L1正则化和L2正则化的区别:
1、添加正则化相当于参数的解空间添加了约束,限制了模型的复杂度
2、L1正则化的形式是添加参数的绝对值之和作为结构风险项,L2正则化的形式添加参数的平方和作为结构风险项
3、L1正则化鼓励产生稀疏的权重,即使得一部分权重为0,用于特征选择;L2鼓励产生小而分散的权重,鼓励让模型做决策的时候考虑更多的特征,而不是仅仅依赖强依赖某几个特征,可以增强模型的泛化能力,防止过拟合。
4、正则化参数 λ越大,约束越严格,太大容易产生欠拟合。正则化参数 λ越小,约束宽松,太小起不到约束作用,容易产生过拟合。
如果不是为了进行特征选择,一般使用L2正则化模型效果更好
非极大值抑制
对于Bounding Box的列表B及其对应的置信度S,采用下面的计算方式.选择具有最大score的检测框M,将其从B集合中移除并加入到最终的检测结果D中.通常将B中剩余检测框中与M的IoU大于阈值Nt的框从B中移除.重复这个过程,直到B为空
交并比:IOU
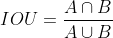
GIOU = IOU - 外接矩形空隙面积/并集 —> 两个bbox虽然远离,但是不知道远离的尺度大小,用这个可以衡量IOU远离的尺度大小
DIOU=IOU-(中心点距离/并集外接矩形对角线距离)² —> 作为loss收敛得更快,可以进一步提点
CIOU将长宽比作为一种衡量因素也考虑进来了
计算IOU的代码的写法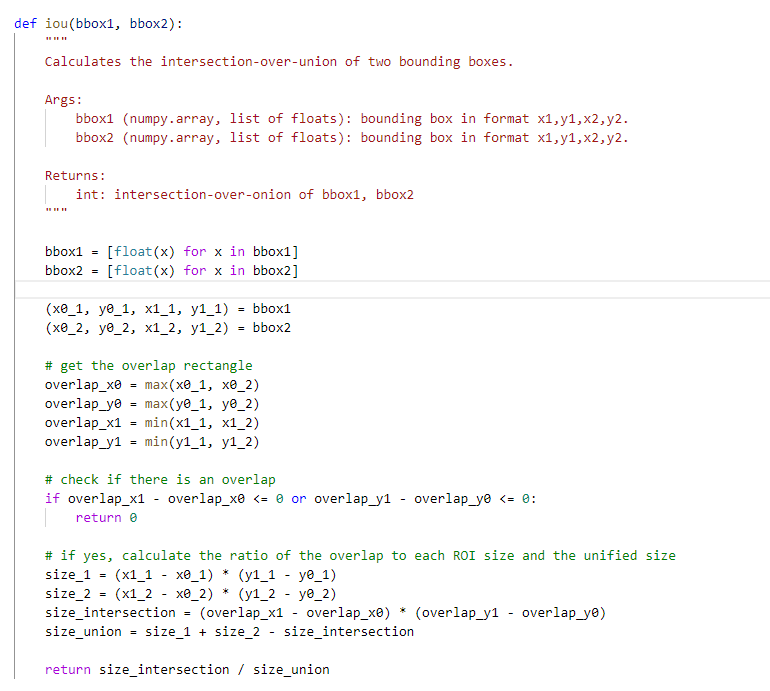
softmax与sigmoid的区别
softmax与sigmoid这两者之间区别其实还不小,还是先看两者结构上的区别: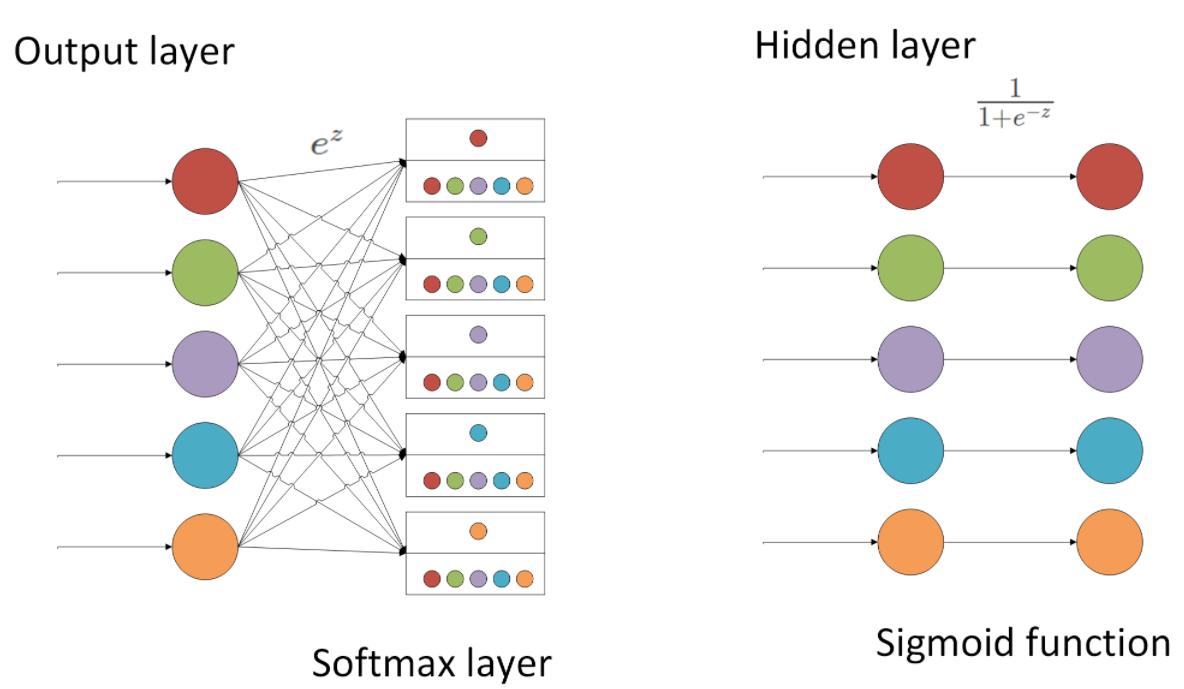
但是当输出层为一个神经元时,此时会使用sigmoid代替softmax,因为此时还按照softmax公式的话计算值为1。
softmax一般用于多分类的结果,一般和one-hot的真实标签值配合使用,大多数用于网络的最后一层;而sigmoid是原本一种隐层之间的激活函数,但是因为效果比其他激活函数差,目前一般也只会出现在二分类的输出层中,与0 1真实标签配合使用。
Smooth L1 loss


若有收获,就点个赞吧
0 人点赞
