代码如下:在Anaconda上运行无问题
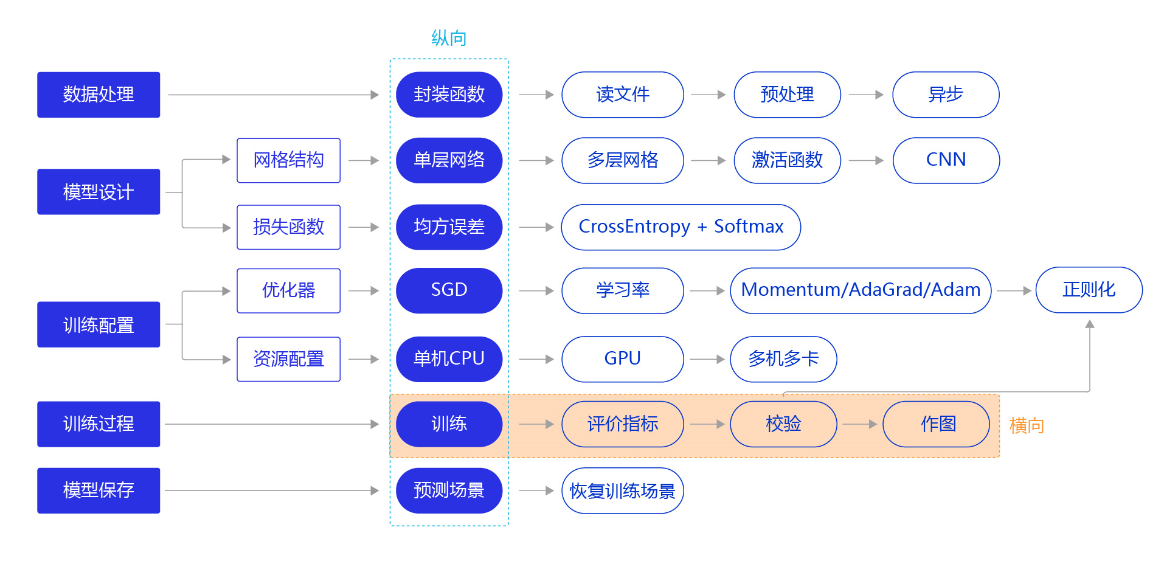
# =============================================================================# 手写数字识别# 数据集:MINIT# 参考资料:百度AI STUDIO和飞桨# =============================================================================####重构模型:卷积神经网络#########重构损失函数########优化算法########计算模型的分类准确率########加入正则化项,避免模型过拟合########可视化分析#####import randomimport paddleimport paddle.fluid as fluidfrom paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linearimport numpy as npimport matplotlib.pyplot as pltfrom PIL import Image# 安装visualdl#!pip install --upgrade --pre visualdl#from visualdl import LogWriterimport gzipimport jsonimport os#电脑如果是cpu,需要加上下面在条程序,否则spyder会卡住或者崩溃报错#参考:https://blog.csdn.net/qq_44666320/article/details/106349356?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522159454929319724843302313%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=159454929319724843302313&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v3~pc_rank_v3-2-106349356.pc_ecpm_v3_pc_rank_v3&utm_term=OMP%3A+Error+%2315%3A+Initializing+los.environ['KMP_DUPLICATE_LIB_OK']='True'##数据处理##def load_data(mode='train'):datafile = './work/mnist.json.gz'print('loading mnist dataset from {} ......'.format(datafile))# 加载json数据文件data = json.load(gzip.open(datafile))print('mnist dataset load done')# 数据集相关参数,图片高度IMG_ROWS, 图片宽度IMG_COLSIMG_ROWS = 28IMG_COLS = 28# 读取到的数据区分训练集,验证集,测试集#只取数据集的10%用来建模,因为本程序采用的CPU的电脑,数据集过大spyder运行太慢甚至会崩溃。train_set, val_set, eval_set = dataif mode=='train':# 获得训练数据集imgs, labels = train_set[0][:5000], train_set[1][:5000]elif mode=='valid':# 获得验证数据集imgs, labels = val_set[0][:1000], val_set[1][:1000]elif mode=='eval':# 获得测试数据集imgs, labels = eval_set[0][:1000], eval_set[1][:1000]else:raise Exception("mode can only be one of ['train', 'valid', 'eval']")print("训练数据集数量: ", len(imgs))# 校验数据imgs_length = len(imgs)assert len(imgs) == len(labels), \"length of train_imgs({}) should be the same as train_labels({})".format(len(imgs), len(label))# 获得数据集长度imgs_length = len(imgs)# 定义数据集每个数据的序号,根据序号读取数据index_list = list(range(imgs_length))# 读入数据时用到的批次大小BATCHSIZE = 100# 定义数据生成器def data_generator():if mode == 'train':# 训练模式下打乱数据random.shuffle(index_list)imgs_list = []labels_list = []for i in index_list:# 将数据处理成希望的格式,比如类型为float32,shape为[1, 28, 28]img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype('float32')label = np.reshape(labels[i], [1]).astype('int64') #在数据处理部分,需要修改标签变量Label的格式,变成int64imgs_list.append(img)labels_list.append(label)if len(imgs_list) == BATCHSIZE:# 获得一个batchsize的数据,并返回yield np.array(imgs_list), np.array(labels_list)# 清空数据读取列表imgs_list = []labels_list = []# 如果剩余数据的数目小于BATCHSIZE,# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batchif len(imgs_list) > 0:yield np.array(imgs_list), np.array(labels_list)return data_generator##模型搭建###使用卷积神经网络# 多层卷积神经网络实现class MNIST(fluid.dygraph.Layer):def __init__(self):super(MNIST, self).