目录与学习目标
1:什么是索引2:哈希表3:有序数组4:搜索树5:InnoDB模型所选择的B+树6:索引维护
1:什么是索引
索引就是目录,是用来提供查询效率的,
是帮助MySQL高效获取数据 的排好序的数据结构。
最常见的三种索引
哈希表 有序数组 搜索树
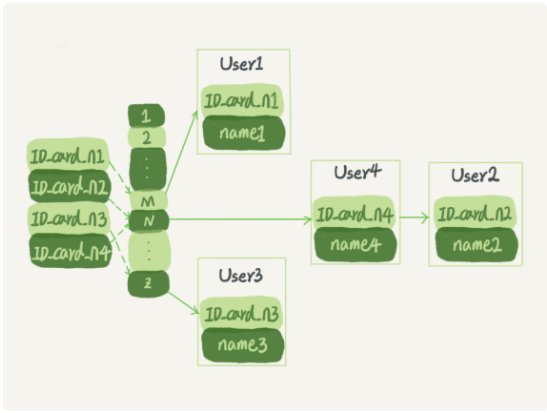
2:哈希表
哈希表:key转换成hash值(key经过Hash函数处理)后,hash值存放到哈希数组中,
相同的hash值则用拉链(无序)的方式展开。
遍历:
1:先到哈希数组中hash值
2:拉链中key的value值。
适用范围:
由于链表中的数据不是顺序排放的,
因此:仅适用于等值查询的场景;(不适用于范围搜索)
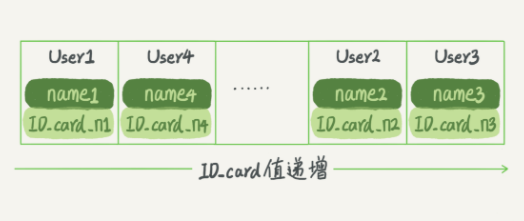
3:有序数组
顾名思义有序的的数组 二分法(查询为 O(log(N)))
适用范围: (有序数组索引只适用于静态存储引擎)
由于更新数据的时很麻烦,往中间插入一个记录就必须得挪动后面所有数据
因此:适用于 等值查询 或者 范围查询
4:搜索树
二叉搜索树:平衡二叉树
二叉搜索树的特点是:
父节点左子树所有结点的值小于父节点的值,右子树所有结点的值大于父节点的值
二叉搜索树效率:
查询 更新 的时间复杂度均为O(log(N))
存储数据:
存储100w的数据为 2的20次方 需要20次查询数据块
此时二叉树的树高为21
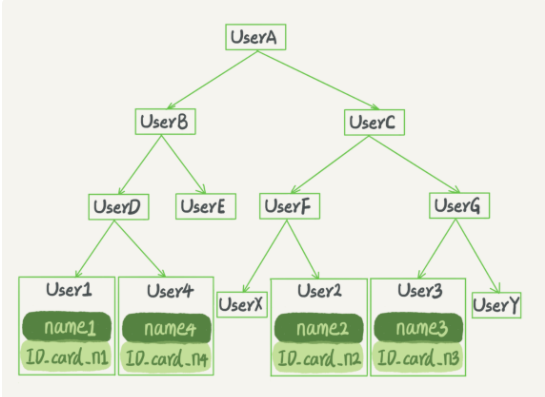
解决方法:N叉树
为了让一个查询尽量少地读磁盘,就必须让查询过程访问尽量少的数据块。
要使用“N 叉”树。这里,“N 叉”树中的“N”取决于数据块的大小。
5:InnoDB模型所选择的B+树
在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为索引组织表。
InnoDB 使用了B+ 树索引模型,每一个索引在 InnoDB 里面对应一棵 B+ 树。
我们有一个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引。
create table T(
id int primary key,
k int not null,
name varchar(16),
index (k)
)
engine=InnoDB;
主键索引的叶子节点存的是整行数据。
在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
非主键索引的叶子节点内容是主键的值。
在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
主键索引的查询
select * from T where ID=500
只需要搜索 ID 这棵 B+ 树
非主键索引的查询
select * from T where k=5
需要先搜索 k 索引树,得到 ID 的值为 500,再到 ID 索引树搜索一次。这个过程称为回表。
6:索引维护
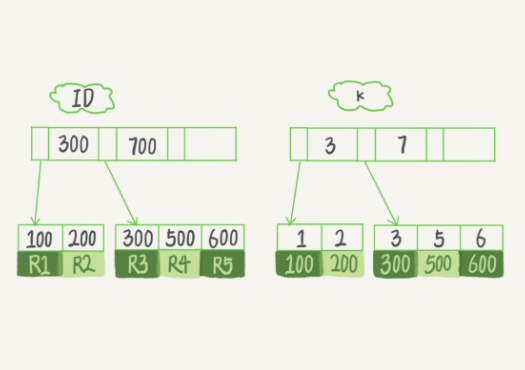
B+ 树为了维护索引有序性,在插入新值的时候需要做必要的维护。
如果插入新的行 ID 值为 700,则只需要在 R5 的记录后面插入一个新记录。
如果新插入的 ID 值为 400,则需要逻辑上挪动后面的数据,空出位置。如果 R5 所在的数据页已经满了,根据 B+ 树的算法,需要申请一个新的数据页,然后挪动部分数据过去。
这个过程称为页分裂。这时性能自然会变低,同时页分裂操作还影响数据页的利用率。
基于索引维护的过程我们对主键ID 有以下选择
主键ID的选择1:
在建表的时候使用SQL:
NOT NULL PRIMARY KEY AUTO_INCREMENT。(自增主键的插入数据模式)
主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
从性能和存储空间方面考量,自增主键往往是更合理的选择。
主键ID的选择2:
业务字段直接做主键
1:只有一个索引;
2:该索引必须是唯一索引。
(由于没有其他索引,不用考虑其他索引的叶子节点大小的问题。)

若有收获,就点个赞吧
0 人点赞
