人脸识别
功能简介
人脸识别技术是基于人的脸部特征,对输入的人脸图像或者视频流,首先判断其是否存在人脸,如果存在人脸,则进一步的给出每个脸的位置、大小和各个主要面部器官的位置信息。并依据这些信息,进一步提取每个人脸中所蕴涵的身份特征,并将其与已知的人脸进行对比,从而识别每个人脸的身份。
广义的人脸识别实际包括构建人脸识别系统的一系列相关技术,包括人脸图像采集、人脸定位、人脸识别预处理、身份确认以及身份查找等;而狭义的人脸识别特指通过人脸进行身份确认或者身份查找的技术或系统。
技术流程
人脸识别系统主要包括四个组成部分,分别为:人脸图像采集及检测、人脸图像预处理、人脸图像特征提取以及匹配与识别。
人脸图像采集及检测
人脸图像采集:不同的人脸图像都能通过摄像镜头采集下来,比如静态图像、动态图像、不同的位置、不同表情等方面都可以得到很好的采集。当用户在采集设备的拍摄范围内时,采集设备会自动搜索并拍摄用户的人脸图像。
人脸检测:人脸检测在实际中主要用于人脸识别的预处理,即在图像中准确标定出人脸的位置和大小。人脸图像中包含的模式特征十分丰富,如直方图特征、颜色特征、模板特征、结构特征及Haar特征等。人脸检测就是把这其中有用的信息挑出来,并利用这些特征实现人脸检测。
主流的人脸检测方法基于以上特征采用Adaboost学习算法,Adaboost算法是一种用来分类的方法,它把一些比较弱的分类方法合在一起,组合出新的很强的分类方法。
人脸检测过程中使用Adaboost算法挑选出一些最能代表人脸的矩形特征(弱分类器),按照加权投票的方式将弱分类器构造为一个强分类器,再将训练得到的若干强分类器串联组成一个级联结构的层叠分类器,有效地提高分类器的检测速度。
人脸图像预处理
人脸图像预处理:对于人脸的图像预处理是基于人脸检测结果,对图像进行处理并最终服务于特征提取的过程。系统获取的原始图像由于受到各种条件的限制和随机干扰,往往不能直接使用,必须在图像处理的早期阶段对它进行灰度校正、噪声过滤等图像预处理。对于人脸图像而言,其预处理过程主要包括人脸图像的光线补偿、灰度变换、直方图均衡化、归一化、几何校正、滤波以及锐化等。
人脸图像特征提取
人脸图像特征提取:人脸识别系统可使用的特征通常分为视觉特征、像素统计特征、人脸图像变换系数特征、人脸图像代数 特征等。人脸特征提取就是针对人脸的某些特征进行的。人脸特征提取,也称人脸表征,它是对人脸进行特征建模的过程。人脸特征提取的方法归纳起来分为两大类:一种是基于知识的表征方法;另外一种是基于代数特征或统计学习的表征方法。
基于知识的表征方法主要是根据人脸器官的形状描述以及他们之间的距离特性来获得有助于人脸分类的特征数据,其特征分量通常包括特征点间的欧氏距离、曲率和角度等。人脸由眼睛、鼻子、嘴、下巴等局部构成,对这些局部和它们之间结构关系的几何描述,可作为识别人脸的重要特征,这些特征被称为几何特征。基于知识的人脸表征主要包括基于几何特征的方法和模板匹配法。
人脸图像匹配与识别
人脸图像匹配与识别:提取的人脸图像的特征数据与数据库中存储的特征模板进行搜索匹配,通过设定一个阈值,当相似度超过这一阈值,则把匹配得到的结果输出。人脸识别就是将待识别的人脸特征与已得到的人脸特征模板进行比较,根据相似程度对人脸的身份信息进行判断。这一过程又分为两类:一类是确认,是一对一进行图像比较的过程,另一类是辨认,是一对多进行图像匹配对比的过程。
功能实现
常见的人脸识别算法
(1)几何特征的人脸识别方法:几何特征可以是眼、鼻、嘴等的形状和它们之间的几何关系(如相互之间的距离)。这些算法识别速度快,需要的内存小,但识别率较低。
(2)基于特征脸(PCA)的人脸识别方法:特征脸方法是基于KL变换的人脸识别方法,KL变换是图像压缩的一种最优正交变换。高维的图像空间经过KL变换后得到一组新的正交基,保留其中重要的正交基,由这些基可以张成低维线性空间。如果假设人脸在这些低维线性空间的投影具有可分性,就可以将这些投影用作识别的特征矢量,这就是特征脸方法的基本思想。这些方法需要较多的训练样本,而且完全是基于图像灰度的统计特性的。目前有一些改进型的特征脸方法。
(3)神经网络的人脸识别方法:神经网络的输入可以是降低分辨率的人脸图像、局部区域的自相关函数、局部纹理的二阶矩等。这类方法同样需要较多的样本进行训练,而在许多应用中,样本数量是很有限的。
前端版
基于trackingjs实现
源码地址:https://github.com/eduardolundgren/tracking.js
这是一款github上一个star目前超过8k的前端人脸识别和图像识别项目。
人脸识别示例:

摄像头颜色检测示例:

examples文件夹里还包括其他的示例,可自行探索。下面是对官方文档的翻译。
在开始之前:下载这个项目
首先你需要下载这个项目。这个项目包含tracking.js,示例以及源码。
解压项目到本地文件。当你开始的时候,你需要一个最基本HTTP服务器。加载这个项目的最终版本来检测这个web服务器,比如http://localhost:8000/tracking.js/
第一步:创建示例文件
这一步,你将会在examples/文件夹下创建示例文件。进入这个文件夹并创建first_tracking.html,并且使用你最喜欢的IDE。 这个文件最开始应该像是这样的:
