(绝大部分内容转自百度AIstudio:https://aistudio.baidu.com/aistudio/education/group/info/888,本文当学习笔记使用,侵删)
波士顿房价预测
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。和大家对房价的普遍认知相同,波士顿地区的房价是由诸多因素影响的。该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型,如 图1 所示。
图1:波士顿房价影响因素示意图
对于预测问题,可以根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。下面我们尝试用最简单的线性回归模型解决这个问题,并用神经网络来实现这个模型。
线性回归模型
假设房价和各影响因素之间能够用线性关系来描述:
模型的求解即是通过数据拟合出每个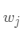 和
和 。其中,
。其中, 和
和 分别表示该线性模型的权重和偏置。一维情况下,
分别表示该线性模型的权重和偏置。一维情况下, 和
和  是直线的斜率和截距。
是直线的斜率和截距。
线性回归模型使用均方误差作为损失函数(Loss),用以衡量预测房价和真实房价的差异,公式如下: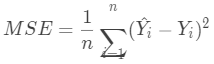
线性回归模型的神经网络结构
神经网络的标准结构中每个神经元由加权和与非线性变换构成,然后将多个神经元分层的摆放并连接形成神经网络。线性回归模型可以认为是神经网络模型的一种极简特例,是一个只有加权和、没有非线性变换的神经元(无需形成网络),如 图2 所示。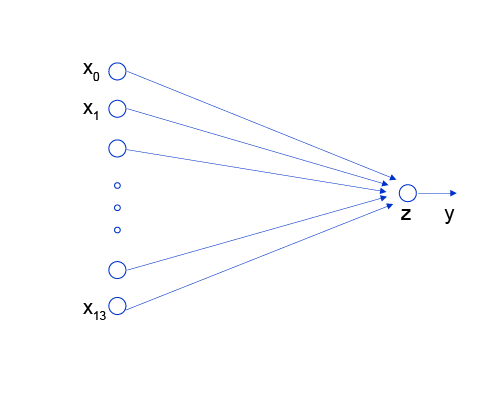
图2:线性回归模型的神经网络结构
构建波士顿房价预测任务的神经网络模型
深度学习不仅实现了模型的端到端学习,还推动了人工智能进入工业大生产阶段,产生了标准化、自动化和模块化的通用框架。不同场景的深度学习模型具备一定的通用性,五个步骤即可完成模型的构建和训练,如 图3 所示。
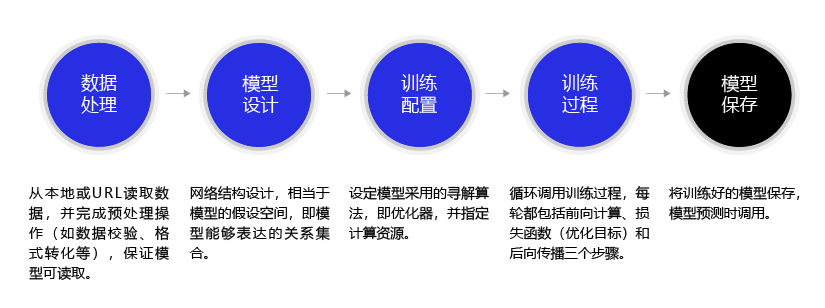
图3:构建神经网络/深度学习模型的基本步骤
正是由于深度学习的建模和训练的过程存在通用性,在构建不同的模型时,只有模型三要素不同,其它步骤基本一致,深度学习框架才有用武之地。
数据处理housing.rar
数据处理包含五个部分:数据导入、数据形状变换、数据集划分、数据归一化处理和封装load data函数。数据预处理后,才能被模型调用。将几个数据处理操作封装成load data函数。
模型设计
模型设计是深度学习模型关键要素之一,也称为网络结构设计,相当于模型的假设空间,即实现模型“前向计算”(从输入到输出)的过程。
将计算预测输出的过程以“类和对象”的方式来描述,类成员变量有参数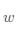 和
和 。通过写一个forward函数(代表“前向计算”)完成上述从特征和参数到输出预测值的计算过程。
。通过写一个forward函数(代表“前向计算”)完成上述从特征和参数到输出预测值的计算过程。
训练配置
模型设计完成后,需要通过训练配置寻找模型的最优值,即通过损失函数来衡量模型的好坏。训练配置也是深度学习模型关键要素之一。
通过模型计算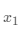 表示的影响因素所对应的房价应该是
表示的影响因素所对应的房价应该是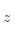 , 但实际数据告诉我们房价是
, 但实际数据告诉我们房价是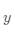 。这时我们需要有某种指标来衡量预测值
。这时我们需要有某种指标来衡量预测值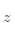 跟真实值
跟真实值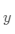 之间的差距。对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义如下:
之间的差距。对于回归问题,最常采用的衡量方法是使用均方误差作为评价模型好坏的指标,具体定义如下:
上式中的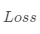 (简记为:
(简记为: 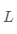 )通常也被称作损失函数,它是衡量模型好坏的指标。在回归问题中均方误差是一种比较常见的形式,分类问题中通常会采用交叉熵作为损失函数。
)通常也被称作损失函数,它是衡量模型好坏的指标。在回归问题中均方误差是一种比较常见的形式,分类问题中通常会采用交叉熵作为损失函数。
训练过程
上述计算过程描述了如何构建神经网络,通过神经网络完成预测值和损失函数的计算。接下来介绍如何求解参数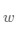 和
和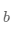 的数值,这个过程也称为模型训练过程。训练过程是深度学习模型的关键要素之一,其目标是让定义的损失函数
