RCNN系列
RCNN
做法:首先使用selectivesearch去生成proposals,然后使用CNN去提起特征,在使用SVM进行分类
缺点:proposal image的非比例裁减,2000 region proposal feature的重复计算,不能端到端训练
SPP-Net
改进:全连接需要feature的维度保持一致,设计SPP(空间金字塔池化),允许网络输入尺寸不一致的特征图
Fast-Rcnn
faster-Rcnn:
faster-cnn是之前的总结版本,主要的修改是增加了RPN代替了原来的selective search
RPN正负样本匹配的策略:(RPN大概也是出来2000个box),正样本0.7负样本0.3中间的全部忽略掉
YOLO系列
YOLO
-
YOLO9000(YOLOv2)
BatchNormalization:2% up
- high resolution classsifier (224 -> 256):
- AlexNet使用256size的feature输入进行分类
- Anchor bbox: 不在直接回归localization,而是基于anchorbox去回归box中心点在cell里面的位移,直接回归位移会导致不稳定性,比较难收敛
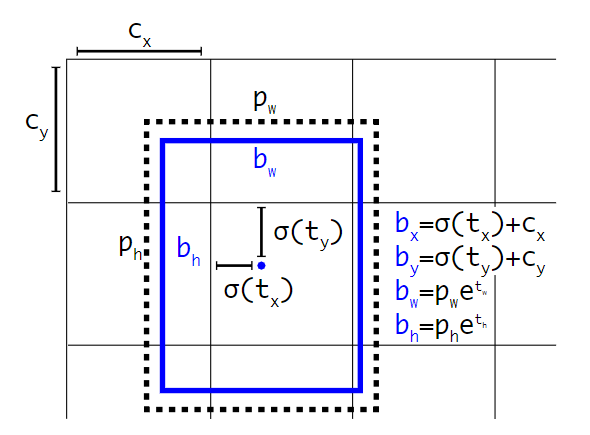
与其预测位移,选择预测和grid cell相关的坐标(tx ty tw th to)
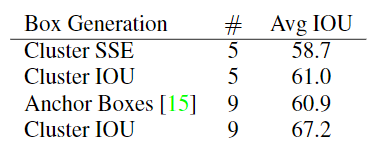
- Dimension Clusters(IoU clsuter): 在voc和coco上面先验的聚类得到anchor的大小
- Fine-grained feature更加细化的特征:13x13 -> 26x26
- backbone: DARKNET19
- Hierarchical classification垂直的分类
-
YOLOV3
预测objectness:
- classfication:使用逻辑回归而不是使用softmax,实际在训练中使用的二值交叉熵,使用softmax就是强迫每个box只有一种类别,在yolov3中,分类概率和目标物体得分相乘作为最后的置信度,这显然是没有考虑定位的准确度
- Like FPN Predictions Anchor scale: 3-box —> 9box
-
YOLOV4
一些有意思的表达:
样本挖掘(负样本挖掘和难样本挖掘)不适用与一阶段检测器,因为一阶段检测器基本都是密集预测的,所以focalloss适用于解决一阶段检测的类别不平衡的问题
为什么适用iouloss:以前都是开MSE来回归xywh这些值,但是直接估计每个点的坐标,就是把这个坐标点当成独立的变量,实际上没有考虑object本身的完整性
时髦的模块组件

SPP: 何凯明在sppnet里面提出SPM用于提取统一大小的feature map,(bag-of -word)将特征转化成多个16256d,4256d,256d的向量,SPP使用最大池代替了bag-of-word
- ASPP: 主要把SPP的conv+maxpolling换成dilated_conv
- RFB: 也是将dilated_conv的膨胀核进行修正