<!doctype html><html><head><meta charset="utf-8"><title>tracking.js - first tracking</title><script src="../build/tracking-min.js"></script></head><body><script>// Start tracking here...</script></body></html>
第二步:选择你最想玩的那个
现在你有了first_tracking.html,接下来就选择你最想使用的技术了。这个文件夹里有一些示例。第一个Tracker是其他追踪技术的基础抽象类,无法被示例化。但你可以以ColorTracker作为开始,复制代码片段然后粘贴进你的文件里,最后看起来像是这样。
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>tracking.js - first tracking</title>
<script src="../build/tracking-min.js"></script>
</head>
<body>
<video id="myVideo" width="400" height="300" preload autoplay loop muted></video>
<script>
var colors = new tracking.ColorTracker(['magenta', 'cyan', 'yellow']);
colors.on('track', function(event) {
if (event.data.length === 0) {
// No colors were detected in this frame.
} else {
event.data.forEach(function(rect) {
console.log(rect.x, rect.y, rect.height, rect.width, rect.color);
});
}
});
tracking.track('#myVideo', colors);
</script>
</body>
</html>
这个例子将会请求你的电脑上的摄像机,并且追踪洋红色(magenta),青蓝色(cyan )和黄色(yellow)。看看你的电脑周围有什么东西符合这些颜色,然后放到摄像机面前,然后看看浏览器的反应。这应该在检测的颜色周围出现一个包围框。
Trackers
为了理解tracker的API是如何工作的,首先你应该实例化一个对于你想检测对象的构造器,注意tracking.Tracker只是一个抽象类。
var myTracker = new tracking.Tracker('target');
有了tracker实例后,肯定会有些什么东西需要出,这就是为什么监听track事件的原因
myTracker.on('track', function(event) {
if (event.data.length === 0) {
// No targets were detected in this frame.
} else {
event.data.forEach(function(data) {
// Plots the detected targets here.
});
}
});
现在你有了tracker实例,并且监听track事件,然后调用myTracker.track(pixels, width, height)就可以开始追踪物体。这个方法会处理所有的像素但是不用担心,你不用手动读取
var trackerTask = tracking.track('#myVideo', myTracker);
也可以将这个track实例插入其他元素里,当追踪
如果你想做更多的事,你需要阅读剩下的部分。现在假设里你需要在一部很长的视频里停止追踪物体。
trackerTask.stop(); // 停止追踪
trackerTask.run(); // 再次开始追踪
之前例子是一个这个API的抽象概述。现在来让我们看看更多实用的例子。
颜色追踪
每个物体上每处地方都有颜色。如果能通过浏览器调用摄像头来处理有特定颜色的物体将非常吸引人。因此,tracking.js提供了一个基本的颜色追踪算法,这样可以实时追踪每一帧的特定颜色。这个简单易用符合直觉的API,拥有计算简单性、部分遮挡和照明下、旋转、比例和分辨率变化下的顽健性等显著优势。
要使用颜色追踪,你应该如下实例化构造器。
var colors = new tracking.ColorTracker(['magenta', 'cyan', 'yellow']);
当你有了颜色追踪实例,你需要知道颜色追踪应该在什么时候发生,这就是为什么你需要监听track事件的。
colors.on('track', function(event) {
if (event.data.length === 0) {
// No colors were detected in this frame.
