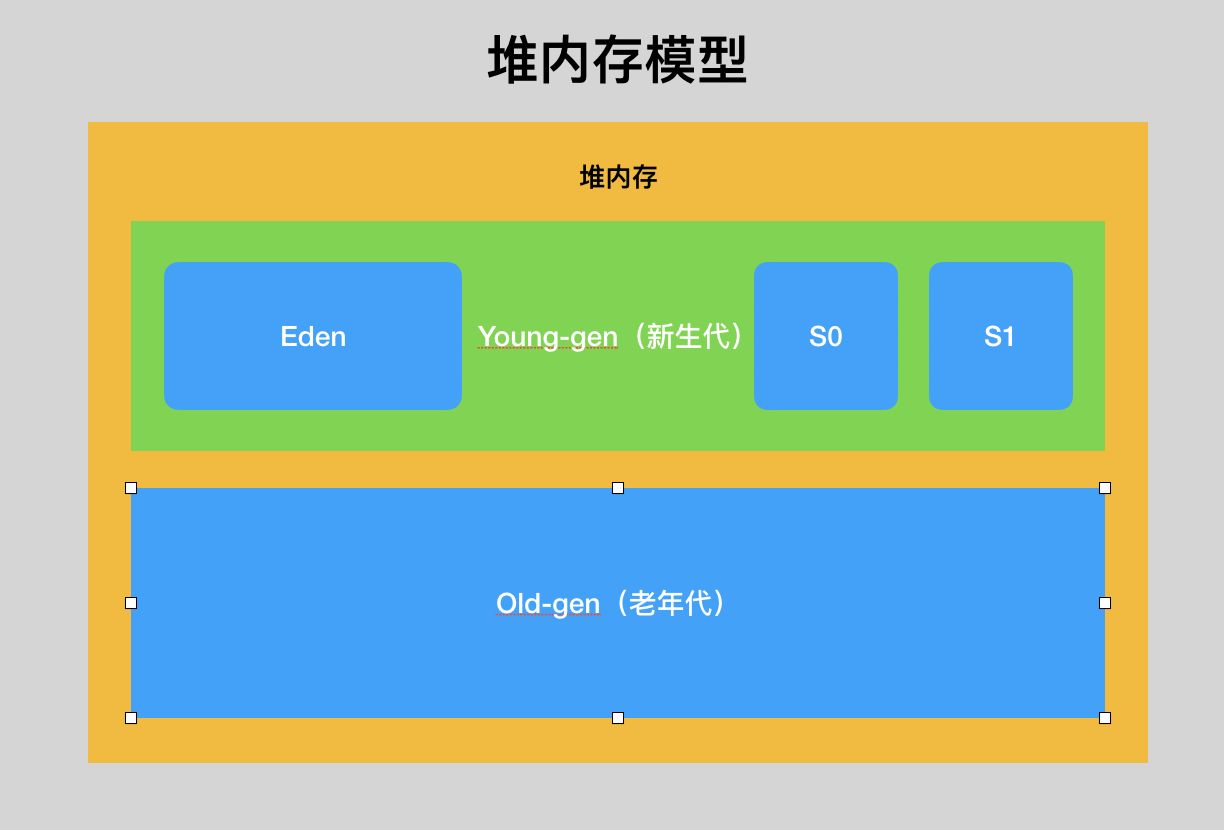
整个堆内存分为两部分,「新生代」和「老年代」,顾名思义就是前者生存时间较短,后者生存时间较长。其中「新生代」里面又分为三部分:「Eden」、「S0」、「S1」,「Eden」区是对象首次被创建时存放的地方,「S0」和「S1」一般同时只有一个区里面有存活对象。每次对「新生代」进行垃圾回收时存活对象就会被复制到 「S1」或者「S0」,这样经过多次垃圾回收之后,依然存活的对象就会被放到「老年代」。
那么 JVM 为啥要这样对堆内存分代呢?
因为有这样的一个假设(这个假设是成立的):大部分的对象在程序运行过程中只会存在很短的时间。如果不分代处理垃圾回收的话,每次都得扫描整个堆内存,可以想象这样的效率是很低的。~~
要进行垃圾回收,首先得知道哪些对象是垃圾,这就涉及到「引用计数」和「可达性分析」两种算法。前者是对引用的对象计数,凡是对应的对象引用计数器为 0 就表示该对象可以被回收,缺点是无法解决循环引用问题(循环引用的对象始终不为 0 );后者对能访问到引用对象标记,凡是没有标记的对象就可以被回收,这可以很好的解决循环引用问题,也是主流的垃圾回收器采用的算法。
下面是常用的垃圾回收器使用的算法:
- 标记-复制算法:把内存分为两个区域,先对存活的对象进行标记,然后把存活的对象复制到另外一个区域,原来的区域就可以看作是完全空闲的,可以直接分配。优点是效率较高,只需要复制存活对象;缺点是内存空间利用率不足,一般两个区域同时只有一个区域有数据。

- 标记-压缩算法:标记过程同理,但是为了不出现内存碎片,就需要把后面的对象移动到前面来。优点是内存利用率高,不会出现内存碎片;缺点是效率不高,需要把对象一个一个的移动到合适的内存位置。