的数值,这个过程也称为模型训练过程。训练过程是深度学习模型的关键要素之一,其目标是让定义的损失函数 尽可能的小,也就是说找到一个参数解
尽可能的小,也就是说找到一个参数解 和
和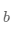 使得损失函数取得极小值。
使得损失函数取得极小值。
我们先做一个小测试:如 图5 所示,基于微积分知识,求一条曲线在某个点的斜率等于函数该点的导数值。那么大家思考下,当处于曲线的极值点时,该点的斜率是多少?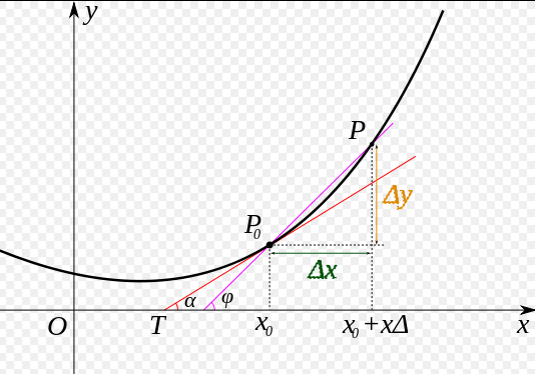
图5:曲线斜率等于导数值
这个问题并不难回答,处于曲线极值点时的斜率为0,即函数在极值点处的导数为0。那么,让损失函数取极小值的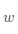 和
和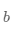 应该是下述方程组的解:
应该是下述方程组的解:
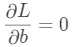
将样本数据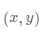 带入上面的方程组中即可求解出
带入上面的方程组中即可求解出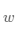 和
和 的值,但是这种方法只对线性回归这样简单的任务有效。如果模型中含有非线性变换,或者损失函数不是均方差这种简单的形式,则很难通过上式求解。为了解决这个问题,下面我们将引入更加普适的数值求解方法:梯度下降法。
的值,但是这种方法只对线性回归这样简单的任务有效。如果模型中含有非线性变换,或者损失函数不是均方差这种简单的形式,则很难通过上式求解。为了解决这个问题,下面我们将引入更加普适的数值求解方法:梯度下降法。
梯度下降法
在现实中存在大量的函数正向求解容易,反向求解较难,被称为单向函数。这种函数在密码学中有大量的应用,密码锁的特点是可以迅速判断一个密钥是否是正确的(已知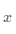 ,求
,求 很容易),但是即使获取到密码锁系统,无法破解出正确的密钥是什么(已知
很容易),但是即使获取到密码锁系统,无法破解出正确的密钥是什么(已知 ,求
,求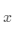 很难)。
很难)。
这种情况特别类似于一位想从山峰走到坡谷的盲人,他看不见坡谷在哪(无法逆向求解出 导数为0时的参数值),但可以伸脚探索身边的坡度(当前点的导数值,也称为梯度)。那么,求解Loss函数最小值可以这样实现:从当前的参数取值,一步步的按照下坡的方向下降,直到走到最低点。这种方法笔者称它为“盲人下坡法”。哦不,有个更正式的说法“梯度下降法”。
导数为0时的参数值),但可以伸脚探索身边的坡度(当前点的导数值,也称为梯度)。那么,求解Loss函数最小值可以这样实现:从当前的参数取值,一步步的按照下坡的方向下降,直到走到最低点。这种方法笔者称它为“盲人下坡法”。哦不,有个更正式的说法“梯度下降法”。
观察上述曲线呈现出“圆滑”的坡度,这正是我们选择以均方误差作为损失函数的原因之一。图6 呈现了只有一个参数维度时,均方误差和绝对值误差(只将每个样本的误差累加,不做平方处理)的损失函数曲线图。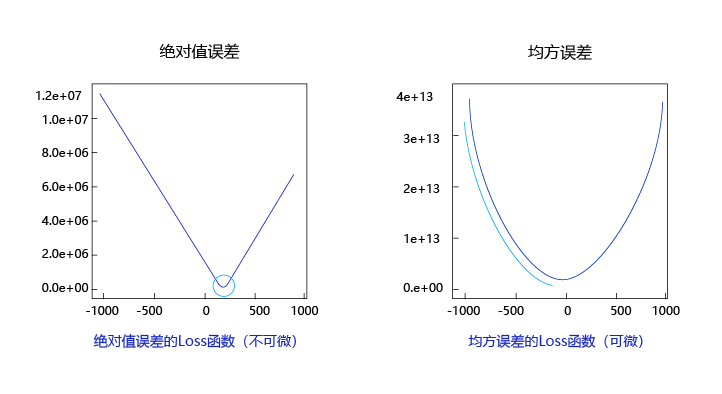
图6:均方误差和绝对值误差损失函数曲线图
由此可见,均方误差表现的“圆滑”的坡度有两个好处:
- 曲线的最低点是可导的。
- 越接近最低点,曲线的坡度逐渐放缓,有助于通过当前的梯度来判断接近最低点的程度(是否逐渐减少步长,以免错过最低点)。
而这两个特性绝对值误差是不具备的,这也是损失函数的设计不仅仅要考虑“合理性”,还要追求“易解性”的原因。
使用Numpy进行梯度计算
基于Numpy广播机制(对向量和矩阵计算如同对1个单一变量计算一样),可以更快速的实现梯度计算。计算梯度的代码中直接用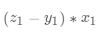 ,得到的是一个13维的向量,每个分量分别代表该维度的梯度。
,得到的是一个13维的向量,每个分量分别代表该维度的梯度。
确定损失函数更小的点
下面我们开始研究更新梯度的方法。首先沿着梯度的反方向移动一小步,找到下一个点P1,观察损失函数的变化。
# 在[w5, w9]平面上,沿着梯度的反方向移动到下一个点P1# 定义移动步长 etaeta = 0.1# 更新参数w5和w9net.w[5] = net.w[5] - eta * gradient_w5net.w[9] = net.w[9] - eta * gradient_w9# 重新计算z和lossz = net.forward(x)loss = net.loss(z, y)gradient_w, gradient_b = net.gradient(x, y)gradient_w5 = gradient_w[5][0]gradient_w9 = gradient_w[9][0]print('point {}, loss {}'.format([net.w[5][0], net.w[9][0]], loss))print('gradient {}'.format([gradient_w5, gradient_w9]))
point [-99.91499266760042, -99.38615876351922], loss 678.6472185028845gradient [-0.8556356178645292, -6.0932268634065805]
