(本文整理自百度AIstudio:https://aistudio.baidu.com/aistudio/education/group/info/888,本文当学习笔记使用,侵删)
一、数据处理
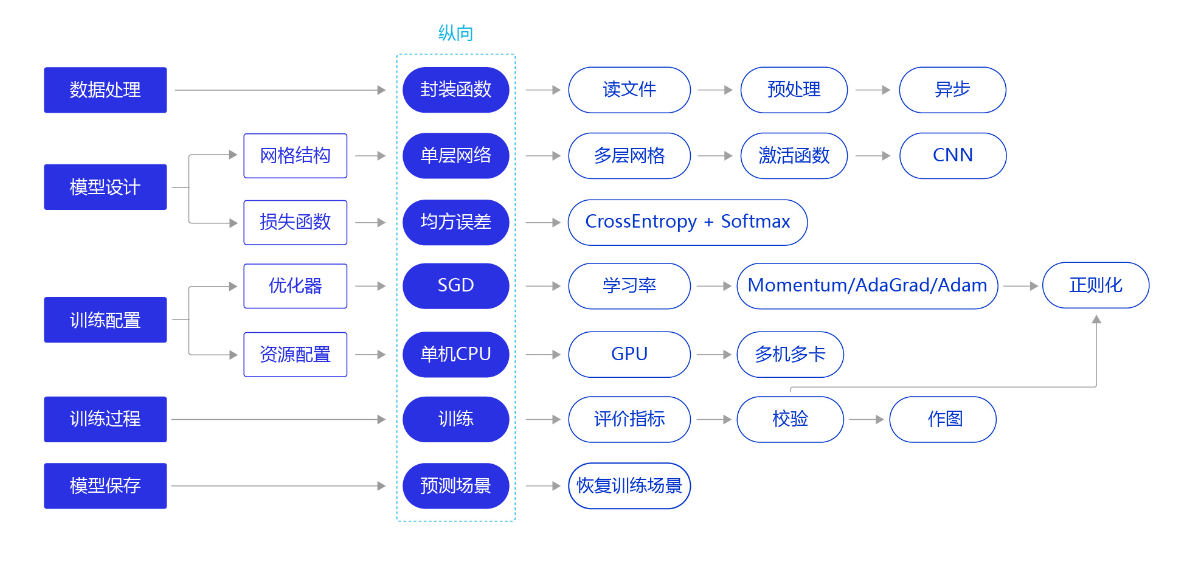
在实际应用中,保存到本地的数据存储格式多种多样,如MNIST数据集以json格式存储在本地,其数据存储结构如 图2 所示。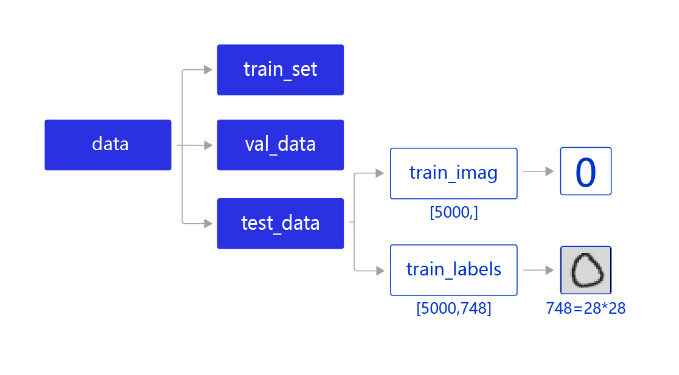
图2:MNIST数据集的存储结构
data包含三个元素的列表:train_set、val_set、 test_set。
- train_set(训练集):包含50000条手写数字图片和对应的标签,用于确定模型参数。
- val_set(验证集):包含10000条手写数字图片和对应的标签,用于调节模型超参数(如多个网络结构、正则化权重的最优选择)。
- test_set(测试集):包含10000条手写数字图片和对应的标签,用于估计应用效果(没有在模型中应用过的数据,更贴近模型在真实场景应用的效果)。
train_set包含两个元素的列表:train_images、train_labels。
- train_imgs:[5000, 784]的二维列表,包含5000张图片。每张图片用一个长度为784的向量表示,内容是28*28尺寸的像素灰度值(黑白图片)。
- train_labels:[5000, ]的列表,表示这些图片对应的分类标签,即0-9之间的一个数字。
在本地./work/目录下读取文件名称为mnist.json.gz的MINST数据,并拆分成训练集、验证集和测试集。
由于我使用的是CPU配置的电脑,为了让本程序能在Aanconda上流畅地跑起来,这里只取了数据集的10%用来建模,数据集过大会导致spyder运行太慢甚至出现卡死和崩溃的情况。
二、模型设计
1、网络结构:卷积神经网络
虽然使用经典的神经网络可以提升一定的准确率,但对于计算机视觉问题,效果最好的模型仍然是卷积神经网络。卷积神经网络针对视觉问题的特点进行了网络结构优化,更适合处理视觉问题。
卷积神经网络由多个卷积层和池化层组成,如 图3 所示。卷积层负责对输入进行扫描以生成更抽象的特征表示,池化层对这些特征表示进行过滤,保留最关键的特征信息。
图3:在处理计算机视觉任务中大放异彩的卷积神经网络
2、损失函数:交叉熵误差(常用于分类问题)

三、训练配置
1、设置学习率
在深度学习神经网络模型中,通常使用标准的随机梯度下降算法更新参数,学习率代表参数更新幅度的大小,即步长。当学习率最优时,模型的有效容量最大,最终能达到的效果最好。学习率和深度学习任务类型有关,合适的学习率往往需要大量的实验和调参经验。探索学习率最优值时需要注意如下两点:
- 学习率不是越小越好。学习率越小,损失函数的变化速度越慢,意味着我们需要花费更长的时间进行收敛,如图4 左图所示。
- 学习率不是越大越好。只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。在接近最优解时,过大的学习率会导致参数在最优解附近震荡,损失难以收敛,如 图4 右图所示。
