序
前面一篇文章提到了 JVM 的内存模型和几种常用的垃圾回收算法和垃圾回收器,这篇文章主要的目的是进一步了解一些 JVM 的配置参数,以及它们是怎么影响垃圾回收效率的,也就是 JVM 调优。
在开始之前,我们先提出一些问题,带着问题去寻找答案往往会更加深刻:
- 堆内存的大小是否可以自定义设置?
- JVM 的参数配置是否会影响垃圾回收效率?
- 各个垃圾回收器之间有啥区别?
想要弄清楚这些问题,就需要对 JVM 的参数有个大致的了解,并且通过不同参数的设置去对比其产生的结果,从而尝试去寻找原因。
JVM 相关参数
JVM 的参数有很多,比如 Java 命令相关的,Java 工具相关的,以及 JVM 内存相关的。
本篇文章主要针对 JVM 内存相关的参数和一些必要的命令行参数进行辅助分析结果,并不是完整的命令参数指南。
前面已经提到了 JVM 的内存模型,里面有「堆内存」、「Java 栈」、「方法区」等部分,这些在 JVM 里面也有对应的参数可以设置。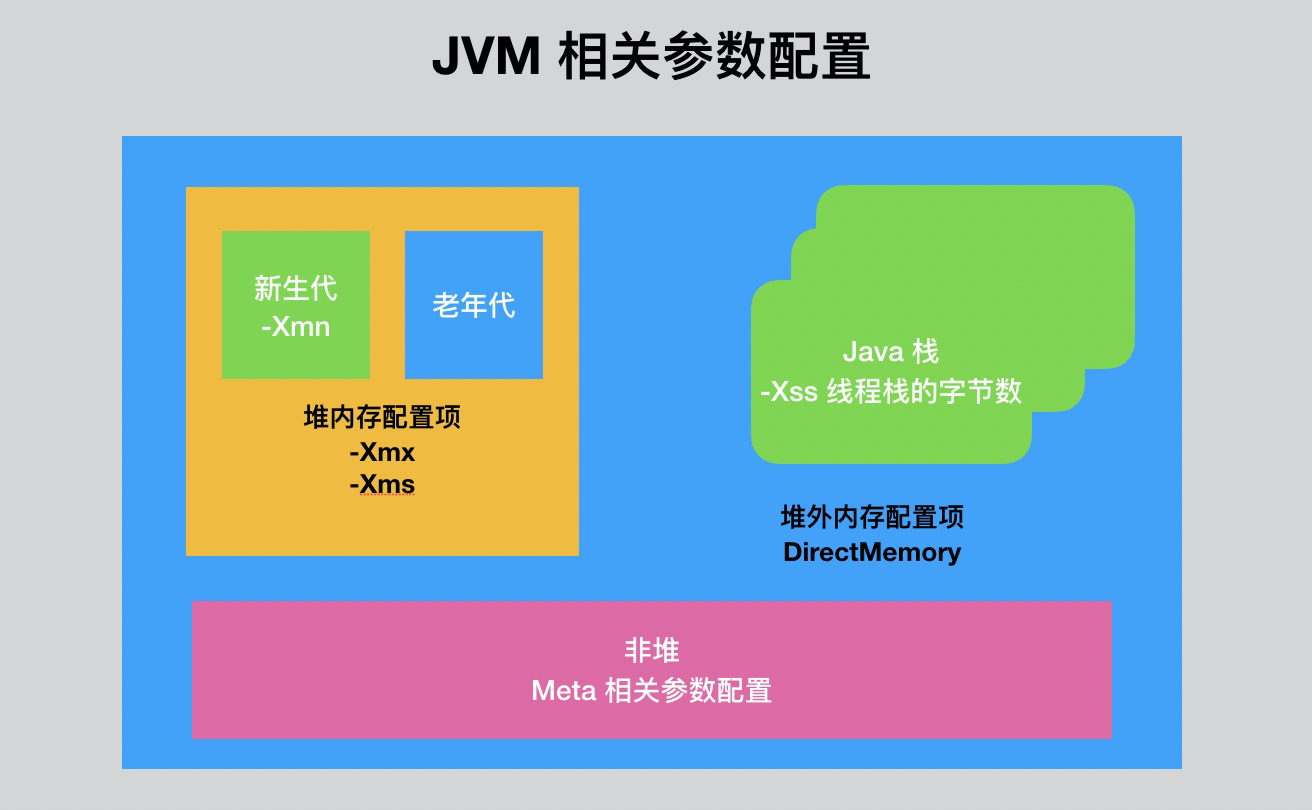
如图所示,「堆内存」的大小可以使用 -Xmx 和 -Xms 分别指定最大可使用内存和最小可使用内存,针对「Java 栈」也有 -Xss 参数可以指定线程栈的字节数大小,非堆(也就是方法区所处的位置)和堆外也有对应的参数可以调整。
这些参数有什么影响呢?
