1、分析下面的程序
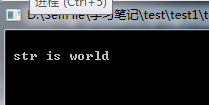
#pragma warning(disable : 4996)#include <iostream>#include <string.h>void GetMemory(char **p, int num){*p = (char *)malloc(num);}int main(){char *str = NULL;GetMemory(&str, 100);strcpy(str, "hello");free(str);if (str != NULL){strcpy(str, "world");}printf("\n str is %s", str);getchar();}
解析:
free 只是释放的 str 指向的内存空间,它本身的值还是存在的.所以 free 之后,有一个好的习惯就是将 str=NULL.此时 str 指向空间的内存已被回收,如果输出语句之前还存在分配空间的操作的话,这段存储空间是可能被重新分配给其他变量的,尽管这段程序确实是存在大大的问题(上面各位已经说得很清楚了),但是通常会打印出world 来。这是因为,进程中的内存管理一般不是由操作系统完成的,而是由库函数自己完成的。当你 malloc 一块内存的时候,管理库向操作系统申请一块空间(可能会比你申请的大一些),然后在这块空间中记录一些管理信息(一般是在你申请的内存前面一点),并将可用内存的地址返回。但是释放内存的时候,管理库通常都不会将内存还给操作系统,因此你是可以继续访问这块地址的。
2.解释下面的输出结果:
#include <stdio.h>
#include <string.h>
void main()
{
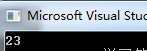
char aa[10];
printf("%d", strlen(aa));
}
解析:
由于strlen(char)是检查字符串实际的长度,检测的标准是’\0’,当strlen(char ) 碰到’\0’就返回’\0’以前的字符数;如果你只定义没有给它赋初值,这个结果是不定的,它会从aa首地址一直找下去,直到遇到’\0’停止。
3.**long a=0×801010;a+5=?**
答:0×801010用二进制表示为:“1000 0000 0001 0000 0001 0000”,十进制的值为8392720,
再加上5就是8392725
4.**给定结构 struct A,问 sizeof(A) = ?**
struct A
{
char t::4;
char k:4;
unsigned short i:8;
unsigned long m;
}
解析:
struct A
{
char t:4; 4位
char k:4; 4位
unsigned short i:8; 8位
unsigned long m; // 偏移2字节保证4字节对齐
}; // 共8字节
不考虑边界:
char t:4; char类型在内存中占用1个字节,但是它在内存中只占用了4位
char k:4; char类型在内存中占用1个字节,但是它在内存中只占用了4位
所以两个char型只占用了1个字节,
unsigned short i:8; short类型占用2个字节,在结构体中只用了8位,也就是实际在内容空间中使用了1个字节,但是需要1个字节的填充字节
unsigned long m; long类型占用4个字节
最后结果是:sizeof(A)=1+1+1+4=7
考虑边界:结果是8
**
32位机下,
short是2字节,共16bit,最大就不能超过16.
int是4字节,共32bit,最大就不能超过32.
long是4字节,共32bit,最大就不能超过32.
5.**给出下面程序的答案**
#pragma warning(disable : 4996)
#include <iostream>
#include <string.h>
using namespace std;
typedef struct AA
{
int b1 : 5;
int b2 : 2;
}AA;
void main()
{
AA aa;
char cc[100];
strcpy(cc, "0123456789abcdefghijklmnopqrstuvwxyz");
memcpy(&aa, cc, sizeof(AA));
cout << aa.b1 << endl;
cout << aa.b2 << endl;
}
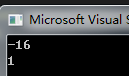
解析:首先 sizeof(AA)的大小为4,b1和 b2分别占5bit 和2bit.经过 strcpy 和 memcpy 后,aa 的4个字节所存放的值是:0,1,2,3的 ASC 码,即00110000,00110001,00110010,00110011所以,最后一步:显示的是这4个字节的前5位,和之后的2位分别为:10000,和01。因为 int 是有正负之分 所以:答案是-16和1。
6.求函数返回值,输入x = 9999;
#include <iostream>
#include <memory.h>
using namespace std;
int fun(int x) {
int countx = 0;
while (x)
{
countx++;
x = x & (x - 1);
}
return countx;
}
int main(void)
{
int a = 9999;
cout << fun(a) << endl;
return 0;
}
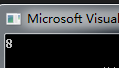
解析:知道了这是统计9999的二进制数值中有多少个1的函数,且有