} else {
event.data.forEach(function(rect) {
// rect.x, rect.y, rect.height, rect.width, rect.color
});
}
});
现在你有了一个tracker实例,并且在监听track事件,你需要开始监听:
tracking.track('#myVideo', colors);
如何才能追踪自己设置的颜色?tracking.js默认提供了3种颜色,即洋红色(magenta),青蓝色(cyan )和黄色(yellow)。如果需要增加自定义颜色非常简单,假设你需要添加的是绿色,那么RGB颜色值即(r, g, b) = (0, 255, 0),然后即可用tracking.ColorTracker.registerColor来使用这种颜色。
tracking.ColorTracker.registerColor('green', function(r, g, b) {
if (r < 50 && g > 200 && b < 50) {
return true;
}
return false;
});
注意我们检测的是近似于这个颜色的值,如果某个颜色接近绿色的,即g>200,r<50,b<50则返回真。
物体追踪
这个js库能够快速在网络上实现物体追踪,比如面部,嘴巴,眼睛或其他以后会被添加进这个库的东西。
在tracking.js核心脚本之上,还有一些分类器,将会告诉tracking.js如何检测你想要检测的物体,确保只使用你需要使用的,因为每个文件大约都是60kb。
<script src="tracking.js/build/data/face.js"></script>
<script src="tracking.js/build/data/eye.js"></script>
<script src="tracking.js/build/data/mouth.js"></script>
要使用物体追踪,你需要实例化构造器,并传递你需要检测的物体分类器。
var objects = new tracking.ObjectTracker(['face', 'eye', 'mouth']);
Once you have the object tracker instance, you need to know when something happens, that’s why you need listen fortrackevents:
当你有了物体追踪实例后,你需要知道这物体什么时候会被检测到,这就是为什么你需要监听track事件的。
objects.on('track', function(event) {
if (event.data.length === 0) {
// No objects were detected in this frame.
} else {
event.data.forEach(function(rect) {
// rect.x, rect.y, rect.height, rect.width
});
}
});
现在你有了一个tracker实例,并且在监听track事件,你需要开始监听:
tracking.track('#myVideo', objects);
自定义追踪
如果你需要自动追踪器也是非常简单。
比如由于某些原因,你需要检测图像中的阴影。我们目前并没有提供这种追踪器,所以你需要自己实现这种算法。
别急着走开!你可以基于tracking.js创建自己需要的东西,还能使用所有的抽象类,比如取得摄像头的权限或在每帧都获取到像素矩阵,而无需自己手动去写。
非常简单!首先,你需要为你的新的追踪器创建一个构造器,叫它Mytracker,继承自tracking.Tracker。
var MyTracker = function() {
MyTracker(this, 'constructor');
}
tracking.inherits(MyTracker, tracking.Tracker);
然后你需要需要实现你的的追踪器使用的track方法。它将会接受图像或视频每帧的像素矩阵 ,然后执行其中的算法。当追踪完成,将会调用emit方法将结果发送到track事件中去。
var MyTracker = function() {
MyTracker.prototype.track = function(pixels, width, height) {
// Your code here
this.emit('track', {
// Your results here
});
}
}
就这些!然后就像默认的追踪器那样,你可以使用自己的追踪器了。
var myTracker = new tracking.MyTracker();
然后监听track事件
myTracker.on('track', function(event) {
// Results are inside the event
});
最后,开始追踪:
tracking.track('#myVideo', myTracker);
实用工具
为了更好地理解库体系结构,实现分为几个实用程序,它还包括几个计算机视觉算法,以帮助实现自定义解决方案。仅使用原始 JavaScript API 开发计算机视觉应用程序可能过于冗长和复杂,例如捕获用户的摄像头并读取其像素数组。
为了简化开发,需要一定程度的封装。这个库为 Web 平台上的常见任务提供了封装。
特征检测 (Fast)
为特征检测而提供了Features from Accelerated Segment Test的一种实现方法。或者说,可以可以检测图像的角点。Fast比许多其他已知的方法要快:
为了检测角点,你需要如下实现:
var corners = tracking.Fast.findCorners(pixels, width, height);
特征描述器 (Brief)
为Binary Robust Independent Elementary Features提供了实现方法。它使用二元字符串作为高效的特征点描述器。结果就是Brief是在网络上无论是构建或是检测都非常快。
当你提取出了图像的特征,在之前的例子中这个特征是图像的角点,你可以描述它们:
var descriptors1 = tracking.Brief.getDescriptors(pixels, width, corners1);