__init__()# 定义一个卷积层,使用relu激活函数self.conv1 = Conv2D(num_channels=1, num_filters=20, filter_size=5, stride=1, padding=2, act='relu')# 定义一个池化层,池化核为2,步长为2,使用最大池化方式self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')# 定义一个卷积层,使用relu激活函数self.conv2 = Conv2D(num_channels=20, num_filters=20, filter_size=5, stride=1, padding=2, act='relu')# 定义一个池化层,池化核为2,步长为2,使用最大池化方式self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')# 定义一个全连接层,输出节点数为10self.fc = Linear(input_dim=980, output_dim=10, act='softmax')# 定义网络的前向计算过程def forward(self, inputs, label):x = self.conv1(inputs)x = self.pool1(x)x = self.conv2(x)x = self.pool2(x)x = fluid.layers.reshape(x, [x.shape[0], 980])x = self.fc(x)if label is not None:acc = fluid.layers.accuracy(input=x, label=label)return x, accelse:return x##训练模型###形成了四种比较成熟的优化算法:SGD、Momentum、AdaGrad和Adam#仅优化算法的设置有所差别#加入正则化项,避免模型过拟合#可视化分析:使用Matplotlib库绘制损失随训练下降的曲线图# =============================================================================# #在使用GPU机器时,可以将use_gpu变量设置成True# use_gpu = True# place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()# with fluid.dygraph.guard(place):# =============================================================================#调用加载数据的函数train_loader = load_data('train')with fluid.dygraph.guard():model = MNIST()model.train()#四种优化算法的设置方案,可以逐一尝试效果#optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01, parameter_list=model.parameters())#optimizer = fluid.optimizer.MomentumOptimizer(learning_rate=0.01, momentum=0.9, parameter_list=model.parameters())#optimizer = fluid.optimizer.AdagradOptimizer(learning_rate=0.01, parameter_list=model.parameters())optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.001, parameter_list=model.parameters())#各种优化算法均可以加入正则化项,避免过拟合,参数regularization_coeff调节正则化项的权重,在该程序中发现加入正则项之后,#模型的正确率acc是降低了,在后面的模型校验中,acc从0.97降到了0.91左右,可能需要经过进一步的调参才能达到一个较好的值#optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01, regularization=fluid.regularizer.L2Decay(regularization_coeff=0.1),parameter_list=model.parameters()))#optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.01, regularization=fluid.regularizer.L2Decay(regularization_coeff=0.1),parameter_list=model.parameters())EPOCH_NUM =10iter=0iters=[]losses=[]acces =[]for epoch_id in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):#准备数据,变得更加简洁image_data, label_data = dataimage = fluid.dygraph.to_variable(image_data)label = fluid.dygraph.to_variable(label_data)#前向计算的过程,同时拿到模型输出值和分类准确率predict, acc = model(image, label)#计算损失,取一个批次样本损失的平均值loss = fluid.layers.cross_entropy(predict, label)avg_loss = fluid.layers.mean(loss)#每训练了5批次的数据,打印下当前Loss的情况if batch_id % 10 == 0:print("epoch: {}, batch: {}, loss is: {}, acc is {}".format(epoch_id, batch_id, avg_loss.numpy(), acc.numpy()))iters.append(iter)losses.append(avg_loss.numpy()) #生成损失函数的值acces.append(float(acc.numpy())) #生成正确率的值iter = iter + 10#后向传播,更新参数的过程avg_loss.backward()optimizer.minimize(avg_loss)model.clear_gradients()#保存模型参数fluid.save_dygraph(model.state_dict(), 'mnist')# =============================================================================# #画出训练过程中Loss的变化曲线# plt.figure()# plt.title("train loss", fontsize=24)# plt.xlabel("iter", fontsize=14)# plt.ylabel("loss", fontsize=14)# plt.plot(iters, losses,color='red',label='train loss')# plt.plot(iters, acces,color='green',label='acc')# plt.grid()# plt.legend() #显示label# plt.show()## =============================================================================##模型校验### =============================================================================# # 加入校验或测试,更好评价模型效果## 在训练过程中,我们会发现模型在训练样本集上的损失在不断减小。但这是否代表模型在未来的应用场景上依然有效?为了验证模型的有效性,通常将样本集合分成三份,训练集、校验集和测试集。## - **训练集** :用于训练模型的参数,即训练过程中主要完成的工作。# - **校验集** :用于对模型超参数的选择,比如网络结构的调整、正则化项权重的选择等。# - **测试集** :用于模拟模型在应用后的真实效果。因为测试集没有参与任何模型优化或参数训练的工作,所以它对模型来说是完全未知的样本。在不以校验数据优化网络结构或模型超参数时,校验数据和测试数据的效果是类似的,均更真实的反映模型效果。## 如下程序读取上一步训练保存的模型参数,读取校验数据集,并测试模型在校验数据集上的效果。with fluid.dygraph.guard():print('start evaluation .......')#加载模型参数model = MNIST()model_state_dict, _ = fluid.load_dygraph('mnist')model.load_dict(model_state_dict)model.eval()eval_loader = load_data('eval')EPOCH_NUM =5 #设置成5是因为保证eval_iters和训练集里面的iters保持一致eval_iter =0eval_iters =[]eval_acc = []eval_losses = []for epoch_id in range(EPOCH_NUM):for batch_id, data in enumerate(eval_loader()):#准备数据,变得更加简洁x_data, y_data = dataimg = fluid.dygraph.to_variable(x_data)label = fluid.dygraph.to_variable(y_data)#前向计算的过程,同时拿到模型输出值和分类准确率prediction, acc = model(img, label)#计算损失,取一个批次样本损失的平均值loss = fluid.layers.cross_entropy(input=prediction, label=label)avg_loss = fluid.layers.mean(loss)print("epoch: {}, batch: {}, eval loss is: {}, eval acc is {}".format(epoch_id, batch_id, avg_loss.numpy(), acc.numpy()))eval_iters.append(eval_iter)eval_acc.append(float(acc.numpy()))eval_losses.append(float(avg_loss.numpy()))eval_iter = eval_iter + 10 #设置成+10是因为保证eval_iters和训练集里面的iters保持一致#计算多个batch的平均损失和准确率acc_eval_mean = np.array(eval_acc).mean()avg_loss_eval_mean = np.array(eval_losses).mean()print('eval_loss={}, eval_acc={}'.format(avg_loss_eval_mean, acc_eval_mean))#画出训练集和测试集上的loss和accplt.figure()plt.title("train