目录与学习目标
1:索引总览2:二叉树(Binary Search Tree)3:红黑树(Red/Black Tree)4:B-Tree5:B+Tree(B-Tree的变种)6:Hash索引7:MyISAM索引引擎 与 InnoDB索引引擎1:数据库引擎索引2:MyISAM索引文件和数据文件是分离的3:InnoDB索引实现8:InnoDB索引引擎总结9:联合索引(排好序概念的深度理解)
1:索引总览
索引引擎结构(重要 重要 重要 )(先有印象):InnoDB索引引擎 索引可以存储 data数据本身MyISAM索引引擎 索引可以存储 data的地址什么是索引:索引 是帮助MySQL高效获取数据 的排好序的数据结构索引是排好序的数据结构(哪怕该索引插入进去的时候是无序的,它也会进行索引维护来排序)数据的查询效率 看的是进行IO的次数树越高 需要进行 IO次数 也就越多索引数据结构二叉树(无法解决平衡 无法解决树高)红黑树(解决局部平衡 无法解决树高)B-Tree (无法极致的解决树高 无法极致的解决范围查找)B+Tree (MySQL索引使用数据结构 支持等值查找 支持范围查找)Hash表(仅限于 等值查找 不支持范围查找)
注意:索引引擎 的结构:仅代表存放数据与索引的位置(文件位置)索引 的数据结构:存放数据与索引的的数据结构
2:二叉树(Binary Search Tree)
