- 文档对象模型(DOM,Document Object Model)是 HTML 和 XML 文档的编程接口。
- DOM 表示由多层节点构成的文档,通过它开发者可以添加、删除和修改页面的各个部分。
- DOM 现在是真正跨平台、语言无关的表示和操作网页的方式。
- 与浏览器中的 HTML 网页相关,并且在 JavaScript 中提供了 DOM API。
注意 IE8 及更低版本中的 DOM 是通过 COM 对象实现的。这意味着这些版本的 IE 中,DOM 对象跟原生 JavaScript 对象具有不同的行为和功能。
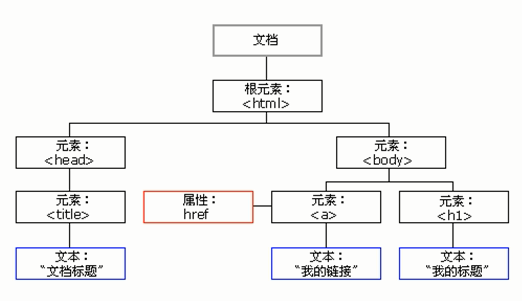
DOM树 又称为文档树模型,把文档映射成树形结构,通过节点对象对其处理,处理的结果可以加入到当前的页面。
- 文档:每个页面都i是一个文档,DOM中使用
document表示 - 节点:网页中的所有内容,在文档树中都是节点(标签、属性、文本、注释等),使用
node表示 - 标签节点:网页中的所有标签,通常称为元素节点,又简称为“元素”,使用
element表示 - 根节点的唯一子节点是元素,我们称之为文档元素(documentElement)。文档元素是文档最外层的元素,所有其他元素都存在于这个元素之内。每个文档只能有一个文档元素
1. 获取元素
- 使用 DOM 最常见的情形可能就是获取某个或某组元素的引用,然后对它们执行某些操作。
- document 对象上暴露了一些方法,可以实现这些操作。
getEkementById()和getElementsByTagName()就是 document 类型提供的两个方法。
getElementByld()方法 根据ID获取
getElementByld()方法接收一个参数,即要获取元素的 ID,如果找到了则返回这个元素,如果没找到则返回 null。参数 ID 必须跟元素在页面中的 ID 属性值完全匹配,包括大小写。
<div id = "time">2019-9-9</div><script>//因为我们文档页面从上往下加载,所以先得有标签 所以我们script写到标签的下面var timer = document.getElementByld('time');console.log(timer);console.log(typeof timer);//console.dir 打印我们返回的元素对象 更好的查看里面的属性和方法console.dir(timer);</script>
如果页面中存在多个具有相同 ID 的元素,则 getElementByld()返回在文档中出现的第一个元素。
getElementsByTagName() 根据标签名获取
getElementsByTagName()是另一个常用来获取元素引用的方法。这个方法接收一个参数,即要获取元素的标签名,返回包含零个或多个元素的元素对象集合(伪数组,数组元素是元素对象)
document.getElementsByTagName('标签名')element.getElementsByTagName('标签名')
例子:
<body><ul><li>知否知否,应是等你好久11</li><li>知否知否,应是等你好久22</li><li>知否知否,应是等你好久33</li><li>知否知否,应是等你好久44</li><li>知否知否,应是等你好久55</li></ul><ul id="nav"><li>生僻字</li><li>生僻字</li><li>生僻字</li><li>生僻字</li><li>生僻字</li></ul><script>// 1.返回的是 获取过来元素对象的集合 以伪数组的形式存储的var lis = document.getElementsByTagName('li');console.log(lis);console.log(lis[0]);// 2. 我们想要依次打印里面的元素对象我们可以采取遍历的方式for (var i = 0; i < lis.length; i++) {console.log(lis[i]);}// 3. element.getElementsByTagName() 可以得到这个元素里面的某些标签var nav = document.getElementById('nav'); // 这个获得nav 元素var navLis = nav.getElementsByTagName('li');console.log(navLis);</script></body>
要取得文档中的所有元素,可以给 getElementsByTagName()传入。在 JavaScript 和 CSS 中,一般被认为是匹配一切的字符。
let allElements = document.getElementsByTagName("*");
这行代码可以返回包含页面中所有元素的 HTMLCollection 对象,顺序就是它们在页面中出现的
顺序。因此第一项是元素,第二项是元素,以此类推。
注意
- 因为得到的是个对象集合,所以要操作元素是需要进行遍历
- 元素对象为动态(删除或增加时对应获取也会改变)
- 对于 document.getElementsByTagName()方法,虽然规范要求区分标签的大小写,但为了最大限度兼容原有 HTML 页面,实际上是不区分大小写的。
获取特殊元素