loss", fontsize=24)plt.xlabel("iter", fontsize=14)plt.ylabel("loss", fontsize=14)plt.plot(iters, losses,color='red',label='train loss')plt.plot(iters, acces,color='green',label='train acc')plt.plot(iters, eval_losses,color='black',label='eval loss')plt.plot(iters, eval_acc,color='blue',label='eval acc')plt.grid()plt.legend() #显示labelplt.show()##模型测试-实例### 读取一张本地的样例图片,转变成模型输入的格式def load_image(img_path):# 从img_path中读取图像,并转为灰度图im = Image.open(img_path).convert('L')im.show()im = im.resize((28, 28), Image.ANTIALIAS)im = np.array(im).reshape(1, 1, 28, 28).astype(np.float32)# 图像归一化im = 1.0 - im / 255.return im# 定义预测过程with fluid.dygraph.guard():model = MNIST()params_file_path = 'mnist'#img_path = './work/example_6.jpg'img_path = './work/3.jpg'# 加载模型参数model_dict, _ = fluid.load_dygraph("mnist")model.load_dict(model_dict)model.eval()tensor_img = load_image(img_path)tensor_img = fluid.dygraph.to_variable(tensor_img)#模型反馈10个分类标签的对应概率:顺序为0-1-2-3-4-5-6-7-8-9results= model(tensor_img,None) #需要把参数label设置为None#取概率最大的标签作为预测输出,argsort函数返回的是数组值从小到大的索引值lab = np.argsort(results.numpy())print("本次预测的数字是: ", lab[0][-1])print(lab)print(results)
输出结果:
loading mnist dataset from ./work/mnist.json.gz ……
mnist dataset load done
训练数据集数量: 5000
epoch: 0, batch: 0, loss is: [2.4915576], acc is [0.1]
epoch: 0, batch: 10, loss is: [1.5316845], acc is [0.69]
epoch: 0, batch: 20, loss is: [0.83047193], acc is [0.8]
epoch: 0, batch: 30, loss is: [0.51821786], acc is [0.85]
epoch: 0, batch: 40, loss is: [0.48973906], acc is [0.88]
epoch: 1, batch: 0, loss is: [0.38499394], acc is [0.89]
epoch: 1, batch: 10, loss is: [0.23730269], acc is [0.92]
epoch: 1, batch: 20, loss is: [0.25574294], acc is [0.94]
epoch: 1, batch: 30, loss is: [0.27882397], acc is [0.94]
epoch: 1, batch: 40, loss is: [0.1283002], acc is [0.98]
epoch: 2, batch: 0, loss is: [0.16451116], acc is [0.95]
epoch: 2, batch: 10, loss is: [0.3827349], acc is [0.88]
epoch: 2, batch: 20, loss is: [0.20935288], acc is [0.93]
epoch: 2, batch: 30, loss is: [0.23373388], acc is [0.91]
epoch: 2, batch: 40, loss is: [0.14140654], acc is [0.93]
epoch: 3, batch: 0, loss is: [0.15643257], acc is [0.95]
epoch: 3, batch: 10, loss is: [0.13176951], acc is [0.96]
epoch: 3, batch: 20, loss is: [0.04614418], acc is [0.99]
epoch: 3, batch: 30, loss is: [0.09424598], acc is [0.96]
epoch: 3, batch: 40, loss is: [0.09168195], acc is [0.97]
epoch: 4, batch: 0, loss is: [0.02923228], acc is [0.99]
epoch: 4, batch: 10, loss is: [0.13874717], acc is [0.97]
epoch: 4, batch: 20, loss is: [0.05634639], acc is [0.98]
epoch: 4, batch: 30, loss is: [0.06768931], acc is [0.99]
epoch: 4, batch: 40, loss is: [0.03969796], acc is [1.]
