1.MapReduce和Yarn基本介绍
1)MapReduce概述

- MapReduce函数分为Map函数与Reduce函数,程序员只需编写Map和Reduce函数来实现功能;
与Hadoop集群中的其他组件相同,MapReduce同样可支持水平拓展的能力;
2)Yarn概述

Hadoop1.0时只有一个资源协调器,位于MapReduce上;随着后续Spark等组件的出现,同时也是防止资源的隔阂,便引用了Yarn组件为整个集群的计算框架提供资源分配;
- Yarn组件与HDFS都是使用Hadoop集群所必需的;

- MapReduce为集群中的一个计算框架;
2.MapReduce的功能与架构
1)任务流程
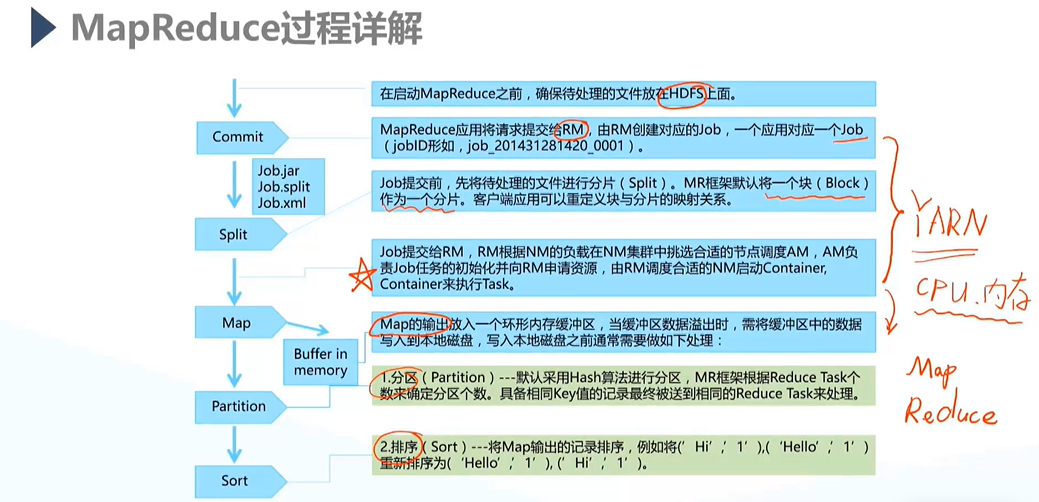