运行上面的代码,可以发现沿着梯度反方向走一小步,下一个点的损失函数的确减少了。感兴趣的话,大家可以尝试不停的点击上面的代码块,观察损失函数是否一直在变小。
在上述代码中,每次更新参数使用的语句:net.w[5] = net.w[5] - eta * gradient_w5
- 相减:参数需要向梯度的反方向移动。
- eta:控制每次参数值沿着梯度反方向变动的大小,即每次移动的步长,又称为学习率。
大家可以思考下,为什么之前我们要做输入特征的归一化,保持尺度一致?这是为了让统一的步长更加合适。
如 图8 所示,特征输入归一化后,不同参数输出的Loss是一个比较规整的曲线,学习率可以设置成统一的值 ;特征输入未归一化时,不同特征对应的参数所需的步长不一致,尺度较大的参数需要大步长,尺寸较小的参数需要小步长,导致无法设置统一的学习率。
图8:未归一化的特征,会导致不同特征维度的理想步长不同
随机梯度下降法( Stochastic Gradient Descent)
在上述程序中,每次损失函数和梯度计算都是基于数据集中的全量数据。对于波士顿房价预测任务数据集而言,样本数比较少,只有404个。但在实际问题中,数据集往往非常大,如果每次都使用全量数据进行计算,效率非常低,通俗地说就是“杀鸡焉用牛刀”。由于参数每次只沿着梯度反方向更新一点点,因此方向并不需要那么精确。一个合理的解决方案是每次从总的数据集中随机抽取出小部分数据来代表整体,基于这部分数据计算梯度和损失来更新参数,这种方法被称作随机梯度下降法(Stochastic Gradient Descent,SGD),核心概念如下:
- min-batch:每次迭代时抽取出来的一批数据被称为一个min-batch。
- batch_size:一个mini-batch所包含的样本数目称为batch_size。
- epoch:当程序迭代的时候,按mini-batch逐渐抽取出样本,当把整个数据集都遍历到了的时候,则完成了一轮训练,也叫一个epoch。启动训练时,可以将训练的轮数num_epochs和batch_size作为参数传入。
下面结合程序介绍具体的实现过程,涉及到数据处理和训练过程两部分代码的修改。
数据处理代码修改
数据处理需要实现拆分数据批次和样本乱序(为了实现随机抽样的效果)两个功能。
说明:
通过大量实验发现,模型对最后出现的数据印象更加深刻。训练数据导入后,越接近模型训练结束,最后几个批次数据对模型参数的影响越大。为了避免模型记忆影响训练效果,需要进行样本乱序操作。
训练过程代码修改
将每个随机抽取的mini-batch数据输入到模型中用于参数训练。训练过程的核心是两层循环:
- 第一层循环,代表样本集合要被训练遍历几次,称为“epoch”,代码如下:
for epoch_id in range(num_epoches):
- 第二层循环,代表每次遍历时,样本集合被拆分成的多个批次,需要全部执行训练,称为“iter (iteration)”,代码如下:
for iter_id,mini_batch in emumerate(mini_batches):
在两层循环的内部是经典的四步训练流程:前向计算->计算损失->计算梯度->更新参数,这与大家之前所学是一致的,代码如下:
x = mini_batch[:, :-1]y = mini_batch[:, -1:]a = self.forward(x) #前向计算loss = self.loss(a, y) #计算损失gradient_w, gradient_b = self.gradient(x, y) #计算梯度self.update(gradient_w, gradient_b, eta) #更新参数
总结
本节我们详细介绍了如何使用Numpy实现梯度下降算法,构建并训练了一个简单的线性模型实现波士顿房价预测,可以总结出,使用神经网络建模房价预测有三个要点:
- 构建网络,初始化参数w和b,定义预测和损失函数的计算方法。
- 随机选择初始点,建立梯度的计算方法和参数更新方式。
- 从总的数据集中抽取部分数据作为一个mini_batch,计算梯度并更新参数,不断迭代直到损失函数几乎不再下降。
代码:
在AI studio或者Anaconda Navigator可运行# -*- coding: utf-8 -*-#波士顿房价预测 用线性回归来做import numpy as npimport jsonimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3D#数据处理,数据处理包含五个部分:数据导入、数据形状变换、数据集划分、数据归一化处理和封装load data函数。