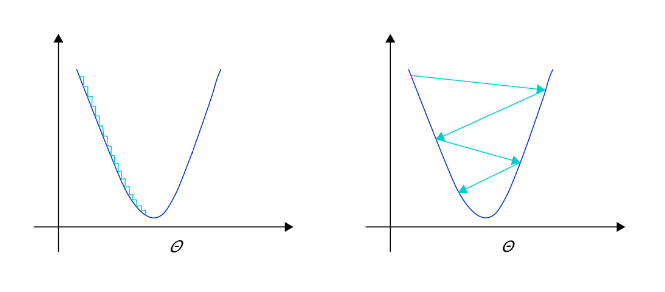
图4: 不同学习率(步长过大/过小)的示意图
在训练前,我们往往不清楚一个特定问题设置成怎样的学习率是合理的,因此在训练时可以尝试调小或调大,通过观察Loss下降的情况判断合理的学习率。
学习率的主流优化算法
学习率是优化器的一个参数,调整学习率看似是一件非常麻烦的事情,需要不断的调整步长,观察训练时间和Loss的变化。经过研究员的不断的实验,当前已经形成了四种比较成熟的优化算法:SGD、Momentum、AdaGrad和Adam,效果如 图5 所示。
图5: 不同学习率算法效果示意图
每个批次的数据含有抽样误差,导致梯度更新的方向波动较大。如果我们引入物理动量的概念,给梯度下降的过程加入一定的“惯性”累积,就可以减少更新路径上的震荡,即每次更新的梯度由“历史多次梯度的累积方向”和“当次梯度”加权相加得到。历史多次梯度的累积方向往往是从全局视角更正确的方向,这与“惯性”的物理概念很像,也是为何其起名为“Momentum”的原因。类似不同品牌和材质的篮球有一定的重量差别,街头篮球队中的投手(擅长中远距离投篮)喜欢稍重篮球的比例较高。一个很重要的原因是,重的篮球惯性大,更不容易受到手势的小幅变形或风吹的影响。
- AdaGrad: 根据不同参数距离最优解的远近,动态调整学习率。学习率逐渐下降,依据各参数变化大小调整学习率。
通过调整学习率的实验可以发现:当某个参数的现值距离最优解较远时(表现为梯度的绝对值较大),我们期望参数更新的步长大一些,以便更快收敛到最优解。当某个参数的现值距离最优解较近时(表现为梯度的绝对值较小),我们期望参数的更新步长小一些,以便更精细的逼近最优解。类似于打高尔夫球,专业运动员第一杆开球时,通常会大力打一个远球,让球尽量落在洞口附近。当第二杆面对离洞口较近的球时,他会更轻柔而细致的推杆,避免将球打飞。与此类似,参数更新的步长应该随着优化过程逐渐减少,减少的程度与当前梯度的大小有关。根据这个思想编写的优化算法称为“AdaGrad”,Ada是Adaptive的缩写,表示“适应环境而变化”的意思。
- Adam: 由于Momentum和AdaGrad两个优化思路是正交的,因此可以将两个思路结合起来,这就是当前广泛应用的算法。
说明:
每种优化算法均有更多的参数设置,详情可查阅飞桨的官方API文档。理论最合理的未必在具体案例中最有效,所以模型调参是很有必要的,最优的模型配置往往是在一定“理论”和“经验”的指导下实验出来的。
2、资源配置:GPU、多卡多机
四、训练过程
1、计算模型的分类准确率
准确率是一个直观衡量分类模型效果的指标,由于这个指标是离散的,因此不适合作为损失来优化。通常情况下,交叉熵损失越小的模型,分类的准确率也越高。基于分类准确率,我们可以公平的比较两种损失函数的优劣,例如【手写数字识别】之损失函数 章节中均方误差和交叉熵的比较。
飞桨提供了计算分类准确率的API,使用fluid.layers.accuracy可以直接计算准确率,该API的输入为预测的分类结果input和对应的标签label。
2、加入校验或测试,更好评价模型效果
在训练过程中,我们会发现模型在训练样本集上的损失在不断减小。但这是否代表模型在未来的应用场景上依然有效?为了验证模型的有效性,通常将样本集合分成三份,训练集、校验集和测试集。
