手写数字识别
功能简介
手写数字识别是指给定一系列的手写数字图片以及对应的数字标签,构建模型进行学习,目标是对于一张新的手写数字图片能够自动识别出对应的数字。图像识别是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对像的技术。机器学习领域一般将此类识别问题转化为分类问题。
阿拉伯数字作为唯一被世界各国通用的符号,所以对手写体数字识别的研究基本.上与文化背景无关,各地的研究工作者可以说是基于同一-平台开展工作的,有利于研究的比较和探讨。
手写数字识别应用广泛,如税表系统,银行支票自动处理和邮政编码自动识别等。在以前,这些工作需要大量的手工录入,投入的人力物力都相对较多,而且劳动强度较大。为了适应无纸化办公的需要,大大提高工作效率,研究实现手写数字识别系统是必须要做的。
由于数字类别只有0-9共10个,比其他字符识别率较高,可将其用于验证新的理论或做深入的分析研究。许多机器学习和模式识别领域的新理论和算法都是先用手写数字识别进行检验,验证其理论的有效性,然后才会将其应用到更为复杂的领域当中。在这方面的典型例子就是人工神经网络和支持向量机。
技术流程
数据处理
图像数据是经过归一化,展示前需要缩放回原始数据。(反归一化)因为图像的数据集为了方便模型的训练,做过归一化的,想让展现出来的数据使人们看的顺眼,做反归一化
模型设计
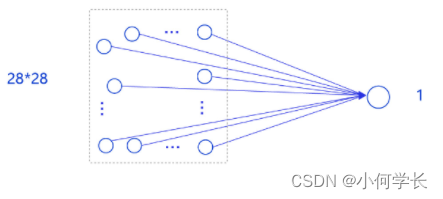
事实上,采用只有一层的简单网络(对输入求加权和)时并没有处理位置关系信息,因此可以猜测出此模型的预测效果可能有限。
训练配置
训练配置需要先生成模型实例(设为“训练”状态),再设置优化算法和学习率(使用随机梯度下降SGD,学习率设置为0.001)
训练过程
训练过程采用二层循环嵌套方式,训练完成后需要保存模型参数,以便后续使用。
内层循环:负责整个数据集的一次遍历,遍历数据集采用分批次(batch)方式。
外层循环:定义遍历数据集的次数,本次训练中外层循环10次,通过参数EPOCH_NUM设置。
配置优化器:SGD Optimizer
模型测试
模型测试的主要目的是验证训练好的模型是否能正确识别出数字,包括如下四步:
- 声明实例
- 加载模型:加载训练过程中保存的模型参数,
- 灌入数据:将测试样本传入模型,模型的状态设置为校验状态(eval),显式告诉框架我们接下来只会使用前向计算的流程,不会计算梯度和梯度反向传播。
- 获取预测结果,取整后作为预测标签输出。
在模型测试之前,需要先从文件中读取样例图片,并进行归一化处理。最后从打印结果来看,模型预测出的数字是与实际输出的图片的数字是否一致。
功能实现
MNIST简介
MNIST是经典的计算机视觉数据集,来源是National Institute of Standards and Technology (NIST,美国国家标准与技术研究所),包含各种手写数字图片,其中训练集60,000张,测试集 10,000张,MNIST来源于250 个不同人的手写,其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员.,测试集(test set) 也是同样比例的手写数字数据