- RM为Yarn组件中的一部分;
- 分片(Split):MapReduce默认将一个数据块(Block)作为一个分片;
- 前半部分可理解为:MapReduce向Yarn提交Job后,由Yarn来分配cpu、内存等资源;
- 完成Map计算后,对于溢出数据会进行分区()、排序(Sort)、组合(Combine)、合并(Spill)操作,生成MOF文件落到磁盘上,对于MapS生成MOF文件落盘的过程被称为Map Shuffle;
- 对溢出数据的4步操作是完成落盘所需要进行的,但并非每步都会进行,且通过规定Map输出的格式,落盘时会自动完成格式的调整;
- Copy到Sort/Merge的过程称为Reduce Shuffle,是为了获取Map输出文件,并调整文件格式满足Reduce操作输入的格式;
2)Shuffle机制
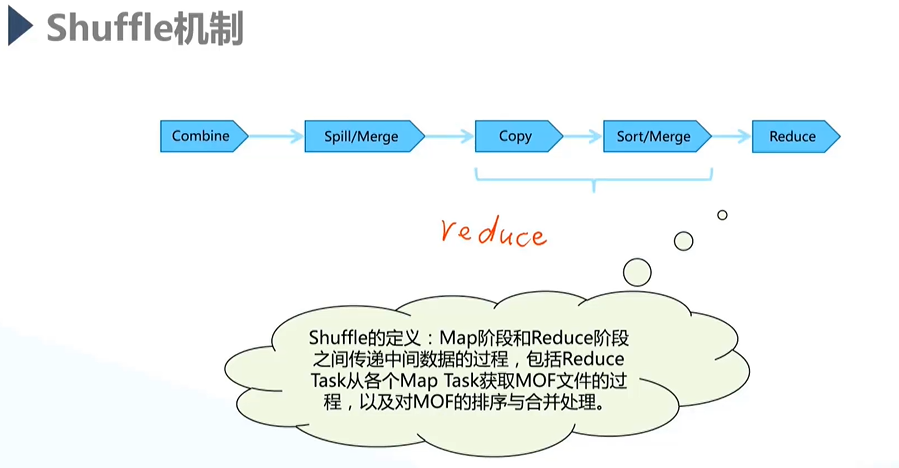
3)典型程序举例:WordCount
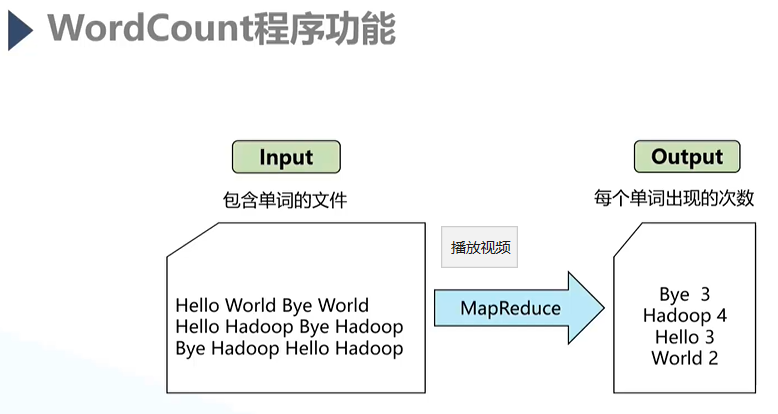
a.总体流程
1.任务开始前确保所需数据是存储在HDFS中的,且为分布式存储;
2.HDFS与Yarn组件搭配使用;
3.Map操作;
4.Reduce操作;b.实现内容
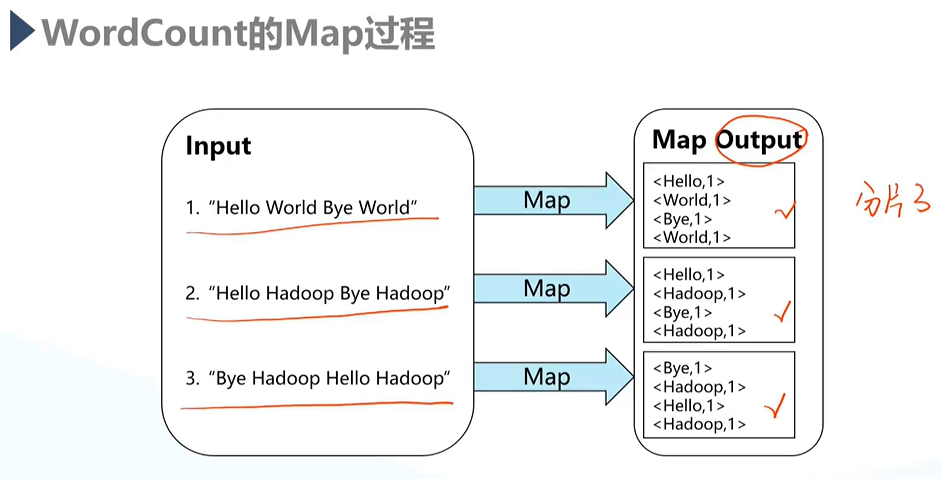
c.具体实现过程

3.Yarn的功能与架构
1)Yarn的组件架构

- Yarn组件中包括的重要角色有client、RM(Resource Manager)、NM(Node Manager)、Container、AM(App Mstr)。同一集群中可有多个Client,1个RM,多个NM;
大部分Hadoop组件都采取主仆模式:master—slave,这一点Yarn与HDFS类似; | | master | slave | | —- | —- | —- | | HDFS | 一个active的NN(NameNode) | 多个工作的DN(DataNode) | | Yarn | 一个活跃的RM | 多个工作的NM |
App Mstr是Yarn做资源调度时启用的一个进程、实例,详细功能见“流程”;
-
2)任务流程