- 训练集 :用于训练模型的参数,即训练过程中主要完成的工作。
- 校验集 :用于对模型超参数的选择,比如网络结构的调整、正则化项权重的选择等。
- 测试集 :用于模拟模型在应用后的真实效果。因为测试集没有参与任何模型优化或参数训练的工作,所以它对模型来说是完全未知的样本。在不以校验数据优化网络结构或模型超参数时,校验数据和测试数据的效果是类似的,均更真实的反映模型效果。
如下程序读取上一步训练保存的模型参数,读取校验数据集,并测试模型在校验数据集上的效果。
3、加入正则化项,避免模型过拟合
过拟合现象
对于样本量有限、但需要使用强大模型的复杂任务,模型很容易出现过拟合的表现,即在训练集上的损失小,在验证集或测试集上的损失较大,如 图6 所示。
图6:过拟合现象,训练误差不断降低,但测试误差先降后增
反之,如果模型在训练集和测试集上均损失较大,则称为欠拟合。过拟合表示模型过于敏感,学习到了训练数据中的一些误差,而这些误差并不是真实的泛化规律(可推广到测试集上的规律)。欠拟合表示模型还不够强大,还没有很好的拟合已知的训练样本,更别提测试样本了。因为欠拟合情况容易观察和解决,只要训练loss不够好,就不断使用更强大的模型即可,因此实际中我们更需要处理好过拟合的问题。
导致过拟合原因
造成过拟合的原因是模型过于敏感,而训练数据量太少或其中的噪音太多。
如图7 所示,理想的回归模型是一条坡度较缓的抛物线,欠拟合的模型只拟合出一条直线,显然没有捕捉到真实的规律,但过拟合的模型拟合出存在很多拐点的抛物线,显然是过于敏感,也没有正确表达真实规律。
图7:回归模型的过拟合,理想和欠拟合状态的表现
如图8 所示,理想的分类模型是一条半圆形的曲线,欠拟合用直线作为分类边界,显然没有捕捉到真实的边界,但过拟合的模型拟合出很扭曲的分类边界,虽然对所有的训练数据正确分类,但对一些较为个例的样本所做出的妥协,高概率不是真实的规律。
图8:分类模型的欠拟合,理想和过拟合状态的表现
正则化项
为了防止模型过拟合,在没有扩充样本量的可能下,只能降低模型的复杂度,可以通过限制参数的数量或可能取值(参数值尽量小)实现。
具体来说,在模型的优化目标(损失)中人为加入对参数规模的惩罚项。当参数越多或取值越大时,该惩罚项就越大。通过调整惩罚项的权重系数,可以使模型在“尽量减少训练损失”和“保持模型的泛化能力”之间取得平衡。泛化能力表示模型在没有见过的样本上依然有效。正则化项的存在,增加了模型在训练集上的损失。
飞桨支持为所有参数加上统一的正则化项,也支持为特定的参数添加正则化项。前者的实现如下代码所示,仅在优化器中设置regularization参数即可实现。使用参数regularization_coeff调节正则化项的权重,权重越大时,对模型复杂度的惩罚越高。
五、可视化分析:
使用Matplotlib库绘制损失随训练下降的曲线图
几个学习Matplotlib的网址:
1、Matplotlib简易教程:https://liam.page/2014/09/11/matplotlib-tutorial-zh-cn/
2、Matplotlib详细教程:https://www.matplotlib.org.cn/

若有收获,就点个赞吧
0 人点赞
