1.概述
何为文件系统?
文件系统由文件名、元数据(Metadata)和数据块(Block)组成,文件系统好比一本新华字典,不同的是字典通过部首、检字表、索引来找到所需要的字,而这些正是这个字的属性;而文件系统中,元数据指的是系统中数据的数据,包括文件创建的时间、大小、位置等,数据块则为实际存储时的一个位置和大小。

2.架构
client:负责外界请求的响应,通过与NameNode,DataNode的交互来反馈给外界,给出响应;
NameNode:存储元数据,Metadata,包括一些位置信息,文件的大小等等;
DataNode:实际存储数据的部分,Block位于这一部分中,而一个block有存储上限(128M);
- NameNode与Client之间存在元数据心跳(Metadata ops),NameNode与DataNode存在block心跳,这些心跳持续地以一定间隔来向上反馈。
- HDFS存储时数据以3副本(默认)的形式存放,在DataNode内部执行Replication的复制操作,以block为单位复制。
- NameNode存储是基于内存的,会在内存中存储一份完整的元数据,在机房下电、重启时这些元数据会进行落盘,落于磁盘上,来确保元数据不会消失;DataNode存储是基于磁盘的。
3.流程
1)写入

- 2.create是在NameNode中新建1个节点,用于之后自身元数据的存储;
- 重复的第4、5步,是为了遵循存储的3副本机制,4为以数据包形式写入数据,5为对数据写入的答复;
- 6.close:将所有的连接关闭
7.complete是在NameNode当中将元数据补充完整;
2)读取

NameNode是基于内存的,存储大量小文件会受到内存的限制,众多的元数据容易造成内存频繁的溢出,使得无法保存完整的元数据。
4.关键特性
1)高可靠性(High Availability)

- 主要通过zookeeper组件完成,zookeeper为其他所有组件提供分布式协调服务的,目的是为了达到集群的高可靠性;
- 在一个HDFS集群当中,只存在一个active的NameNode,但会有备用的NameNode(stand by),多个DataNode和Client。主备NameNode的管理和切换由Zookeeper进行监控,其切换操作主要由ZKFC实例来控制,主备切换过程涉及元数据持久化;
JN主要存储EditLog,EditLog是元数据操作的日志文件;
2)元数据持久化

元数据持久化其意义在于将内存中的元数据同步于磁盘,下点、重启后可重新将元数据由磁盘提取出来;
- 备NameNode是不进行具体的元数据的操作的,只存储于磁盘来进行备份,是不存在于内存中的;
- Fsimage:某一时间戳下内存中的元数据的一个快照,存在于磁盘上主NameNode的备份位置,t0时刻的Fsimage是可以和t0时刻内存中的Meatdata划等号的;
- EditLog:记录元数据操作的日志文件,存在于JN上;
例如t0时间点做了元数据持久化,经过一段时间后到了t1时刻,此时磁盘中的Fsimage仍处于t0时刻,内存中的Metadata为t1时刻,而由t0至t1时刻过程中元数据的变化会记录在EditLog中,磁盘上主NameNode节点的EditLog和Fsimage合并生成Fsimage.ckpt文件,这份新生成的快照文件会传回主节点,并回滚到主节点t0时刻Fsimage快照文件上,更新文件为t1时刻的Fsimage。在这一切完成后时间为t2时刻,而t1至t2这一段时间内元数据新的操作日志就记录在步骤1时创建的EditLog.new文件中,并在第5步回滚到EditLog上,更新后的EditLog文件用于下一次的元数据持久化;
3)联邦特性(Federation)
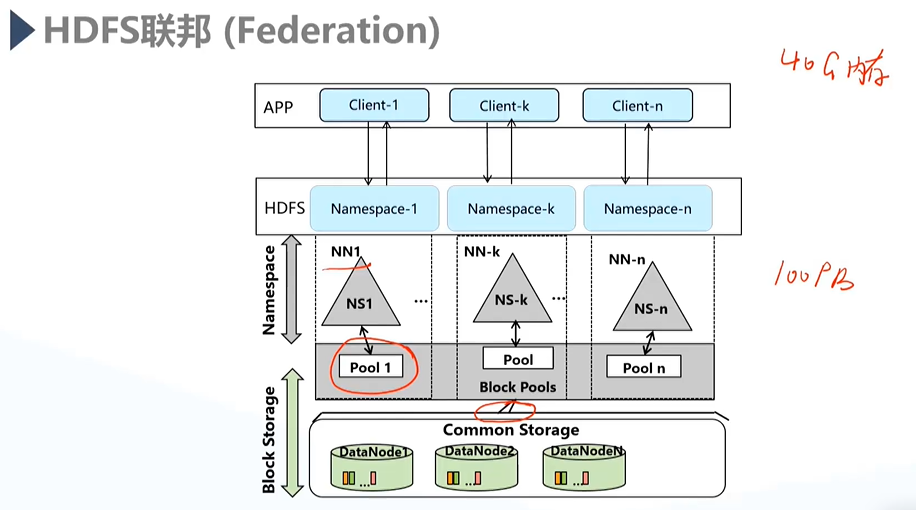
由于NameNode基于内存存储,HDFS的水平拓展易受到内存限制,如无法新建DataNode节点,使得性能无法提升;
- 通过设置不同的Namespace,即建立与对应的NameNode和每一个NameNode对应的资源池pool。pool资源池被各自的NameNode单独使用,NameNode和pool一起称为Namespace;
- 与HA不同,联邦机制提供了若干个彼此独立的NameNode,所有Namespace彼此相互独立但可以共同操作底层的DataNode;
-
4)数据副本机制

HDFS默认有3副本机制,因此进行数据读写时会有先后数据;
- 机架感知原理:同一服务器内distance=0,同一机架不同服务器之间distance=2,不同机架之间distance=4。如,Client与B1距离为0,与B3距离为2,与B2、B4距离为4;
- 读操作:读取遵循就近原则;
- 写操作:先写最近,再写最远,最后写中间距离的;

若有收获,就点个赞吧
0 人点赞