epoch: 5, batch: 0, loss is: [0.07368492], acc is [0.98]
epoch: 5, batch: 10, loss is: [0.11109852], acc is [0.96]
epoch: 5, batch: 20, loss is: [0.06013503], acc is [0.99]
epoch: 5, batch: 30, loss is: [0.04761858], acc is [1.]
epoch: 5, batch: 40, loss is: [0.1447768], acc is [0.95]
epoch: 6, batch: 0, loss is: [0.05016608], acc is [0.99]
epoch: 6, batch: 10, loss is: [0.05443259], acc is [0.98]
epoch: 6, batch: 20, loss is: [0.06043101], acc is [0.98]
epoch: 6, batch: 30, loss is: [0.02192996], acc is [1.]
epoch: 6, batch: 40, loss is: [0.11689008], acc is [0.97]
epoch: 7, batch: 0, loss is: [0.0725936], acc is [0.99]
epoch: 7, batch: 10, loss is: [0.11685197], acc is [0.97]
epoch: 7, batch: 20, loss is: [0.03049235], acc is [0.99]
epoch: 7, batch: 30, loss is: [0.02428434], acc is [0.99]
epoch: 7, batch: 40, loss is: [0.03178823], acc is [1.]
epoch: 8, batch: 0, loss is: [0.06074265], acc is [0.99]
epoch: 8, batch: 10, loss is: [0.0183008], acc is [1.]
epoch: 8, batch: 20, loss is: [0.03154246], acc is [1.]
epoch: 8, batch: 30, loss is: [0.05903977], acc is [0.98]
epoch: 8, batch: 40, loss is: [0.03373271], acc is [0.99]
epoch: 9, batch: 0, loss is: [0.03680596], acc is [0.99]
epoch: 9, batch: 10, loss is: [0.02522638], acc is [0.99]
epoch: 9, batch: 20, loss is: [0.0130638], acc is [1.]
epoch: 9, batch: 30, loss is: [0.02572271], acc is [0.99]
epoch: 9, batch: 40, loss is: [0.03820073], acc is [0.99]
start evaluation …….
loading mnist dataset from ./work/mnist.json.gz ……
mnist dataset load done
训练数据集数量: 1000
epoch: 0, batch: 0, eval loss is: [0.04049644], eval acc is [0.98]
epoch: 0, batch: 1, eval loss is: [0.05177031], eval acc is [0.98]
epoch: 0, batch: 2, eval loss is: [0.11455852], eval acc is [0.96]
epoch: 0, batch: 3, eval loss is: [0.11864574], eval acc is [0.96]
epoch: 0, batch: 4, eval loss is: [0.13767797], eval acc is [0.95]
epoch: 0, batch: 5, eval loss is: [0.09025951], eval acc is [0.97]
epoch: 0, batch: 6, eval loss is: [0.15296514], eval acc is [0.96]
epoch: 0, batch: 7, eval loss is: [0.06582429], eval acc is [0.97]
epoch: 0, batch: 8, eval loss is: [0.11204186], eval acc is [0.96]
epoch: 0, batch: 9, eval loss is: [0.22585735], eval acc is [0.93]
epoch: 1, batch: 0, eval loss is: [0.04049644], eval acc is [0.98]
epoch: 1, batch: 1, eval loss is: [0.05177031], eval acc is [0.98]
epoch: 1, batch: 2, eval loss is: [0.11455852], eval acc is [0.96]
epoch: 1, batch: 3, eval loss is: [0.11864574], eval acc is [0.96]
epoch: 1, batch: 4, eval loss is: [0.13767797], eval acc is [0.95]
epoch: 1, batch: 5, eval loss is: [0.09025951], eval acc is [0.97]