数据无序:select * from table where Col2=891:如果没有索引 全表扫描磁盘 需要查找6次2:如果有二叉树索引 需要查找2次数据递增:select * from table where Col1 = 61:如果没有索引 全表扫描磁盘 需要查找6次2:如果有二叉树索引 也是需要查找6次这也就是为什么MySQL当数据是递增(自增的主键)的时候,为什么不选择二叉树的原因。
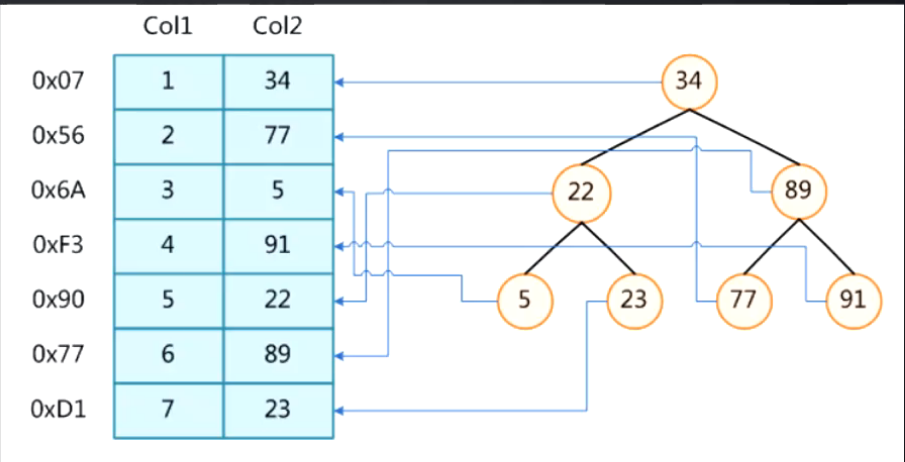
3:红黑树(Red/Black Tree)
1:根节点是黑色的2:其他节点是红色或黑色3:每个红色节点必须有两个黑色的子节点(从每个叶子到根的所有路径上不能有两个连续的红色节点)4:从任一节点到其每个叶子的所有简单路径都包含相同数目的黑色节点遵循如上规则的二叉树被称为红黑树,但是为什么要定义成如上规则呢?事实上,如上所有的规则都只想做一件事,让二叉树尽可能的平衡。

当数据量大的时候 树会变得特别特别高从根节点到对应的叶子节点的查询效率非常慢最根本的问题:树的高度
4:B-Tree
1:节点中的数据索引从左到右递增排列2:叶节点具有相同的深度,叶节点的指针为空
注意:所有索引元素不重复特点:非叶子节点可以存储data(真正的数据)
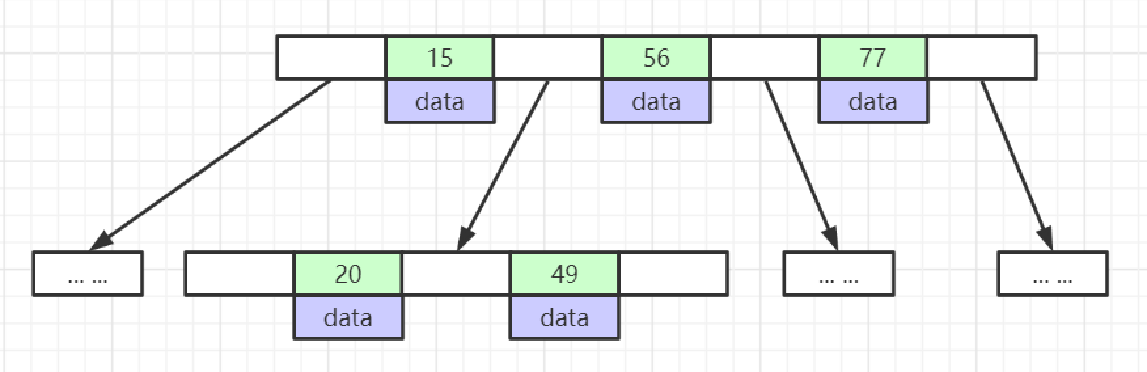
设置每一个索引页最多存储4个索引子页(注意索引元素不重复)
5:B+Tree(B-Tree的变种)