- 标记-清除算法:标记过程跟上面一样,清除就只需要把对象的内存释放掉就行。优点是效率高,因为不涉及到内存的整理;缺点也很明显,会出现内存碎片。

举个例子,「新生代」因为本身就分为「Eden」、「S0」、「S1」三个区,所以通常是使用的标记-复制算法。
首先会对存活的对象进行标记,然后把存活的对象从「Eden」和 「S0」复制到 「S1」,然后交换 「S0」和「S1」的名称(也叫做 From 和 To),这样原来的区域就可以给新对象分配。如果有对象多次回收之后还会存在,就晋升到「老年代」。
了解了垃圾回收算法,我们来看看常用的几种垃圾回收器,主要分为 3 类,每个类下面可能会有几种不同的垃圾回收器。
- 串行垃圾回收器:作为早期的垃圾回收器,只有单个线程做垃圾回收工作,以 Serial 串行垃圾回收器为代表。
- 并行垃圾回收器:可以理解为串行垃圾回收器的多线程版本,理论上的效率会比串行垃圾回收器高,主要以 Parallel Scavenge、 Parallel Old、ParNew 为代表。
- 并发垃圾回收器:并发和上面的并行最主要的区别就是进行垃圾回收时,对程序的执行影响较小。前面的串行垃圾回收器和并行垃圾回收器都会导致 Stop-The-World,也就是说在垃圾回收的时候需要停止程序的运行。而以 CMS 为代表的并发垃圾回收器就可以在某些情况下不影响或者减少影响程序的运行。
- 新一代垃圾回收器:主要是以 G1 垃圾回收器和 ZGC 垃圾回收器为代表,前者会把整个堆内存分成很多块,针对每个块单独进行垃圾回收——也就意味着跟上面提到的堆内存结构有所区别;后者是最新的 Java 垃圾回收器,暂时还没有成熟。不过可以确定的是,越是新的垃圾回收器,就会越减少人为的参与垃圾回收的配置和调优。
下面是几种垃圾回收器的分类: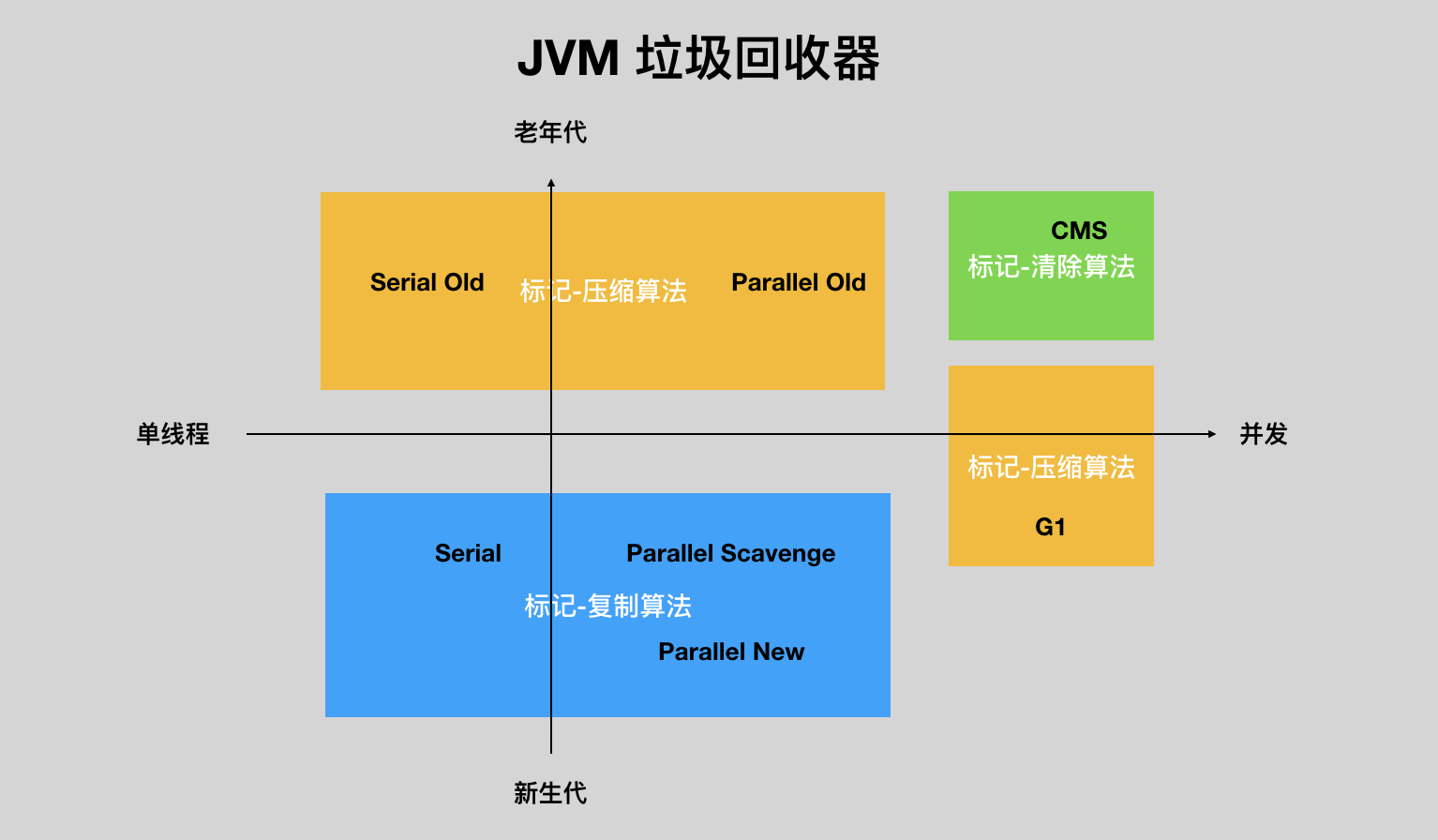
因为不同的垃圾回收器有不同的适用范围,所以一般都会把各种垃圾回收器组合起来使用。JDK8 默认使用 Parallel 垃圾回收器,JDK9 默认使用了 G1 垃圾回收器。

若有收获,就点个赞吧
0 人点赞