def load_data():# 从文件导入数据datafile = './work/housing.data'data = np.fromfile(datafile, sep=' ')# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状data = data.reshape([data.shape[0] // feature_num, feature_num])# 将原数据集拆分成训练集和测试集# 这里使用80%的数据做训练,20%的数据做测试# 测试集和训练集必须是没有交集的ratio = 0.8offset = int(data.shape[0] * ratio)training_data = data[:offset]# 计算训练集的最大值,最小值,平均值maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \training_data.sum(axis=0) / training_data.shape[0]# 对数据进行归一化处理for i in range(feature_num):#print(maximums[i], minimums[i], avgs[i])data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i])# 训练集和测试集的划分比例training_data = data[:offset]test_data = data[offset:]return training_data, test_data# 获取数据training_data, test_data = load_data()x = training_data[:, :-1]y = training_data[:, -1:]# 查看数据# =============================================================================# print(x[0])# print(y[0])## w = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, -0.1, -0.2, -0.3, -0.4, 0.0]# w = np.array(w).reshape([13, 1])## x1=x[0]# t = np.dot(x1, w)# print(t)# b = -0.2# z = t + b# print(z)# =============================================================================#模型设计:线性回归,使用均方误差作为评价模型好坏的指标class Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ycost = error * errorcost = np.mean(cost)return costnet = Network(13)# 此处可以一次性计算多个样本的预测值和损失函数x1 = x[0:3]y1 = y[0:3]z = net.forward(x1)print('predict: ', z)loss = net.loss(z, y1)print('loss:', loss)net = Network(13)losses = []#只画出参数w5和w9在区间[-160, 160]的曲线部分,以及包含损失函数的极值w5 = np.arange(-160.0, 160.0, 1.0)w9 = np.arange(-160.0, 160.0, 1.0)losses = np.zeros([len(w5), len(w9)])#计算设定区域内每个参数取值所对应的Lossfor i in range(len(w5)):for j in range(len(w9)):net.w[5] = w5[i]net.w[9] = w9[j]z = net.forward(x)loss = net.loss(z, y)losses[i, j] = loss#使用matplotlib将两个变量和对应的Loss作3D图#import matplotlib.pyplot as plt#from mpl_toolkits.mplot3d import Axes3Dfig = plt.figure()ax = Axes3D(fig)w5, w9 = np.meshgrid(w5, w9)ax.plot_surface(w5, w9, losses, rstride=1, cstride=1, cmap='rainbow')plt.show()# 调用上面定义的gradient函数,计算梯度# 初始化网络net = Network(13)# 设置[w5, w9] = [-100., -100.]net.w[5] = -100.0net.w[9] = -100.0z = net.forward(x)loss = net.loss(z, y)#计算梯度class Network1(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ynum_samples = error.shape[0]cost = error * errorcost = np.sum(cost) / num_samplesreturn costdef gradient(self, x, y):z = self.forward(x)gradient_w = (z-y)*xgradient_w = np.mean(gradient_w, axis=0)gradient_w = gradient_w[:, np.newaxis]gradient_b = (z - y)gradient_b = np.mean(gradient_b)return gradient_w, gradient_bdef update(self, gradient_w, gradient_b, eta = 