var descriptors2 = tracking.Brief.getDescriptors(pixels, width, corners2);
Brief also provides a method that you can match the features decribed in
Brief提供了你可以用于匹配descriptors1和descriptors2特征的方法。
var matches = tracking.Brief.reciprocalMatch(corners1, descriptors1, corners2, descriptors2);
卷积
卷积过滤器在图像中非常常见。本质上来说就是在源图像里使用有一个矩形里权重的像素点作为输出值,可以用于模糊,尖锐,腐蚀或边缘检测以及很多其他的事情。
你可以使用水平卷积:
tracking.Image.horizontalConvolve(pixels, width, height, weightsVector, opaque);
或是垂直卷积
tracking.Image.verticalConvolve(pixels, width, height, weightsVector, opaque);
或是可分离卷积
tracking.Image.separableConvolve(pixels, width, height, horizWeights, vertWeights, opaque);
灰度
基于照度将一幅RGB图片转换为灰度图。系数代表典型的人类的测量强度感知,特别是,人类视觉对绿色最敏感,对蓝色最不敏感。
将图像转换为灰度图:
tracking.Image.grayscale(pixels, width, height, fillRGBA);
图像模糊
高斯模糊(或者叫做高斯平滑)是使用高斯函数后的模糊结果,被广泛用在图像处理中,一般用来去除噪音或减少细节。高斯平滑也通常用来在计算机视觉算法作为预处理,来增强图片的结构感。
使用tracking.js来模糊图像应该像下面这样:
tracking.Image.blur(pixels, width, height, diameter);
积分图像
区域面积之和的表是一种数据结构和算法,用于快速高效地生成矩形网格的子集中的值总和。在图像处理域中,它也称为积分图像。
你需要在tracking.js中这样做:
tracking.Image.computeIntegralImage(
pixels, width, height, opt_integralImage, opt_integralImageSquare,
opt_tiltedIntegralImage, opt_integralImageSobel);
Sobel
计算图像的垂直和水平渐变,并合并计算的图像以查找图像中的边缘。我们在这里实现 Sobel 算子的方式是首先对图像进行灰度缩放,然后采用水平和垂直渐变,最后组合渐变图像来组成最终图像。
要使用 track.js 计算图像像素的边缘,您可以执行以下操作:
tracking.Image.sobel(pixels, width, height);
Viola Jones
Viola–Jones对象检测框架是第一个提供具有竞争力的对象实时检测速率的对象检测框架。这个技术在tracking.ObjectTracker中使用。
要在 track.js 使用 Viola Jones 检测图像,您可以执行:
tracking.ViolaJones.detect(pixels, width, height, initialScale, scaleFactor, stepSize, edgesDensity, classifier);
网页组件
许多已知的计算机视觉框架不适用于网页,而且难以使用。tracking,js的主要目标就是将这些复杂技术转换为能在网页上使用的简单方法。我们详细计算机视觉的发展能够提高人们的生活质量,将计算机视觉带进网页浏览器能更快促使其成真。
我们相信Web Components这网页组件使用了tracking.js。
你能想象在网页上标记你的朋友的脸吗?或者使用同样的API追踪用户的脸吗?这个章节将告诉你如何做到这一点。这需要Bower——一个前端包管理器,当你安装好了bower后,然后安装tracking-elements
$ bower install tracking-elements --save
安装了tracking-elements后,可以使用一些自定义元素。它们扩展了原生的
颜色元素
为了使用tracking.js这个web组件,你需要知道如何使用is=""这个attribute来扩展原生DOM元素。需要被追踪的目标使用target=""这个attribute,可以接受不同的值。
<img is="image-color-tracking" target="magenta cyan yellow" />
<canvas is="canvas-color-tracking" target="magenta cyan yellow"></canvas>
<video is="video-color-tracking" target="magenta cyan yellow"></video>
你可以使用attribute的camera="true"来要求使用摄像机。注意这样浏览器会发出使用摄像机的请求而且需要用户允许。这个自定义元素暴露来自Tracker的事件和方法,更多信息请参考下面的API docs。下一个例子将说明如何使用ObjectTracker来为你的朋友的脸打上标记。
物体元素
我们来创建一个你可以放上你的朋友的脸,并且用矩形标记它们的实例。在这一步,你需要创建一个在examples/文件夹下面创建一个文件tracking_element.html,并且使用你最喜欢的IDE。这个文件最开始如下:
<!DOCTYPE html>
<html>
<head>
<!-- Importing Web Component's Polyfill -->
<script src="bower/platform/platform.js"></script>
<!-- Importing Custom Elements -->
<link rel="import" href="../src/image-object-tracking.html">
</head>
<body>
<!-- Using Custom Elements -->
