1.Spark概述
1)简介

- Apache Spark是一种基于内存的大数据计算引擎;
一站式解决方案,集批处理、实时流处理、交互式查询、图计算、机器学习于一体;
2)应用场景
3)特点

-
4)生态圈
5)与MapReduce对比
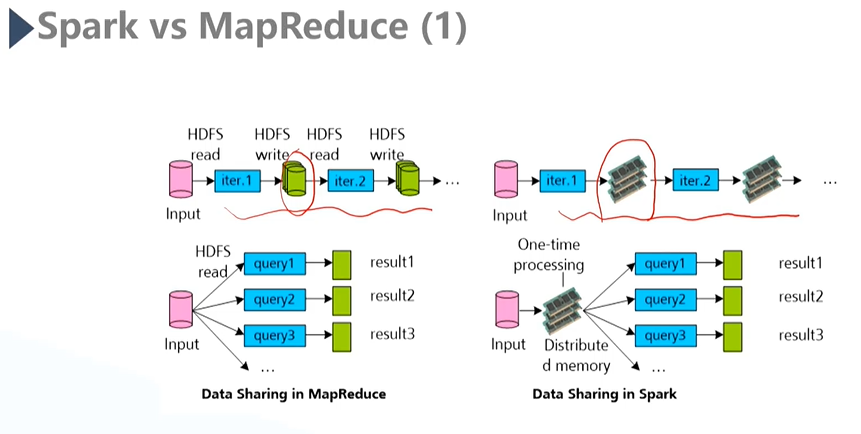

Spark基于内存,与MapReduce相比没有数据的落盘操作,没有磁盘IO产生;
2.Spark原理与架构
1)Spark体系架构
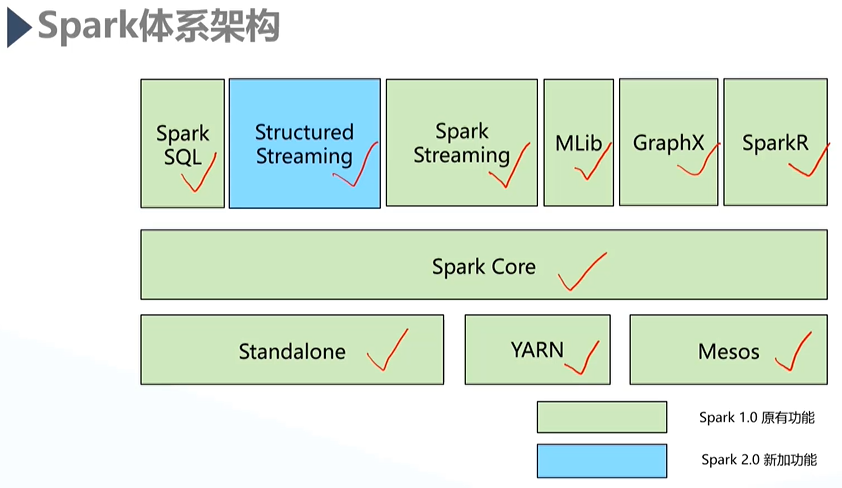
Spark SQL:流处理的相关框架;
- Structured Streaming:时延毫秒级响应的相关组件;
- Spark Streaming:
- MLib:机器学习的算法库;
- GraphX:图计算的相关的算法库;
- SparkR:Spark用R语言封装的一些接口;
- Spark Core:是Spark 的核心组件,RDD有关的API都出自于Spark Core;
- Standalone:3种部署模式之一,Spark可以有自己的主节点和辅节点;
-
2.1 Spark Core(执行引擎)
是Spark最核心的模块;


1)RDD
a.概述

b.RDD的依赖关系

- 窄依赖:一个父RDD只对应一个子RDD的依赖关系;
- 宽依赖:一个父RDD对应了多个子RDD的依赖关系;
c.Stage划分
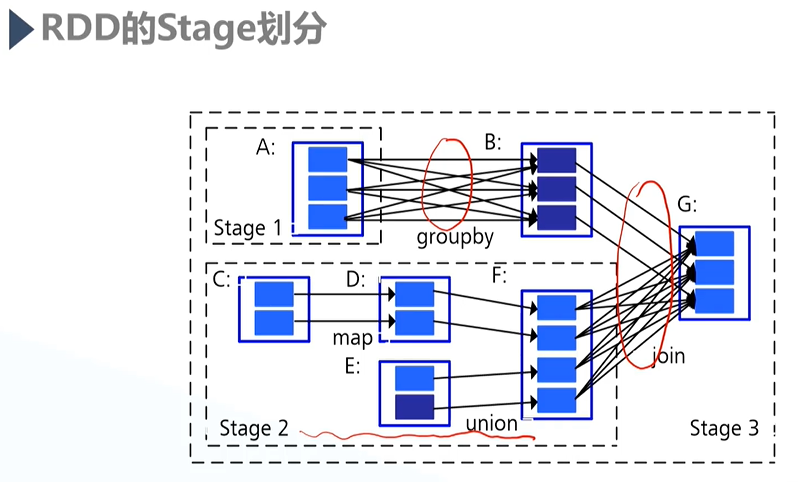
- Stage依据宽依赖来划分,每当遇到一个宽依赖就分出一个新的Stage;
- 如上图,A对B为宽依赖,F对G为宽依赖,而Stage 2内部都是窄依赖;
d.RDD算子