1:Client接收到MapReduce申请资源的请求,将MapReduce应用提交到Resource Manager中,在RM中创建Job;
- RM中的Applications Manager模块用来任务管理,Resource Scheduler模块用来资源调度;
- 2、3:RM根据集群的资源调用情况,在空闲的Node Manager上启动App Mstr;
- 4:App Mstr用来评估某应用需耗费的cpu、内存,并将应用所需的资源统计反馈给RM;
- 5:知会各个空闲的Name Mstr启动Container;
- 6:各个NM启动Container将应用分发下去(即task),Container使用相应的cpu、内存来执行Map或Reduce task;
- 7:各个Container将task的执行情况统一反馈给原先的AM;
- 8:AM将最终的结果反馈给RM;
-
3)关键特性
a.HA
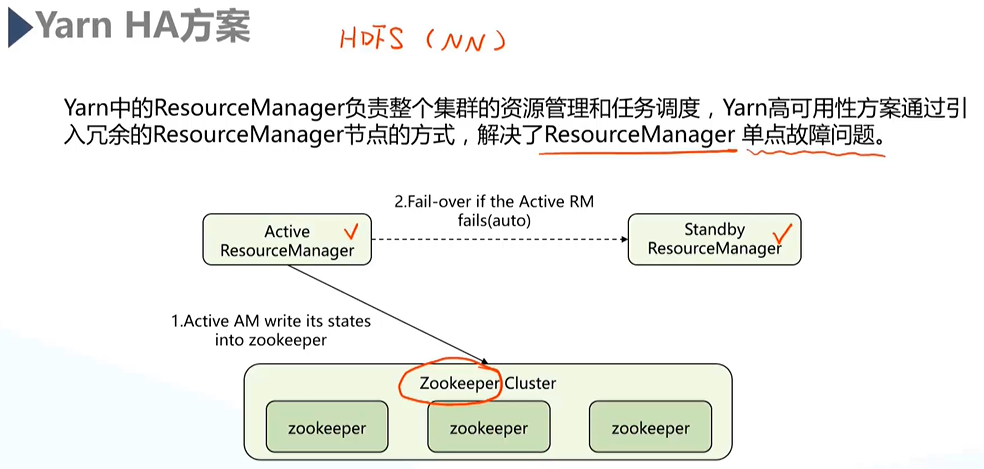
与HDFS高可靠性类似,Yarn HA同样由Zookeeper来实现Resource Manager主备的管理;
b.容错机制

4.Yarn的资源管理和任务调度
1)资源管理

- 常见参数1:表示当前Node Manager上可分给Container的物理内存的大小,必须小于Node Manager服务器实际内存大小,单位为MB;
- 常见参数2:表示Container容器设置内存限制时虚拟内存与物理内存的比值;
-
2)资源分配模型
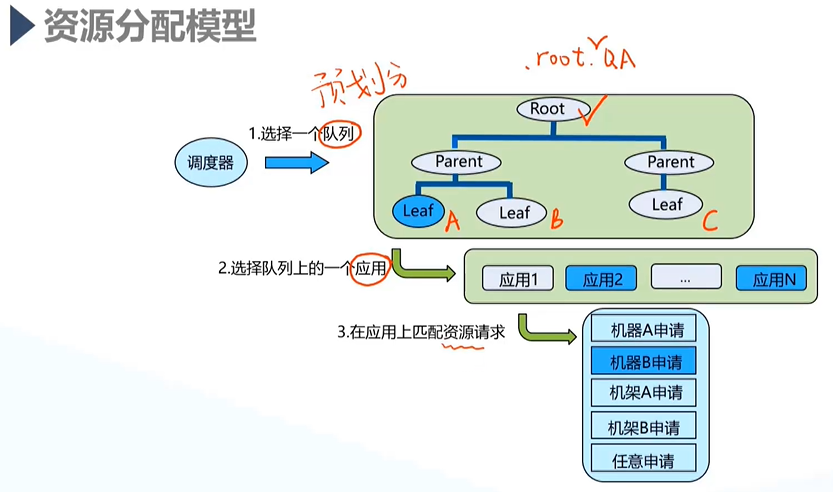
实现Yarn对任务的自动调度;
- 调度器:容量调度器(详见后文);
- 队列:对整个集群所有资源的预划分;
- 1:任务的提交可以选择队列,所有队列的根节点都是root,如参数配置时可以选择.root.parent.QA来选择A队列;
2:一个队列可能同时同时被多个任务指定使用,这时一般遵循先到先得,也根据任务优先级来确定任务执行的先后。
3)容量调度器
a.特点