- SE_module: SE attention,channel-wise attention and point-wise attention, Squeeze-and Excitation Module
- SAE:
-
改进
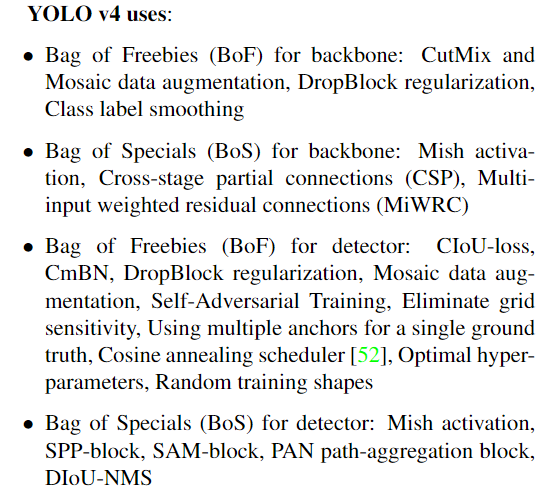
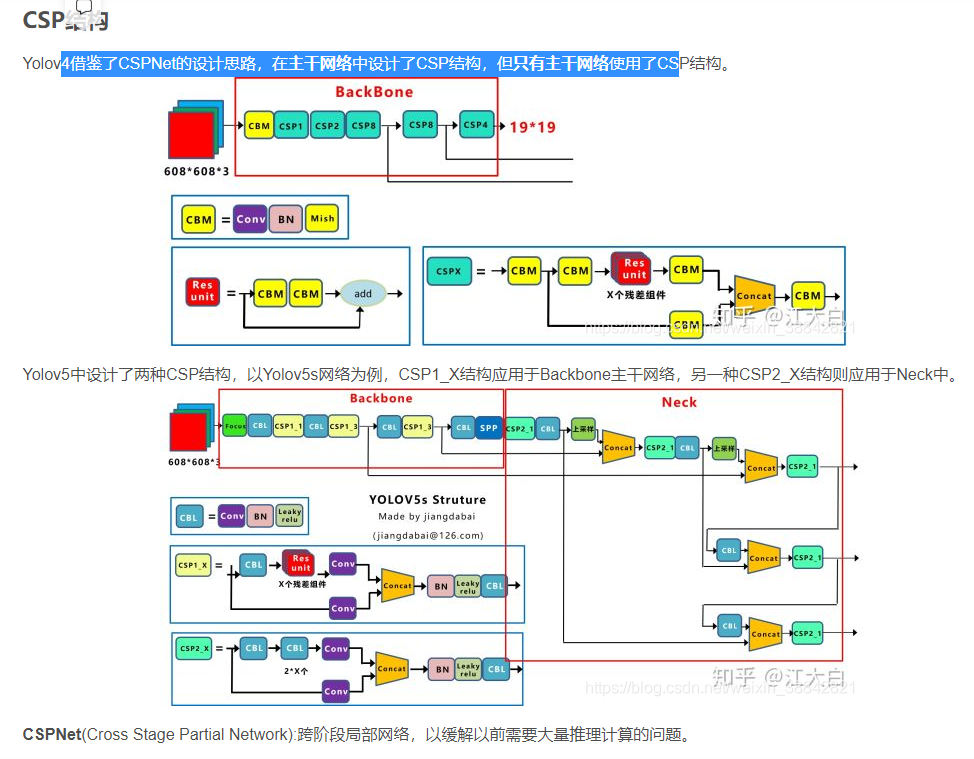
Backbone: CSPDarknet53(SPPModule增加感受野),PANet代替FPN(yolov3), Mish, Dropblock, SPP
- 输入:mosaic
- 输出: DIoU_nms
YOLOv3-v4的正负样本匹配策略
YOLO3、4: 保证每个gt bbox一定有一个唯一的anchor进行对应,匹配规则就是IOU最大,IoU最大的就是在正样本,剩余的样本中去除IoU大于0.7的高置信度的box作为负样本,所以其实这里面的正负样本是非常不均衡的需要额外增加一个objectness的自信度的估计
YOLOV5: 基于gt和anchor的宽高的比值来计算匹配的,宽高比大于某一个阈值就是正样本,小于就是负样本,没有忽略其他的样本
YOLOv5
改进
backbonbe:
- Focus
- CSP(backbone+head)
- 自适应锚框计算
- CIoU loss
- 正负样本的计算,宽高比满足要求就是正样本,否则就是负样本
Swish就是sigmoid和relu的一个结合(yolov5)Mish就是sigmoid的姐妹(tanh)和relu的一个结合(yolov4)
YOLOX
正负样本匹配系列
Retinanet
FCOS
centerness
1、pipeline: 如果location[x,y]落在gt里面就是正样本,否则就是负样本,预测ltrb来基于当前的(x,y)回归box,这个正负样本的分配策略导致了可以学习model可以更好的回归box,想比较与anchor-base的方法来说有了更多的正样本。
2、引入centerness,因为产生了很多远离gt的预测框,一种可以替代的方法就是使用gt的中心区域的样本作为正样本
centerness: centerness就是anchor和其负责预测的gt的中点点的lrtb的归一化距离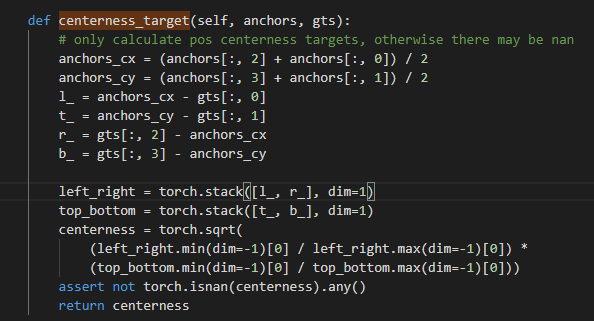
Atts
IoU分布来区分正负样本
正负样本的选择:
1、根据与gt中心点的距离确定anchors
2、计算anchors和gt的均值mg和方差vg作为阈值来划分正负样本
单阶段检测器和两阶段检测去的对比
- 双阶段精度高但速度慢,单精度速度快但精度稍逊:
二阶段的检测器使用RPN先提取bbox,然后再在refine,rpn使正负样本更加均衡
单阶段的检测器就是既要做检测还要做回归,精度差一点,但是加上Focalloss之类的方法现在精度也基本上差不多
Anchor-based和anchor-free检测器之间的对比
Anchor-base:精度高,速度慢,需要超差(anchor的先验,在数据集有偏的情况下,kmeas的不一定获取实际分布的box)
Anchor-free:精度低,速度快,不需要超差;语义模糊性(中心点重叠)-> FPN
https://www.zhihu.com/question/364639597/answer/1131327731

若有收获,就点个赞吧
0 人点赞
