Redis 有什么用?
Redis 一般作为缓存的数据库使用,原因是因为 Redis 是基于内存的,内存数据访问速度远比从硬盘文件里访问速度快。
尽管基于内存的还有诸如 Memecache,但是相比于 Redis,还是 Redis 更有优势一些:
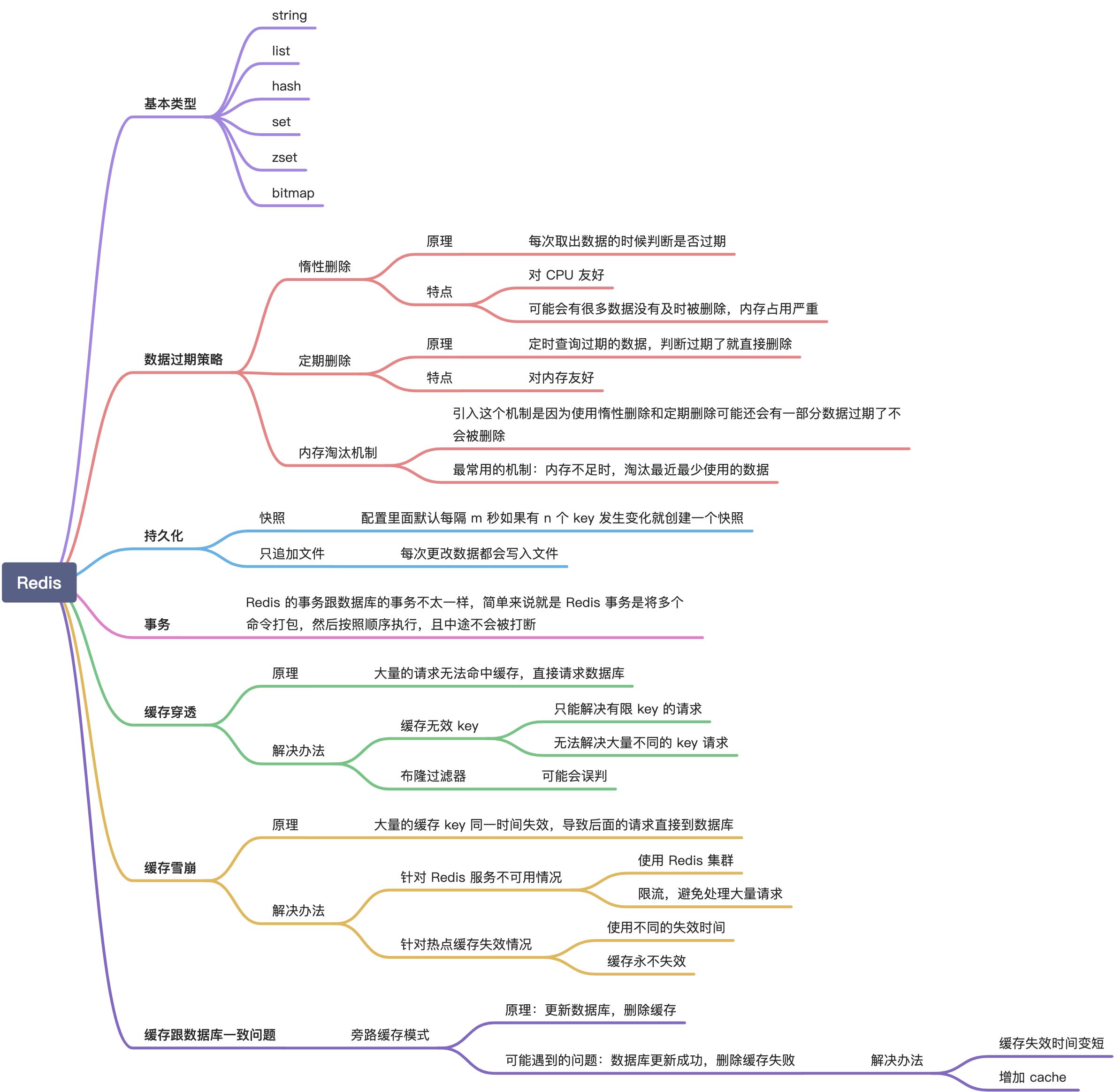
- Redis 的数据类型更加丰富,能适用更多的场景。Redis 数据类型:string、list、set、zset、hash
- Redis 支持数据持久化
- Redis 支持集群
- Redis 支持事务等
Redis 的使用场景流程图:
从流程图上看,处理逻辑是增加了,但是从性能和并发上是提高了,因为从数据库取数据是没有从内存里取数据快的。
当然,Redis 也不适合缓存所有的数据,那是数据库做的事情,一般只用来缓存热点数据,或者不太容易变化的数据。
Redis 能提高性能和并发,但也需要维护和数据库间的数据一致性。换句话说就是数据库的数据一旦变化了,就需要更新 Redis 缓存的数据。
Redis 的数据类型
上面在对比 Memecache 的时候,已经提到了 Redis 的数据类型,下面我们分别介绍下这些类型。
string
string 是 Redis 里面最基础的 key-value 数据类型,虽然 Redis 使用 C 语言写的,但是这个数据类型并不是 C 语言里面的字符串。它不仅能存储文本数据,还可以存储二进制数据
常用命令:set, get, strlen, exists, incr, decr, setex...
list
list 类型对应的数据结构是链表,Redis 里面是使用双向链表实现的。也就是说双向链表的特性也就是 list 的特性,拥有更灵活的查找方式,同时也会占用更多的存储空间。
list 类型模型 lpush —->| ———————————- |<—- rpush | [value1] [value2] [value3] | lpop <—-| ———————————- |—-> rpop
针对 list 的操作也会跟双向链表的特性有关系,比如添加数据的时候可以选择添加到头节点的的左边还是右边,取出数据的时候也是如此。根据这个特性,list 可以很轻松的实现队列和栈的数据结构。
另外 list 支持范围查找,这一点可以使用在分页查询的场景下,由于操作都在内存,所以分页查询的速度很快。
常用命令:lpush, lpop, rpush, rpop, lrange, len
hash
hash 对应的数据结构就是 JDK 1.8 之前的 HashMap 了。很适合存储对象,并且 Redis 的 hash 支持单独修改某个属性。
假设现在有一个 user 对象,里面有 name 和 age 属性,格式如下: user: {“name”: “zhangsan”, “age”: 25} 那么在 Redis 使用 hash 就可以用下面的方式: hset user name zhangsan age 25 取出全部对象数据:hgetall user 取出单个属性:hget user name 设置单个属性:hset user name xxx 同样支持获取对象的 keys 和 values: hkeys user hvals user
set
set 类型就类似 Java 里面的 HashSet,里面存储的数据是无序的不重复的,适用的场景也就很清晰了。
结合 list 类型来对比,set 类型最大的优势就是提供了判断某个成员是否在 set 集合内,同时还支持求并集,交集,差集的操作方式,这一点在判断好友关系(共同好友等)很方便。
zset
zset 类型和 set 类型在名字上很相似,前者比后者多了一个 score 参数来表示权重,有了这个权重就可以根据它来排序了。
bitmap
bitmap 存储的是连续的二进制数(0 和 1),用来表示某个元素的状态,由于每个 bit 占用的空间很少,所以会极大的节省存储空间,多用来保存一系列的状态信息,并且需要对这些状态信息进一步分析统计。

若有收获,就点个赞吧
0 人点赞