拿「堆内存」来举例,如果「堆内存」的内存过小,就存储不了太多的对象实例,尽管有垃圾回收的处理,也不过是只能减缓程序内存溢出的时间。一般 -Xmx 和 -Xms 这两个参数值设置为相等,比如 -Xmx4g -Xms4g,这样的好处是减少内存使用时可能造成性能上的抖动。
比如一开始设置的参数是 -Xmx4g -Xms2g,在程序运行前期内存使用不超过 2g 的情况下不需要扩容,随着程序运行导致内存占用越来越多,扩容的时候就会导致频繁的 Full GC,由于每次的 GC 是会对程序业务运行造成影响的(也就是前面提到的 Stop-The-World,并且垃圾回收本身也会消耗资源),因此不如一开始就让可使用的内存为允许的最大值,省去扩容导致的性能抖动。
换一个用 「Java 栈」来举例,当程序里的方法调用链过长(比如滥用递归),就会导致「Java 栈」的栈帧过多,如果超过了 -Xss 设置的值后就会引起栈溢出。
除了上面 JVM 堆内存相关的参数设置之外,还有 GC 相关的参数,这些参数在 JVM 调优方面会经常使用到。
针对 JVM 的 GC 日志,可以使用 -XX:+PrintGCDetails 和 -XX:+PrintGCDateStamps 在控制台输出垃圾回收过程的日志信息和具体触发的时间,如果想要保存到日志文件只需要加上 -Xloggc:xxx.log 就可以输出到指定的 xxx.log 文件中。
如果想具体指定某种垃圾回收器进行垃圾回收也是可以的,下面将会使用不同的垃圾回收器在相同参数下 GC 的日志分析。
测试的代码文件是 GCLogAnalysis.java,可以点击这个链接查看 Github 代码。这个类主要的作用是在 1000 毫秒内随机生成不同类型的对象,新增或者覆盖到数组中,这样就一定会有对象新生、存活、死亡,也就会触发垃圾回收机制。
使用 Serial GC
# 使用 Serial GC、 堆内存设置 512m、 日志文件保存到 serial.log 文件java -XX:+UseSerialGC -Xmx512m -Xms512m -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:serial.log GCLogAnalysis
使用 Parallel GC
