神经网络优化
我们都知道在解决神经网络问题中最头疼的就是将损失函数求解最小化w 的过程, 那么我们给损失问题定义了一个简单的描述,并非最优化的数学定义
过程描述: 在神经网络中,f对应的是损失函数L,输入的x里面包含训练数据和神经网络的权重。比如说损失函数可以是softmax 的损失函数,为此,即使能够使用方向传播的方式计算输入数据xi 上的梯度,但是在实践中为了进行参数的更新,通常也只能计算w,b 的梯度。 当然xi 的梯度有时仍然是有用的,比如将神经网络所作的事情可视化便于直观理解的时候,就可以用上.
梯度下降
目的 : 这样可以让损失函数的值找到最小的值
函数的梯度 指出了函数最陡峭的地方,梯度的方向走,函数增长的就比较快, 按照梯度的负方向周,函数自然就降低的最快。 而我们模型训练的目的就是寻找合适的w和b 以最小化 代价函数值。那么我们假设w 和b 都是一维的实体,那么我们自然可以得到j 关于w 以及b 的图像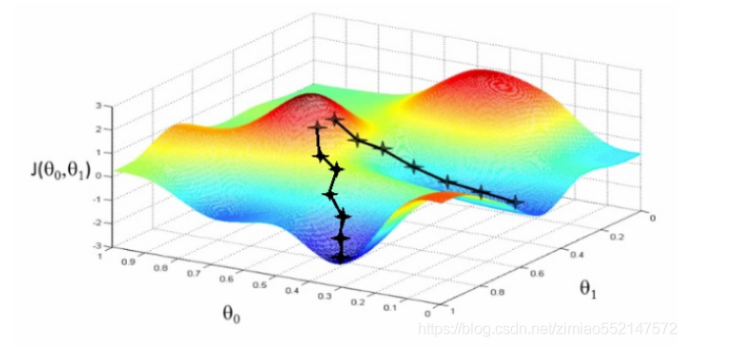
为此我们w 以及 b 的更新公式就是 这样的: 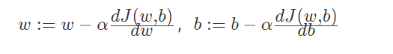
tips: 其中 α就代表的学习的速率,也就是每次更新的时候w 的步伐长度,当 w 大于最优解w’的时候 导数是大于0的,那么w 就会向更小的方向更新, 相反如果w 小于最优解 w’的时候 导数是小于0的 那么w 就会向更大的方向更新,迭代直到收敛。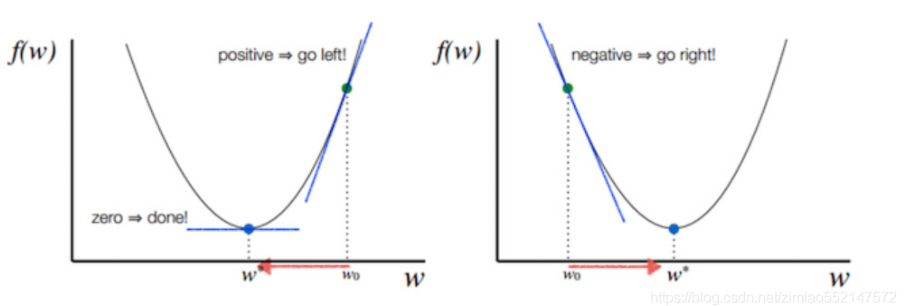
反向传播
导数

正向传播例子
我么拿一个简单的函数来计算一下导数计算的流程: J(a,b,c) = 3 (a + bc) 并且 我们有以下计算过程:

这个时候我们需要从左到右计算出导数dv 以及da 假定我们 变量中 b = 4 , c = 2 , a = 7 , u = 8 , v = 15 , j = 45
那么我们可以得出: 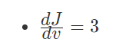
以及 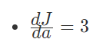
为此上图计算的算式可以展开计算: 那么我们j 相对于a 的增量可以理解为j 相对于 v 相对于a 增加的量
那么我们j 相对于a 的增量可以理解为j 相对于 v 相对于a 增加的量
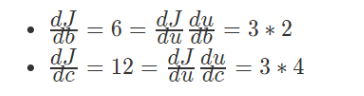
那么我们计算的过程可以画出一下计算路线: 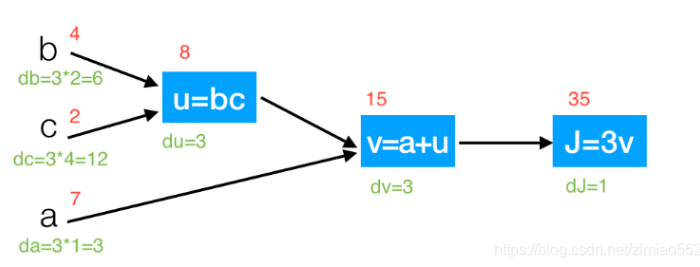
而神经网络中显示的就是计算过程, 神经网络中提到的前向传播就是从输入计算到输出 ,反向传播从尾部开始,根据链式法则递归地向前计算梯度(显示为绿色),一直到网络的输入端。
反向传播
具体推导过程看这篇文章: 原文
总结
在反向传播的过程中,门单元门将最终获得整个网络的最终输出值在自己的输出值上的梯度。链式法则指出,门单元应该将回传的梯度乘以它对其的输入的局部梯度,从而得到整个网络的输出对该门单元的每个输入值的梯度。

若有收获,就点个赞吧
0 人点赞