0.01):self.w = self.w - eta * gradient_wself.b = self.b - eta * gradient_bdef train(self, x, y, iterations=100, eta=0.01):losses = []for i in range(iterations):z = self.forward(x)L = self.loss(z, y)gradient_w, gradient_b = self.gradient(x, y)self.update(gradient_w, gradient_b, eta)losses.append(L)if (i+1) % 10 == 0:print('iter {}, loss {}'.format(i, L))return losses# 获取数据train_data, test_data = load_data()x = train_data[:, :-1]y = train_data[:, -1:]# 创建网络net = Network1(13)num_iterations=1000# 启动训练losses = net.train(x,y, iterations=num_iterations, eta=0.01)# 画出损失函数的变化趋势plot_x = np.arange(num_iterations)plot_y = np.array(losses)plt.plot(plot_x, plot_y)plt.show()#随机梯度下降法class Network2(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子#np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.def forward(self, x):z = np.dot(x, self.w) + self.breturn zdef loss(self, z, y):error = z - ynum_samples = error.shape[0]cost = error * errorcost = np.sum(cost) / num_samplesreturn costdef gradient(self, x, y):z = self.forward(x)N = x.shape[0]gradient_w = 1. / N * np.sum((z-y) * x, axis=0)gradient_w = gradient_w[:, np.newaxis]gradient_b = 1. / N * np.sum(z-y)return gradient_w, gradient_bdef update(self, gradient_w, gradient_b, eta = 0.01):self.w = self.w - eta * gradient_wself.b = self.b - eta * gradient_bdef train(self, training_data, num_epoches, batch_size=10, eta=0.01):n = len(training_data)losses = []for epoch_id in range(num_epoches):# 在每轮迭代开始之前,将训练数据的顺序随机打乱# 然后再按每次取batch_size条数据的方式取出np.random.shuffle(training_data)# 将训练数据进行拆分,每个mini_batch包含batch_size条的数据mini_batches = [training_data[k:k+batch_size] for k in range(0, n, batch_size)]for iter_id, mini_batch in enumerate(mini_batches):#print(self.w.shape)#print(self.b)x = mini_batch[:, :-1]y = mini_batch[:, -1:]a = self.forward(x)loss = self.loss(a, y)gradient_w, gradient_b = self.gradient(x, y)self.update(gradient_w, gradient_b, eta)losses.append(loss)print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.format(epoch_id, iter_id, loss))return losses# 获取数据train_data, test_data = load_data()# 创建网络net = Network2(13)# 启动训练losses = net.train(train_data, num_epoches=50, batch_size=100, eta=0.1)# 画出损失函数的变化趋势plot_x = np.arange(len(losses))plot_y = np.array(losses)plt.plot(plot_x, plot_y)plt.show()
备注:markdown格式编辑用的是Typora;排版用的是颜家大少的杰作:http://md.aclickall.com/

若有收获,就点个赞吧
0 人点赞