1:节点中的数据索引从左到右递增排列2:叶节点具有相同的深度,叶节点的指针为空
注意:索引元素会重复特点1:非叶子节点不存储data,只存储索引(冗余),可以放更多的索引2:叶子节点包含所有索引字段3:叶子节点用指针连接,提高区间访问的性能
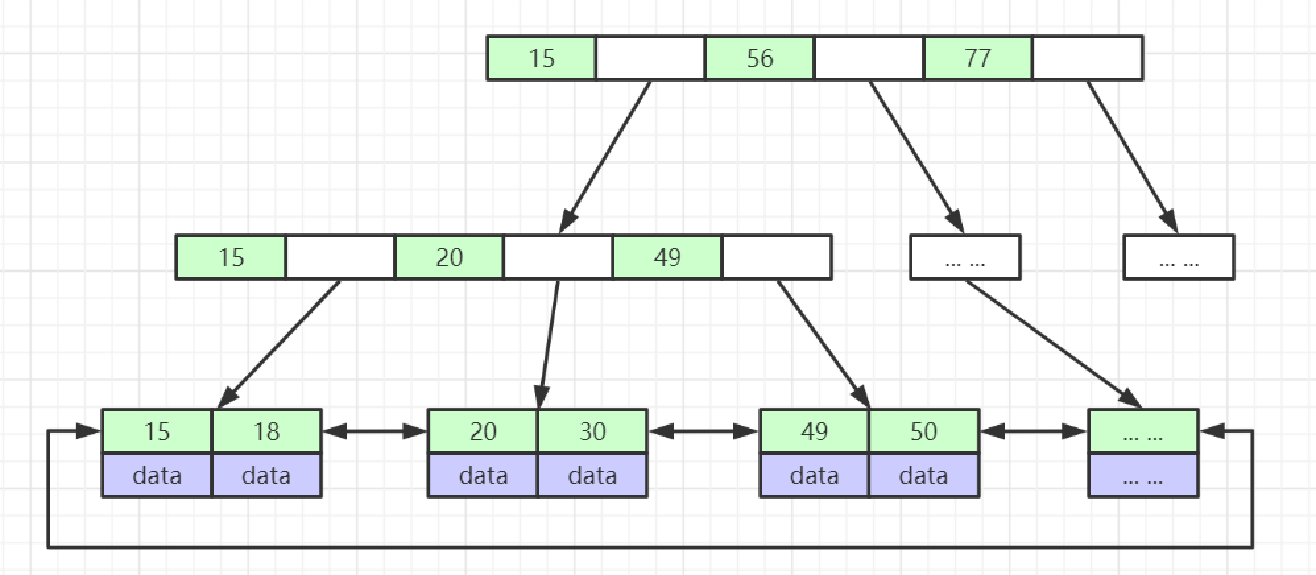
设置每一个索引页最多存储4个索引子页(或数据)(注意索引元素可能重复)
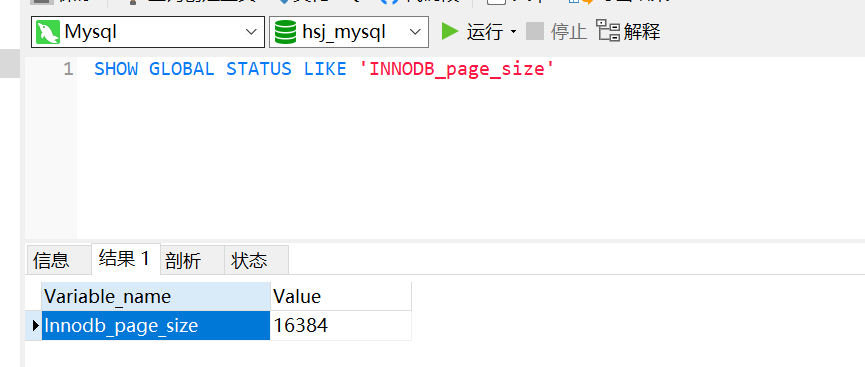
如何进行查找:比如查找301:把根节点的索引数据页 加载到内存(慢) 使用折半查找(二分法)(快)2:查找到 15的索引数据页3:把15的索引数据页 加载到内存(慢) 使用折半查找(二分法)(快)4:查找到 20的索引数据页以此类推5:查找到30这个索引 然后使用这个索引去磁盘里面找数据(慢)查找索引所在索引页的位置 相对于 磁盘IO来说 可以忽略不计Mysql 的每一个索引页有多大:16KB(官方默认值 不建议修改)SHOW GLOBAL STATUS LIKE 'INNODB_page_size'MYSQL索引的最大数据类型为bigint(8个字节) 索引指向地址的指针6个字节16KB 的索引页可以存储 16KB 除以14字节 = 1170那么进行两次索引页的IO就可以查找到 1 368 900 个索引最后还需要进行一次叶子节点索引页的IO假设一个Data为1KB(后面提及)那么一个索引页可以存储 16个DATA那么三次IO一共可以查询:21 902 400(2千万条数据)注意:通过最后叶子节点的链表 实现 范围查询 (对比Hash 索引 后文会提及)