<img is="image-object-tracking" target="face" src="assets/faces.png" />
<script>
// Plots rectangles here.
</script>
</body>
</html>
下一步将是如何在你的朋友的脸上绘制一个矩形,你可以直接在DOM元素中监听track事件,即img.addEventListener('track', doSomething).这个事件将在图片里的所有脸部检测完后被去除。而event.data是一个包含了所有脸部坐标的数组。然后把它们传进helper函数plotRectangles来绘制每个脸部。
<!DOCTYPE html>
<html>
<head>
<!-- Importing Web Component's Polyfill -->
<script src="bower/platform/platform.js"></script>
<!-- Importing Custom Elements -->
<link rel="import" href="../src/image-object-tracking.html">
</head>
<body>
<!-- Using Custom Elements -->
<img is="image-object-tracking" target="face" src="assets/faces.png" />
<script>
var img = document.querySelector('img');
// Fires when faces are found on the image.
img.addEventListener('track', function(event) {
event.detail.data.forEach(function(rect) {
plotRectangle(img, rect);
});
});
function plotRectangle(el, rect) {
var div = document.createElement('div');
div.style.position = 'absolute';
div.style.border = '2px solid ' + (rect.color || 'magenta');
div.style.width = rect.width + 'px';
div.style.height = rect.height + 'px';
div.style.left = el.offsetLeft + rect.x + 'px';
div.style.top = el.offsetTop + rect.y + 'px';
document.body.appendChild(div);
return div;
}
</script>
</body>
</html>
后端版
// TODO,后续有时间在补充,目前先实现前端版,后端版实现的参考链接:https://blog.csdn.net/boling_cavalry/article/details/118970439
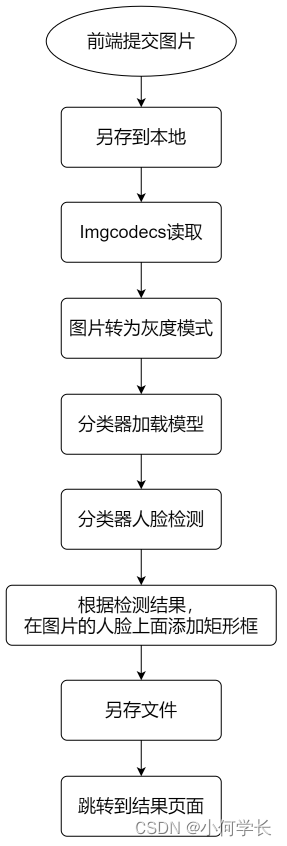
核心代码
前端版(已实现)
<template>
<div class="body">
<h1 >人脸探测</h1>
<br/>
<div class="video-box" style="margin: auto">
<video id="video" width="330" height="250" preload autoPlay loop muted></video>
<canvas id="canvas" width="320" height="240"></canvas>
</div>
<canvas id="screenshotCanvas" width="320" height="240"></canvas>
<br/>
<h1>实时截图</h1>
<img :src="base64Img" >
<br/>
<el-button type="danger" round @click="end" style="margin-top: 10px ">停止探测</el-button>
<el-button type="success" round @click="goon" style="margin-top: 10px ">继续探测</el-button>
</div>
</template>
<script>
import '@/assets/tracking/build/tracking-min.js'
import '@/assets/tracking/build/data/face-min.js'
export default {
data() {
return {
base64Img: '',
video: null,
screenshotCanvas: null,
uploadLock: true // 上传锁
}
},
mounted() {
this.init()
},
methods: {
// 初始化设置
init() {
this.video = document.getElementById('video')
this.screenshotCanvas = document.getElementById('screenshotCanvas')
let canvas = document.getElementById('canvas')
let context = canvas.getContext('2d')
// 固定写法
let tracker = new window.tracking.ObjectTracker('face')
tracker.setInitialScale(4)
tracker.setStepSize(2)
tracker.setEdgesDensity(0.1)
this.trackerTask = window.tracking.track('#video', tracker, {
camera: true
})
let _this = this
tracker.on('track', function(event) {
// 检测出人脸 绘画人脸位置
context.clearRect(0, 0, canvas.width, canvas.height)
event.data.forEach(function(rect) {