H5 新增元素获取方式


getElementsByClassName()
getElementsByClassName()方法接收一个参数,即包含一个或多个类名的字符串,返回类名中包含相应类的元素的 NodeList。如果提供了多个类名,则顺序无关紧要。
// 取得所有类名中包含"username"和"current"元素// 这两个类名的顺序无关紧要let allCurrentUsernames = document.getElementsByClassName("username current");// 取得 ID 为"myDiv"的元素子树中所有包含"selected"类的元素let selected = document.getElementById("myDiv").getElementsByClassName("selected");
- 这个方法只会返回以调用它的对象为根元素的子树中所有匹配的元素。在 document 上调用
getElementsByClassName()返回文档中所有匹配的元素,而在特定元素上调用getElementsByClassName()则返回该元素后代中匹配的元素。 - 如果要给包含特定类(而不是特定 ID 或标签)的元素添加事件处理程序,使用这个方法会很方便。
- 不过要记住,因为返回值是 NodeList,所以使用这个方法会遇到跟使用
getElementsByTagName()和其他返回 NodeList 对象的 DOM 方法同样的问题。
querySelector()
querySelector()方法接收 CSS 选择符参数,返回匹配该模式的第一个后代元素,如果没有匹配项则返回 null。
// 取得<body>元素let body = document.querySelector("body");// 取得 ID 为"myDiv"的元素let myDiv = document.querySelector("#myDiv");// 取得类名为"selected"的第一个元素let selected = document.querySelector(".selected");// 取得类名为"button"的图片let img = document.body.querySelector("img.button");
- 在 Document 上使用
querySelector()方法时,会从文档元素开始搜索; - 在 Element 上使用
querySelector()方法时,则只会从当前元素的后代中查询。 - 用于查询模式的 CSS 选择符可繁可简,依需求而定。
- 如果选择符有语法错误或碰到不支持的选择符,则
querySelector()方法会抛出错误
querySelectorAll()
querySelectorAll()方法跟querySelector()一样,也接收一个用于查询的参数,但它会返回所有匹配的节点,而不止一个。- 这个方法返回的是一个 NodeList 的静态实例(不会像getElementsByClassName()一样返回动态伪数组)。
- 再强调一次,
querySelectorAll()返回的 NodeList 实例一个属性和方法都不缺,但它是一个静态的“快照”,而非“实时”的查询。 - 这样的底层实现避免了使用 NodeList 对象可能造成的性能问题。
- 以有效 CSS 选择符调用
querySelectorAll()都会返回 NodeList,无论匹配多少个元素都可以。 - 如果没有匹配项,则返回空的 NodeList 实例。
- 与
querySelector()一样,querySelectorAll()也可以在 Document、DocumentFragment 和Element 类型上使用。// 取得 ID 为"myDiv"的<div>元素中的所有<em>元素let ems = document.getElementById("myDiv").querySelectorAll("em");// 取得所有类名中包含"selected"的元素let selecteds = document.querySelectorAll(".selected");// 取得所有是<p>元素子元素的<strong>元素let strongs = document.querySelectorAll("p strong");

若有收获,就点个赞吧
0 人点赞