6:Hash索引
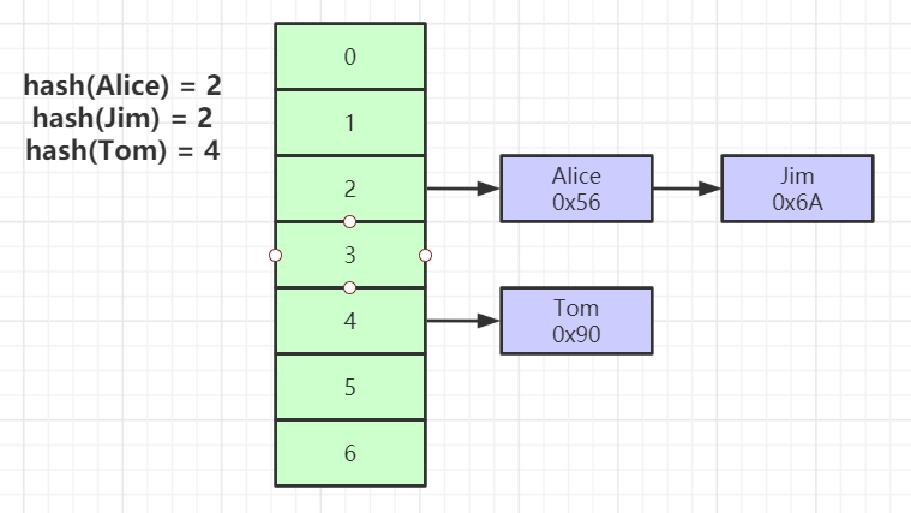
Hash对索引的key进行一次hash计算就可以定位出数据存储的位置很多时候Hash索引要比B+ 树索引更高效理想情况下一次就可以定位到数据存储的位置hash冲突问题(使用hash碰撞+链表结构 形成hash桶结构)但仅能满足 “=”,“IN”,不支持范围查询如:name>Alice 导致需要全表扫描
7:MyISAM索引引擎 与 InnoDB索引引擎
1:数据库引擎索引
两者索引都是表级别的索引。(新增表的时候可以选择存储引擎)
2:MyISAM索引文件和数据文件是分离的
tableName_myisam.frm(表结构)tableName_myisam.MYI(索引文件)tableName_myisam.MYD(数据文件)索引和数据分开存储的B+Tree索引下查询步骤:select * from tableName where iCol1 = 301:查询索引文件 tableName_myisam.MYI 查找 iCol1的索引2:查询方式按照上述 B+ 树的查找方式3:获取 iCol1 = 30 的 数据地址(OxF3)3:根据 数据地址(OxF3) 查询数据文件 tableName_myisam.MYD 的对应数据
