目录与学习目标
1:如何恢复已经进行写入的数据2:redolog(重做日志)(InnoDB 引擎特有的日志)3:binlog(归档日志)(Server 层日志)4:两阶段提交(数据恢复问题)
1:如何恢复已经进行写入的数据
与查询流程不一样的是,更新流程还涉及两个重要的日志模块(redolog binlog)这两个日志模块正是恢复数据的关键。
2:redolog(重做日志)(InnoDB 引擎特有的日志)
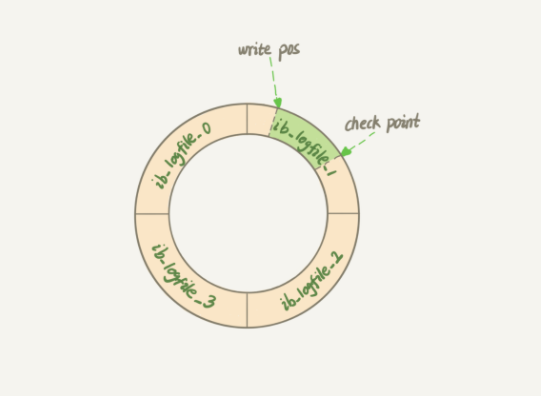
如果每一次的更新操作都需要写进磁盘(磁盘需要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高)redolog的应用:角色:酒店(系统) 黑板(日志) 账本(磁盘)任何修改记录先写黑板,在任何情况下(在酒店突然停电的情况下),可以保证黑板的内容不丢失,可以后续空闲时黑板的记录(提交)到账本,crash-safe能力。黑板的存储结构write pos 是当前记录的位置,一边写一边前移checkpoint 是当前要擦除的位置,一边写一前移两者之间为可用空间write pos 和 checkpoint 之间的是“黑板”上还空着的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示“黑板”满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下。
3:binlog(归档日志)(Server 层日志)
MySQL 整体来看,其实就有两块:一块是 Server 层,它主要做的是 MySQL 功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。上面我们聊到的粉板 redo log 是 InnoDB 引擎特有的日志,而 Server 层也有自己的日志,称为 binlog(归档日志)。
binlog 会记录所有的逻辑操作(具体每一条语句 用于数据恢复)binlog 与 redolog 的区别redolog:InnoDB 引擎特有的 空间有限,物理日志,在什么数据页上做了什么修改binlog:所有引擎都有(Server层实现) 空间追加,逻辑日志,修改的原始语句
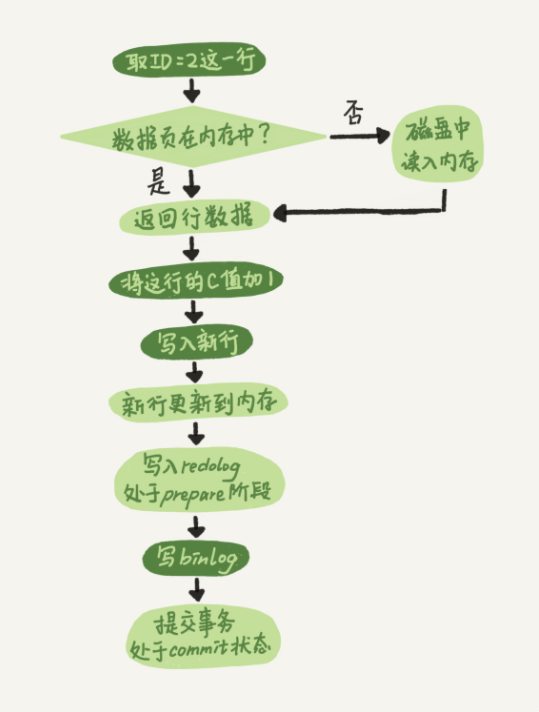
update时候的流程在进行查询逻辑之后,再进行以下的执行器逻辑
4:两阶段提交(数据恢复问题)
为什么需要两阶段提交,即是这是为了让两份日志之间的逻辑一致。为什么需要两份日志之间保持一致呢?我们先了解一点,这两份日志的作用是为了数据恢复,那我们是不是直接在数据恢复这里找原因就行了?先让我们看看我们是如何进行数据恢复的:1:首先,找到最近的一次全量备份,如果你运气好,可能就是昨天晚上的一个备份,从这个备份恢复到临时库;2:然后,从备份的时间点开始,将备份的 binlog 依次取出来,重放到:误删表之前的那个时刻。
redolog与binlog的先后提交问题?redolog先提交,crash,主数据库修改:某行数据update成true ,binlog没有记录,使用binlog备份数据库,从数据库该行数据仍为 flasebinlog先提交,crash,binlog有记录为:某行数据update成true,redolog没有写,主数据库仍为flase,使用binlog备份数据库,从数据库该行数据为true解决先后提交问题的方法:redolog先设置为预提交,最后redolog与binlog一起提交redolog :主要作为于更新主数据库,并防止主数据库的crashbinlog :主要作用于备份从库,或者恢复主数据库简单说,redo log 和 binlog 都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。

若有收获,就点个赞吧
0 人点赞