# 使用 Parallel GCjava -XX:+UseParallelGC -Xmx512m -Xms512m -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:parallel.log GCLogAnalysis
使用 CMS GC
# 使用 CMS GCjava -XX:+UseConcMarkSweepGC -Xmx512m -Xms512m -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:cms.log GCLogAnalysis
使用 G1 GC
# 使用 G1 GCjava -XX:+UseG1GC -Xmx512m -Xms512m -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:g1.log GCLogAnalysis
GC 分析
用上面的命令分别统计 4 种 GC 在堆大小为 512m、1g、2g 的情况下垃圾回收的次数,得到下面的表格(不同电脑得出的数据很可能不一致):
| 垃圾回收器 | 生成对象数(1000 毫秒) | Young GC 次数 | Full GC 次数 | -Xmx | -Xms |
|---|---|---|---|---|---|
| Serial | 10000 | 22 | 3 | 512m | 512m |
| Parallel | 9000 | 26 | 13 | 512m | 512m |
| CMS | 10000 | 21 | 12 | 512m | 512m |
| G1 | 11000 | 28 | 2 | 512m | 512m |
| Serial | 12000 | 12 | 0 | 1g | 1g |
| Parallel | 12000 | 22 | 2 | 1g | 1g |
| CMS | 13000 | 13 | 2 | 1g | 1g |
| G1 | 13000 | 5 | 0 | 1g | 1g |
| Serial | 12000 | 5 | 0 | 2g | 2g |