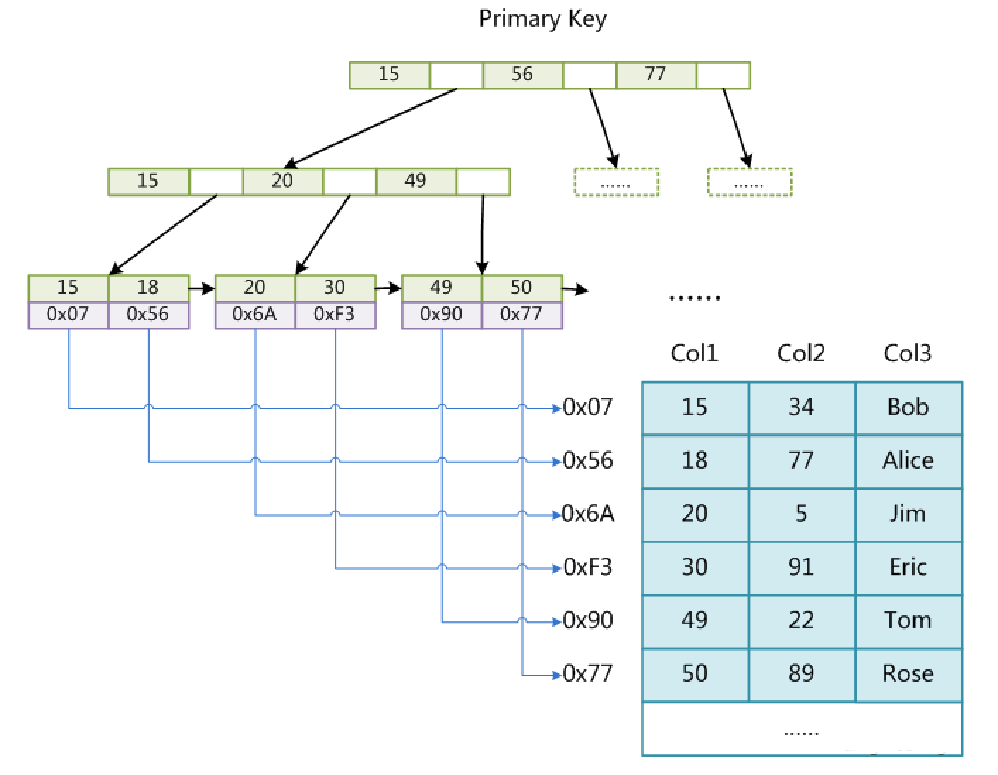
3:InnoDB索引实现
tableName_innodb_lock.frm(表结构)tableName_innodb_lock.ibd(索引文件 和 数据文件)索引和数据存储在一起表数据文件本身就是按B+Tree组织的一个索引结构文件为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?这里面包含两个问题:1:要有主键 2:整型的主键 3:自增的主键1:如果不建立主键,表会默认进行每列遍历,如果哪一列的数据没有重复则取该列为主键都有重复的话,则新增一个隐藏列。2: 索引页比对大小,整型是比较数字大小,字符串是比较每一个字母ASCLL码大小索引存储的空间,整型比字符串小。3:自增的主键,不需要经过索引页的复杂的重排。为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)其中又分 聚集索引 和 非聚集索引InnoDB的主键(有且唯一) 是聚集索引(主键索引) 叶节点包含了完整的数据记录(一整行数据 )InnoDB的其他索引 是非聚集索引(二级索引) 存储的是主键的位置 (回表操作)
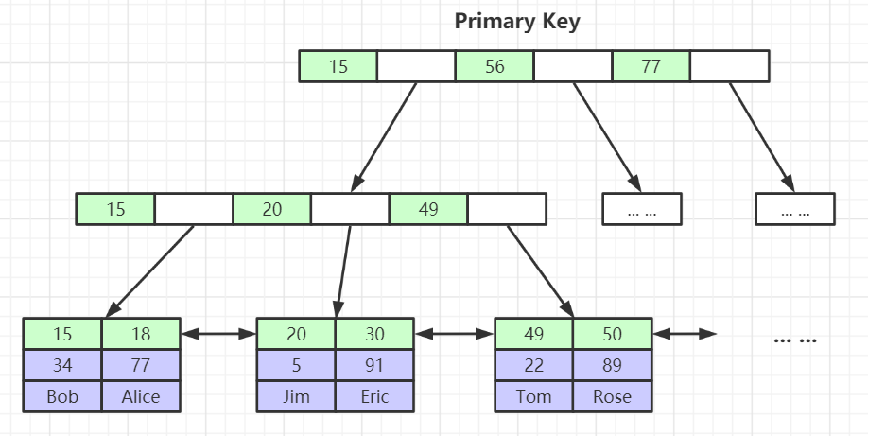
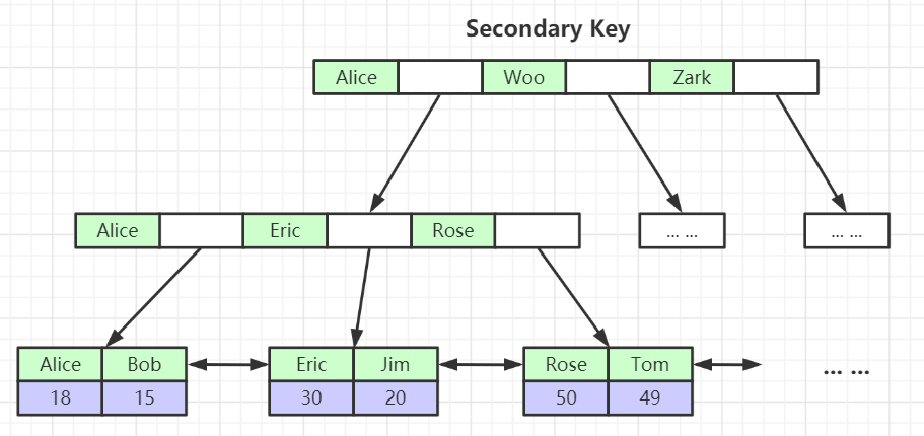