epoch: 1, batch: 6, eval loss is: [0.15296514], eval acc is [0.96]
epoch: 1, batch: 7, eval loss is: [0.06582429], eval acc is [0.97]
epoch: 1, batch: 8, eval loss is: [0.11204186], eval acc is [0.96]
epoch: 1, batch: 9, eval loss is: [0.22585735], eval acc is [0.93]
epoch: 2, batch: 0, eval loss is: [0.04049644], eval acc is [0.98]
epoch: 2, batch: 1, eval loss is: [0.05177031], eval acc is [0.98]
epoch: 2, batch: 2, eval loss is: [0.11455852], eval acc is [0.96]
epoch: 2, batch: 3, eval loss is: [0.11864574], eval acc is [0.96]
epoch: 2, batch: 4, eval loss is: [0.13767797], eval acc is [0.95]
epoch: 2, batch: 5, eval loss is: [0.09025951], eval acc is [0.97]
epoch: 2, batch: 6, eval loss is: [0.15296514], eval acc is [0.96]
epoch: 2, batch: 7, eval loss is: [0.06582429], eval acc is [0.97]
epoch: 2, batch: 8, eval loss is: [0.11204186], eval acc is [0.96]
epoch: 2, batch: 9, eval loss is: [0.22585735], eval acc is [0.93]
epoch: 3, batch: 0, eval loss is: [0.04049644], eval acc is [0.98]
epoch: 3, batch: 1, eval loss is: [0.05177031], eval acc is [0.98]
epoch: 3, batch: 2, eval loss is: [0.11455852], eval acc is [0.96]
epoch: 3, batch: 3, eval loss is: [0.11864574], eval acc is [0.96]
epoch: 3, batch: 4, eval loss is: [0.13767797], eval acc is [0.95]
epoch: 3, batch: 5, eval loss is: [0.09025951], eval acc is [0.97]
epoch: 3, batch: 6, eval loss is: [0.15296514], eval acc is [0.96]
epoch: 3, batch: 7, eval loss is: [0.06582429], eval acc is [0.97]
epoch: 3, batch: 8, eval loss is: [0.11204186], eval acc is [0.96]
epoch: 3, batch: 9, eval loss is: [0.22585735], eval acc is [0.93]
epoch: 4, batch: 0, eval loss is: [0.04049644], eval acc is [0.98]
epoch: 4, batch: 1, eval loss is: [0.05177031], eval acc is [0.98]
epoch: 4, batch: 2, eval loss is: [0.11455852], eval acc is [0.96]
epoch: 4, batch: 3, eval loss is: [0.11864574], eval acc is [0.96]
epoch: 4, batch: 4, eval loss is: [0.13767797], eval acc is [0.95]
epoch: 4, batch: 5, eval loss is: [0.09025951], eval acc is [0.97]
epoch: 4, batch: 6, eval loss is: [0.15296514], eval acc is [0.96]
epoch: 4, batch: 7, eval loss is: [0.06582429], eval acc is [0.97]
epoch: 4, batch: 8, eval loss is: [0.11204186], eval acc is [0.96]
epoch: 4, batch: 9, eval loss is: [0.22585735], eval acc is [0.93]
eval_loss=0.11100971214473247, eval_acc=0.9620000004768372

本次预测的数字是: 3
[[6 1 0 7 4 8 2 9 5 3]]
name tmp_13, dtype: VarType.FP32 shape: [1, 10] lod: {}
dim: 1, 10
layout: NCHW
dtype: float
data: [0.0011202 0.000324511 0.0128064 0.846113 0.00409311 0.104269 0.000196426 0.00348324 0.0120471 0.0155469]
总结:


若有收获,就点个赞吧
0 人点赞