context.strokeStyle = '#0764B7'
context.strokeRect(rect.x, rect.y, rect.width, rect.height)
context.font = '11px Helvetica';
context.fillStyle = "#fff";
context.fillText('人脸目标 ', rect.x, rect.y);
context.fillText('x: ' + rect.x + 'px', rect.x + rect.width + 5, rect.y + 11);
context.fillText('y: ' + rect.y + 'px', rect.x + rect.width + 5, rect.y + 22);
// 上传图片
// _this.uploadLock &&
_this.screenshotAndUpload()
})
})
},
// 上传图片
screenshotAndUpload() {
// 上锁避免重复发送请求
this.uploadLock = false
// 绘制当前帧图片转换为base64格式
let canvas = this.screenshotCanvas
let video = this.video
let ctx = canvas.getContext('2d')
ctx.clearRect(0, 0, canvas.width, canvas.height)
ctx.drawImage(video, 0, 0, canvas.width, canvas.height)
let base64Img = canvas.toDataURL('image/jpeg')
this.base64Img = base64Img;
// 使用 base64Img 请求接口即可
console.log('base64Img:', base64Img)
// 请求接口成功以后打开锁
// this.uploadLock = true;
},
end() {
// 停止侦测
this.trackerTask.stop();
// 关闭摄像头
this.trackerTask.closeCamera();
},
goon(){
this.init()
}
},
destroyed() {
// 停止侦测
this.trackerTask.stop();
// 关闭摄像头
this.trackerTask.closeCamera();
},
}
</script>
<style scoped>
.body {
font-family: Arial;
text-align: center;
}
/* 绘图canvas 不需显示隐藏即可 */
#screenshotCanvas {
display: none;
}
.video-box {
position: relative;
width: 320px;
height: 240px;
}
video, canvas {
position: absolute;
top: 0;
left: 0;
border: #000000 5px solid;
}
</style>
后端版(待完善)
以下代码来源我参考de博文https://xinchen.blog.csdn.net/article/details/118970439,后期实现会加以借鉴,这里附上给大家参考一下。
package com.bolingcavalry.facedetect.controller;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.ResourceLoader;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.io.IOException;
import java.util.Map;
import org.opencv.core.*;
import org.opencv.imgcodecs.Imgcodecs;
import org.opencv.imgproc.Imgproc;
import org.opencv.objdetect.CascadeClassifier;
import java.util.UUID;
import static org.bytedeco.javacpp.opencv_objdetect.CV_HAAR_DO_CANNY_PRUNING;
@Controller
@Slf4j
public class UploadController {
static {
// 加载 动态链接库
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
}
private final ResourceLoader resourceLoader;
@Autowired
public UploadController(ResourceLoader resourceLoader) {
this.resourceLoader = resourceLoader;
}
@Value("${web.upload-path}")
private String uploadPath;
@Value("${opencv.model-path}")
private String modelPath;
/**
* 跳转到文件上传页面
* @return
*/
@RequestMapping("index")
public String toUpload(){
return "index";
}
/**
* 上次文件到指定目录
* @param file 文件
* @param path 文件存放路径
* @param fileName 源文件名
* @return
*/
private static boolean upload(MultipartFile file, String path, String fileName){
//使用原文件名
String realPath = path + "/" + fileName;
File dest = new File(realPath);
//判断文件父目录是否存在
if(!dest.getParentFile().exists()){
dest.getParentFile().mkdir();
}
try {
//保存文件