8:InnoDB索引引擎总结
MySQL正常情况下都是选择InnoDB引擎:仅代表存放数据与索引的位置(文件位置)而InnoDB引擎又选择使用B+Tree索引(存放数据与索引的的数据结构)InnoDB索引引擎 (索引文件 和 数据文件 放在同 一个文件)B+Tree:主键索引(聚集索引) :存储该索引 对应的行的所有数据非主键索引(非聚集索引):存储主键索引的数据然后需要回表操作(查询主键Data 再查询其他数据信息)
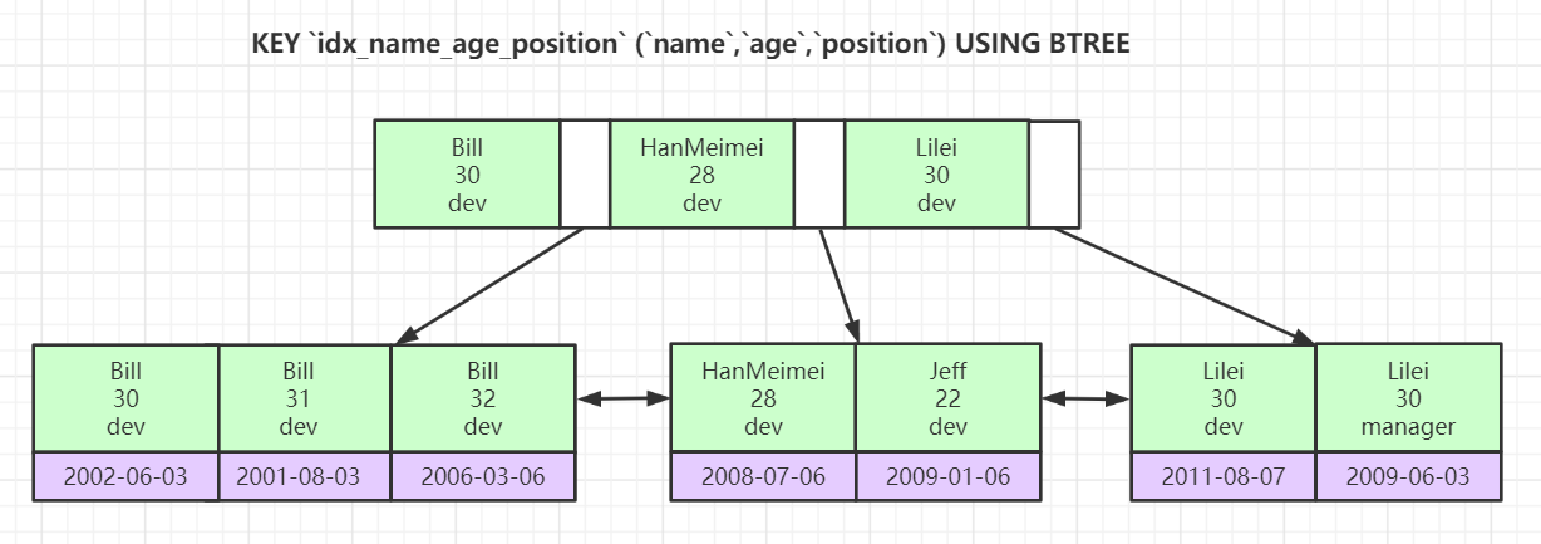
9:联合索引(排好序概念的深度理解)
最左匹配原则:先看最左边的字段Key 'idx_name_age_postion' (`name ` , `age` ,`postion`) USING BTREEExplain select * from emplayees where name ='Bill' and age =31 ;Explain select * from emplayees where age =30 and position ='dev' ; (不走索引)Explain select * from emplayees where position ='manger' ; (不走索引)因为:索引必须排好序 如果不限制 name 那么在整张表里面age并没有排好序

若有收获,就点个赞吧
0 人点赞
