图像分类
目的: 需要对于输入的图像赋予一个标签,这个标签用在指定的类别集合中
例如一个图像像素是 248*400 具有rgb三原色 那么 在计算机中图像是由297600个数字组成的,每一个数字都是0-255 那么我们最终的目的就是将这些数字变成一个单独的标签 例如 cat
识别的功能对于人眼来说是很简单的 但是计算机识别有喝多困难
- iewpoint variation:单个物体从不同的角度照出来的图像
- Scale variation:展现出的图像大小会变化
- Deformation:许多物体的边缘可以形成不同的形状形式
- Occlusion:关注的某个物体会被遮挡,只有一小部分会被显示出来
- Illumination conditions: 光照对像素级的影响很大
- Background clutter: 感兴趣的物体与环境融合,很难进行区分
- Intra-class variation: 物体的类别非常广泛相近,例如椅子,这些对象有许多不同的类型,每个都有自己的外观
临近比较
这一种比较方法我们在测试上只能达到38.6% 的方法 后面着重介绍的state of the art(SOTA,前沿的)的卷积神经网络取得的效果95%
存在问题
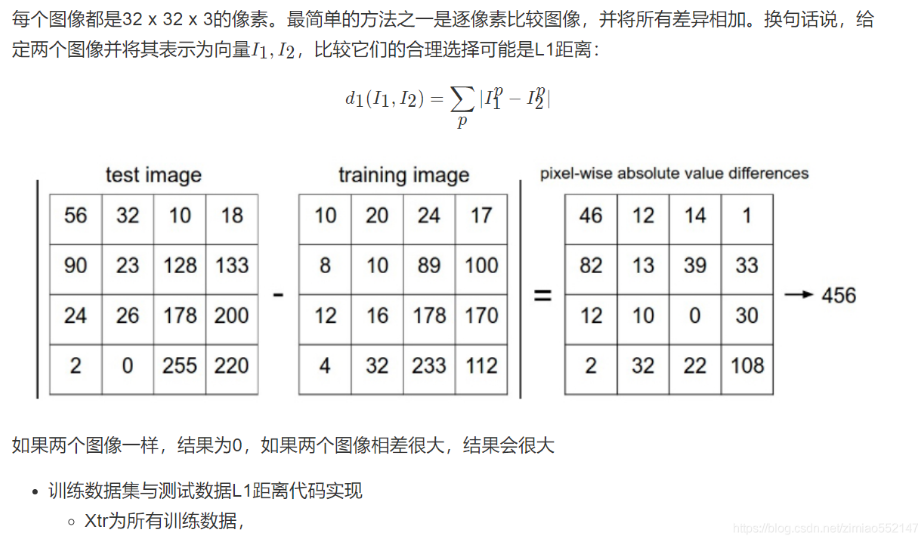
我们比较两个向量之间的距离对于高维的数据【图像】 来说,像素的距离不是非常直观,例如上面图像中图一是原始图片但是 其他三张图片和原始图片的向量距离都是一样的
线性分类
现在,我们将开发一种功能更加强大的图像分类方法。最终将其自然地扩展到整个神经网络和卷积神经网络。线性分类方法。这种方法来主要由两部分,一个函数将输入数据映射到一个类别分数,另一个就是损失函数来量化预测的分数与目标值之间的一致性。回到之前的CIFAR-10例子,输入训练图像的数据集50000张图片, 向量维度D = 32 x 32 x 3 = 3072像素,K大小为10个类别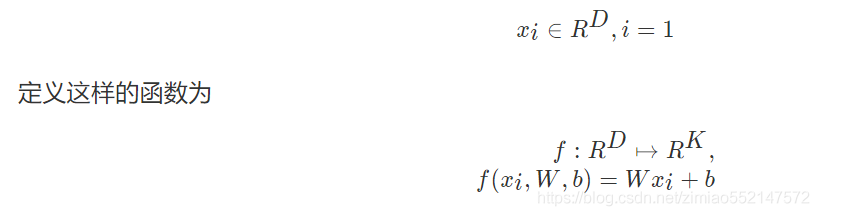
我们可以控制参数w,b的设置。我们的目标是设置这些参数,以便计算出的分数与整个训练集中的目标值标签相匹配。这种方法的一个优点是利用训练数据来学习参数w,b,但是一旦学习完成,我们就可以丢弃整个训练集,只保留学习到的参数。


若有收获,就点个赞吧
0 人点赞