9999=9×1024+512+256+159×1024中含有1的个数为2;
512中含有1的个数为1;
256中含有1的个数为1;
15中含有1的个数为4;
故共有1的个数为8,结果为8。
1000 - 1 = 0111,正好是原数取反。这就是原理。用这种方法来求1的个数是很效率很高的。不必去一个一个地移位。循环次数最少。
7.分析
#include <iostream>
#include <memory.h>
using namespace std;
struct bit
{
int a : 3;
int b : 2;
int c : 3;
};
int main()
{
bit s;
char *c = (char*)&s;
cout << sizeof(bit) << endl;
*c = 0x99;
cout << s.a << s.b << endl << s.c << endl;
int a = -1;
printf("%x", a);
return 0;
}
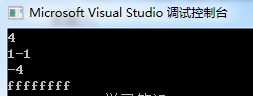
解析:因为0x99在内存中表示为 100 11 001 , a = 001, b = 11, c = 100
当 c 为有符号数时, c = 100, 最高1为表示 c 为负数,负数在计算机用补码表示,所以 c = -4;同理 b = -1;
当 c 为无符号数时, c = 100,即 c = 4,同理 b = 3;
8.下面这个程序执行后会有什么错误或者效果
#define MAX 255
int main()
{
unsigned char A[MAX],i;//i 被定义为 unsigned char
for (i=0;i<=MAX;i++)
A[i]=i;
}
解析:死循环加数组越界访问(C/C++不进行数组越界检查)MAX=255数组 A 的下标范围为:0..MAX-1,这是其一..
其二.当 i 循环到255时,循环内执行:A[255]=255;这句本身没有问题;但是返回 for (i=0;i<=MAX;i++)语句时,由于 unsigned char 的取值范围在(0..255),i++以后 i 又为0了。无限循环下去。
9.**写出 sizeof(struct name1)=,sizeof(struct name2)=的结果**
#include <iostream>
#include <memory.h>
using namespace std;
struct name1 {
char str;
short x;
int num;
};
struct name2 {
char str;
int num;
short x;
};
int main()
{
cout << sizeof(name1) << endl << sizeof(name2) << endl;
return 0;
}
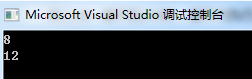
解析:在第二个结构中,为保证 num 按四个字节对齐,char 后必须留出3字节的空间;同时为保证
整个结构的自然对齐(这里是4字节对齐),在 x 后还要补齐2个字节,这样就是12字节。
10.
#include <iostream>
using namespace std;
struct s1
{
int i : 8;
int j : 4;
int a : 3;
double b;
};
struct s2
{
int i : 8;
int j : 4;
double b;
int a : 3;
};
int main()
{
printf("sizeof(s1)= %d\n", sizeof(s1));
printf("sizeof(s2)= %d\n", sizeof(s2));
return 0;
}
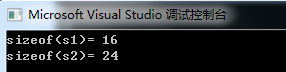
解析:第一个 struct s1 理论上是这样的,首先是 i 在相对0的位置,占8位一个字节,然后 j 就在相对一个字节的位置,由于一个位置的字节数是4位的倍数,因此不用对齐,就放在那里了,然后是 a,要在3位的倍数关系的位置上,因此要移一位,在15位的位置上放下,目前总共是18位,折算过来是2字节2位的样子,由于 double 是8字节的,因此要在相对0要是8个字节的位置上放下,因此从18位开始到8个字节之间的位置被忽略,直接放在8字节的位置了,因此,总共是16字节。
第二个最后会对照是不是结构体内最大数据的倍数,不是的话,会补成是最大数据的倍数
11.在对齐为4的情况下
struct BBB
{
long num;
char *name;
short int data;
char ha;
short ba[5];
}*p;
p=0x1000000;
p+0x200=____;
(Ulong)p+0x200=____;
(char*)p+0x200=____;
解析:假设在32位 CPU 上,sizeof(long) = 4 bytes
sizeof(char ) = 4 bytes
sizeof(short int) = sizeof(short) = 2 bytes
sizeof(char) = 1 bytes
由于是4字节对齐,
sizeof(struct BBB) = sizeof(p) = 4 + 4 + 2 + 1 + 1/补齐/ + 25 + 2/补齐/ = 24 bytes (经 Dev-C++验证)
p=0x1000000;
p+0x200 = 0x1000000 + 0x20024;
(Ulong)p+0x200 = 0x1000000 + 0x200;
(char)p+0x200 = 0x1000000 + 0x2004;
**

若有收获,就点个赞吧
0 人点赞