file.transferTo(dest);
return true;
} catch (IllegalStateException e) {
// TODO Auto-generated catch block
e.printStackTrace();
return false;
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
return false;
}
}
/**
*
* @param file 要上传的文件
* @return
*/
@RequestMapping("fileUpload")
public String upload(@RequestParam("fileName") MultipartFile file, @RequestParam("minneighbors") int minneighbors, Map<String, Object> map){
log.info("file [{}], size [{}], minneighbors [{}]", file.getOriginalFilename(), file.getSize(), minneighbors);
String originalFileName = file.getOriginalFilename();
if (!upload(file, uploadPath, originalFileName)){
map.put("msg", "上传失败!");
return "forward:/index";
}
String realPath = uploadPath + "/" + originalFileName;
Mat srcImg = Imgcodecs.imread(realPath);
// 目标灰色图像
Mat dstGrayImg = new Mat();
// 转换灰色
Imgproc.cvtColor(srcImg, dstGrayImg, Imgproc.COLOR_BGR2GRAY);
// OpenCv人脸识别分类器
CascadeClassifier classifier = new CascadeClassifier(modelPath);
// 用来存放人脸矩形
MatOfRect faceRect = new MatOfRect();
// 特征检测点的最小尺寸
Size minSize = new Size(32, 32);
// 图像缩放比例,可以理解为相机的X倍镜
double scaleFactor = 1.2;
// 执行人脸检测
classifier.detectMultiScale(dstGrayImg, faceRect, scaleFactor, minneighbors, CV_HAAR_DO_CANNY_PRUNING, minSize);
//遍历矩形,画到原图上面
// 定义绘制颜色
Scalar color = new Scalar(0, 0, 255);
Rect[] rects = faceRect.toArray();
// 没检测到
if (null==rects || rects.length<1) {
// 显示图片
map.put("msg", "未检测到人脸");
// 文件名
map.put("fileName", originalFileName);
return "forward:/index";
}
// 逐个处理
for(Rect rect: rects) {
int x = rect.x;
int y = rect.y;
int w = rect.width;
int h = rect.height;
// 单独框出每一张人脸
Imgproc.rectangle(srcImg, new Point(x, y), new Point(x + w, y + w), color, 2);
}
// 添加人脸框之后的图片的名字
String newFileName = UUID.randomUUID().toString() + ".png";
// 保存
Imgcodecs.imwrite(uploadPath + "/" + newFileName, srcImg);
// 显示图片
map.put("msg", "一共检测到" + rects.length + "个人脸");
// 文件名
map.put("fileName", newFileName);
return "forward:/index";
}
/**
* 显示单张图片
* @return
*/
@RequestMapping("show")
public ResponseEntity showPhotos(String fileName){
if (null==fileName) {
return ResponseEntity.notFound().build();
}
try {
// 由于是读取本机的文件,file是一定要加上的, path是在application配置文件中的路径
return ResponseEntity.ok(resourceLoader.getResource("file:" + uploadPath + "/" + fileName));
} catch (Exception e) {
return ResponseEntity.notFound().build();
}
}
}
在静态方法中通过
System.loadLibrary加载本地库函,实际开发过程中,这里是最容易报错的地方,一定要确保-Djava.library.path参数配置的路径中的本地库是正常可用的,前文制作的基础镜像中已经准比好了这些本地库,因此只要确保-Djava.library.path参数配置正确即可,public String upload方法是处理人脸检测的代码入口,内部按照前面分析的流程顺序执行
new CascadeClassifier(modelPath)是根据指定的模型来实例化分类器,模型文件是从GitHub下载的,opencv官方提前训练好的模型,地址是:https://github.com/opencv/opencv/tree/master/data/haarcascades
看似神奇的人脸检测功能,实际上只需一行代码classifier.detectMultiScale,就能得到每个人脸在原图中的矩形位置,接下来,只需要按照位置在原图上添加矩形框即可。

若有收获,就点个赞吧
0 人点赞