- Transformation算子所进行的所有操作都是懒操作,其计算过程只会被记录下来,而不会真正地去执行,只有运算调用到了Action算子时才会真正去执行对应的逻辑,因此Transformation算子多用于输出的场景,比如统计次数,输出数据至HDFS对应目录;
2)Spark重要角色


- DAG:在Spark里每一个操作生成一个RDD,RDD之间连一条边,最后这些RDD和他们之间的边组成一个有向无环图,这个就是DAG;
- Executor:真正执行具体逻辑的进程;
3)Spark运行流程
a.On Yarn-client

- Executor需要向Driver汇报任务执行情况;
b.On Yarn-cluster

- 这里AppMaster包含了Driver进程,Container最后会向AppMaster汇报;
c.两者区别

client模式下,Driver启动在任务提交节点之上,该节点宕机会造成整个任务的失败;Yarn-cluster模式的Driver启动在Yarn组件上。
4)典型架构:WordCount

textFile:将HDFS上的数据转化为RDD;
-
2.2 Spark SQL和Dataset(批处理端)
Spark SQL是Spark的一个模块,主要用于进行结构化数据的处理,DataFrame是核心的编程抽象;
1)Spark SQL概述
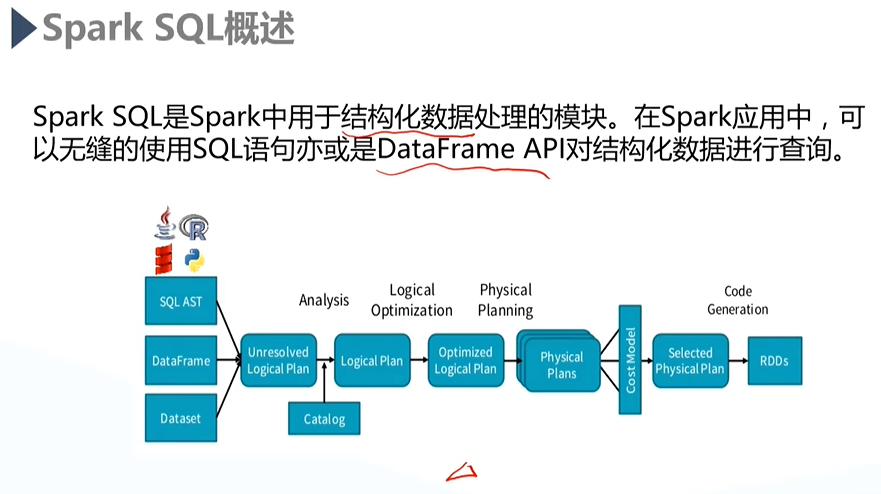
- 用作数据离线式批处理;
将SQL语句和DataFrame API转化为相应的Spark call程序执行;
2)Dataset简介

-
3)DataFrame
4)RDD、DataFrame、Dataset的比较

面向对象:如存储时会检查数据类型:数值、字符串….;
- GC:垃圾收集,Java提供的GC可以自动监测对象是否超过作用域从而达到自动回收内存的目的;


- Kroy为Spark的序列化形式;
Dataset不需要进行序列化和反序列化的开销,节省时间成本;
5)Spark SQL与Hive
2.3 Spark Structured Streaming(流式数据处理引擎)
Structured Streaming是构建在Spark SQL引擎上的流式数据处理引擎,可以实现用处理静态数据的方式去处理流数据;

1)概述




1)概述

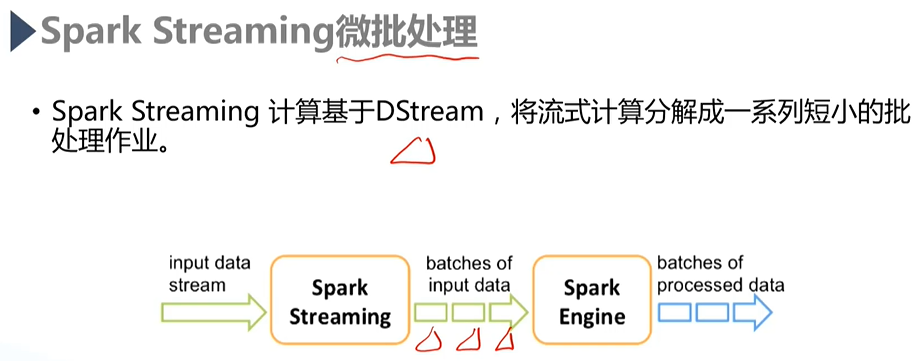
2)微批处理




若有收获,就点个赞吧
0 人点赞