-
b.容量调度器的任务选择

-
4)容量调度器对资源的限制
a.队列资源限制



- capacity:队列资源容量(百分比);

- maximum-capacity:队列最大资源使用量(百分比);
b.用户限制

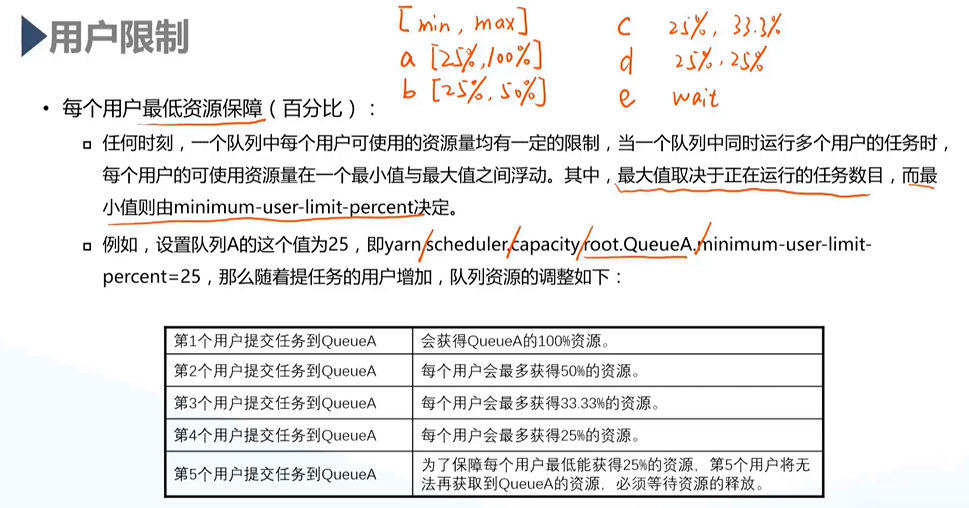
- minimum-user-limit-percent:用户最低资源保障(百分比);
- 用户可使用资源最大值由正在运行的任务数目决定;

- 一个用户最多可使用的资源量不超过所在队列capacity的[user-limit-factor]倍,同时也不得超过maximum-capacity;
c.任务限制

- 最大用户数是对于整个集群而言的
d.查看队列信息

5.增强特性
1)动态内存管理

2)基于标签调度
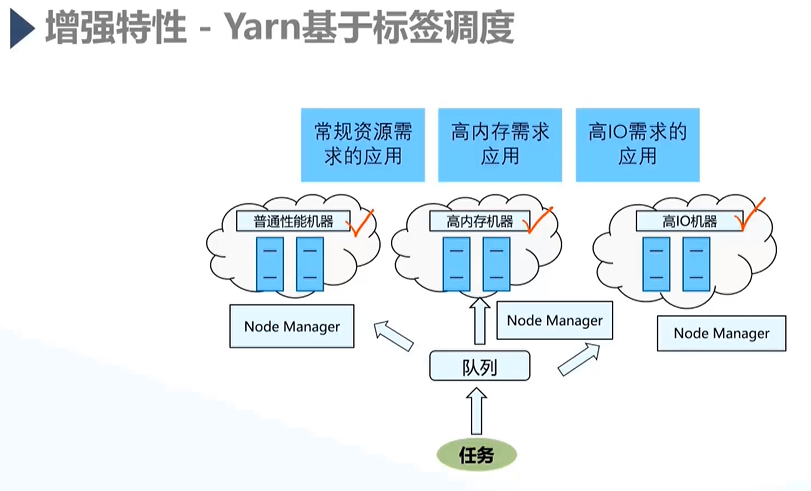
- 对于不同的标签基于不同的任务类型进行调度;

若有收获,就点个赞吧
0 人点赞