| Parallel | 13000 | 8 | 0 | 2g | 2g |
| CMS | 13000 | 6 | 0 | 2g | 2g |
| G1 | 13000 | 1 | 0 | 2g | 2g |
从表格里可以看出不同 GC 在 1000 毫秒内生成的对象数差距不大,为了减少变量的影响,重复执行了多次取近似值的方式进行统计。
主要分析的纬度有两个,一个是堆的大小,另一个是垃圾回收的次数。当然,垃圾回收又分为 Young GC 和 Full GC 两种。为了更加直观的表示,下面画出了对应的图表。
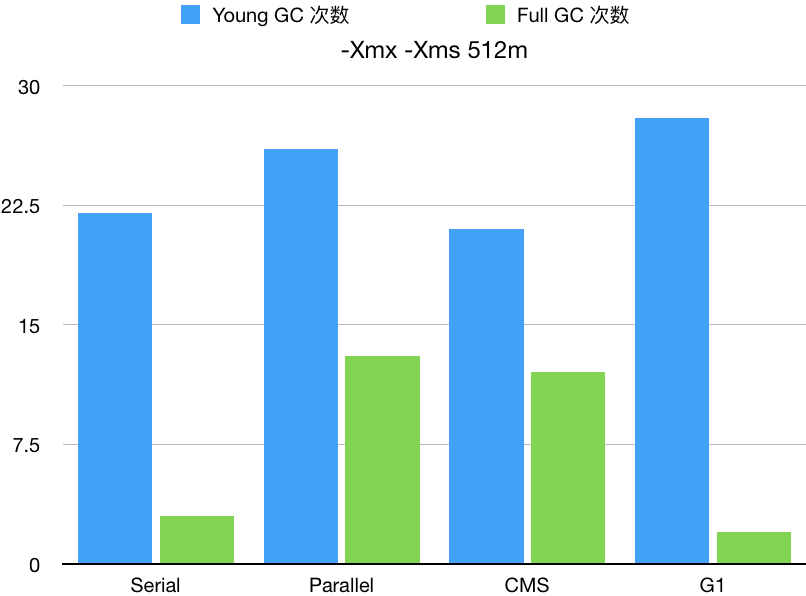
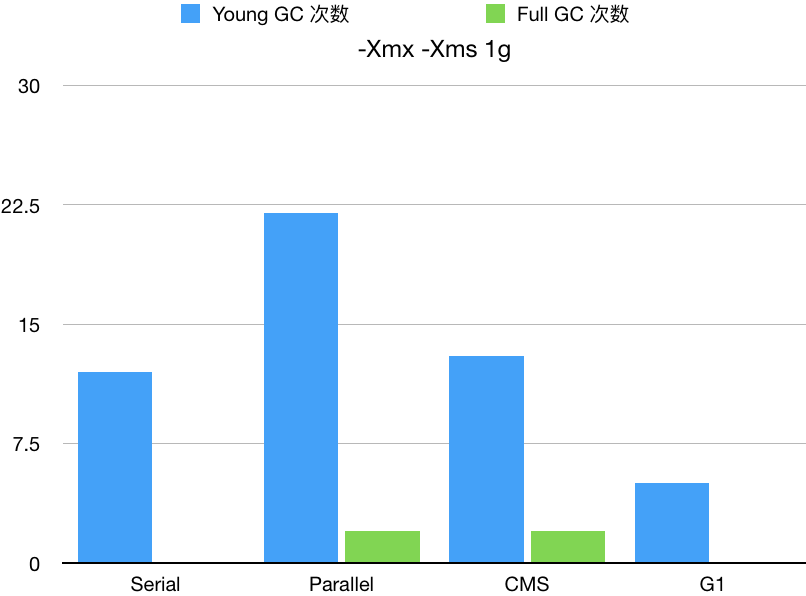
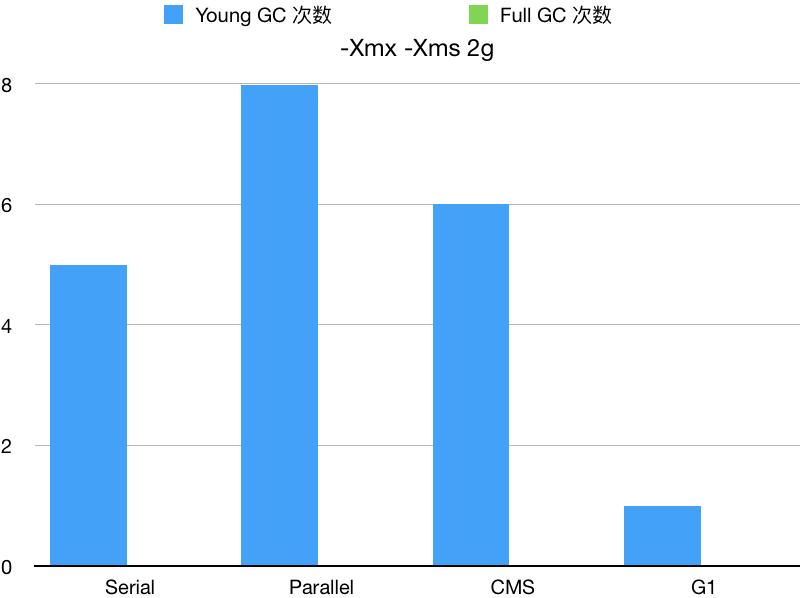
可以明显的看出,在内存比较小的情况下,并行的 GC (Parallel GC 和 CMS GC)可能还不如串行的 GC。
而并行的 GC 在相同内存大小情况下,CMS GC 会比 Parallel GC 表现的更好一点。
G1 GC 在内存较小的情况下 Young GC 会频繁触发,但是内存足够的情况下,各方面就会表现的比其他垃圾回收器好。
到了这里呢,也就能解答文章开头提出的 3 个问题了。
最后说一下 G1 垃圾回收器吧,上一篇文章里提到了它是 JDK9 的默认垃圾回收器,同时它几乎打破了之前的堆内存模型结构,那么它的堆内存模型结构是什么样的呢?
如图所示,G1 的堆内存依然分为「新生代」和「老年代」,前者也同样有「Eden 区」和「存活区」。不一样的是 G1 的新生代和老年代的大小是可以动态修改的,一共有 1024 个区块,每个区块都有可能是「Eden 区」、「存活区」或者「老年代」。
G1 的垃圾回收时也是分块来回收的,比如当一个区块的大小超过某个阈值,就触发这个区块的垃圾回收,而非像并行 GC 那样针对整个新生代或者老年代进行回收。
当然,以上只是简单的举个例子,具体的回收机制肯定不是这么简单。但是无论如何,从分析结果来看,G1 GC 的效率还是很比其他垃圾回收器有很大的优势。

若有收获,就点个赞吧
0 人点赞