MNIST官网:http://yann.lecun.com/exdb/mnist/
数字的预处理
在手写数字图像识别系统中,图像的预处理跟一般图像系统不同,我们不需要对图像进行灰度化处理、去噪处理等基本操作,我们利用程序保存的坐标值就可以对生成一张二值化图像,相当于图像处理系统的二值化处理。
将画布内容转化成base64,构建一个json格式的数据,将图片提交到后端(Base64编码是从二进制到字符的过程,可用于在HTTP环境下传递较长的标识信息。采用Base64编码具有不可读性,需要解码后才能阅读)
数字的识别
识别过程就是输入的模型得到输出,具体过程就是首先cnn提取特征,再将特征输入到全连接层,概率是神经网络的输出,因为数字有10个,所以是10分类问题,网络就会输出10个logits,10个logits经过softmax()就得到了概率。
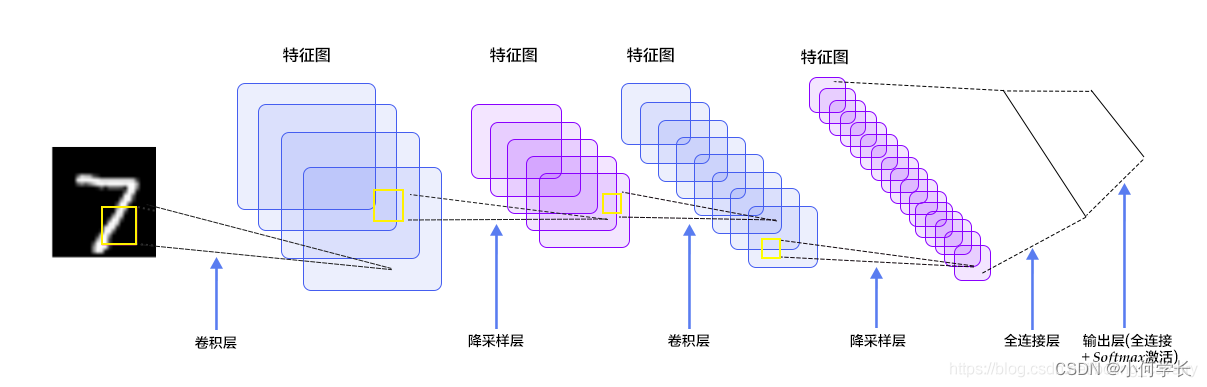
按照上图简单分析一下,用于指导接下来的开发:
每张图片都是28*28的单通道,矩阵应该是[1, 28,28]
C1是卷积层,所用卷积核尺寸5*5,滑动步长1,卷积核数目20,所以尺寸变化是:28-5+1=24(想象为宽度为5的窗口在宽度为28的窗口内滑动,能滑多少次),输出矩阵是[20,24,24]
S2是池化层,核尺寸2*2,步长2,类型是MAX,池化操作后尺寸减半,变成了[20,12,12]
C3是卷积层,所用卷积核尺寸5*5,滑动步长1,卷积核数目50,所以尺寸变化是:12-5+1=8,输出矩阵[50,8,8]
S4是池化层,核尺寸2*2,步长2,类型是MAX,池化操作后尺寸减半,变成了[50,4,4]
C5是全连接层(FC),神经元数目500,接relu激活函数
最后是全连接层Output,共10个节点,代表数字0到9,激活函数是softmax
核心代码
使用Vue书写前端交互界面
安装画板
npm install vue-esign --save
导入插件使用
import vueEsign from 'vue-esign'
Vue.use(vueEsign)
页面基本设置
<vue-esign ref="esign" :width="800" :height="300" :isCrop="isCrop" :lineWidth="lineWidth" :lineColor="lineColor" :bgColor.sync="bgColor" />
<button @click="handleReset">清空画板</button>
<button @click="handleGenerate">生成图片</button>
基本数据和方法
data () {
return {
lineWidth: 6,
lineColor: '#000000',
bgColor: '',
resultImg: '',
isCrop: false
}
},
methods: {
handleReset () {
this.$refs['esign'].reset() //清空画布
// 要更改成训练集的样式,还需做处理,详见我的代码
},
handleGenerate () {
this.$refs['esign'].generate().then(res => {
this.resultImg = res // 得到了签字生成的base64图片
}).catch(err => { // 没有签名,点击生成图片时调用
this.$message({
message: err + ' 未签名!',
type: 'warning'
})
alert(err) // 画布没有签字时会执行这里 'Not Signned'
})
}
}
将base64,转换成图片
base64ImgtoFile(dataurl, filename = 'file') {
const arr = dataurl.split(',')
const mime = arr[0].match(/:(.*?);/)[1]
const suffix = mime.split('/')[1]
const bstr = atob(arr[1])
let n = bstr.length
const u8arr = new Uint8Array(n)
while (n--) {
u8arr[n] = bstr.charCodeAt(n)
}
return new File([u8arr], `${filename}.${suffix}`, {
type: mime
})
},
后端实现训练得到数据
训练模型的过程是让DeepLearning去发现一个函数,我们需要描述这个函数长什么样。
首先,我们会定义这个模型的输入和输出。
- 图像大小为28x28,因为是灰度图,每个像素点只有黑白两种状态。用一个标识来描述处于某种状态,则模型的输入为一个大小为28x28的一维数组。预期的输出为数字识别,所以结果为0-9共10个数字,可以认为输出是一个大小为10的一维数组。
byte[10] recognition(byte[28*28] img);
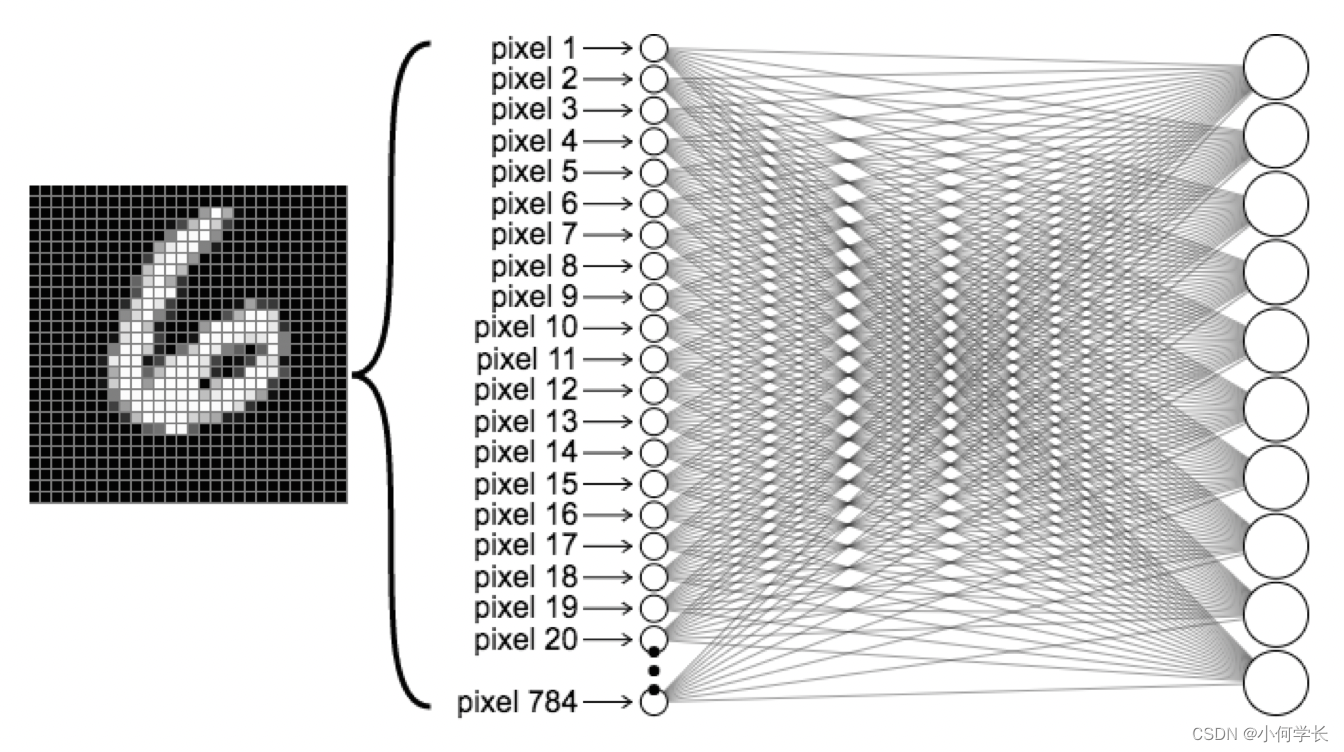
因为不知道如何描述这个映射关系,所以我们采用了另一种方式: 并不定义实现,而是拿一些已有数据,让模型自己总结其中的规律。比如,输入一个数字6的图片,告诉模型这张图片最终会映射为6。也就是说我们的输入包括两部分图像本身(Data)和表示的内容6(Label)。在模型训练的过程中需要使用大量的数据(Data+Label),这一批数据称之为数据集(Dataset)。而数据集因为作用不同,又会被划分为
- 训练集
- 验证集
- 测试集
这3个概念非常符合我们的学习过程
- 训练集: 课堂教学。老师上课时为了描述1+1=2时,举的例子1个苹果+一个苹果,最终拿到2个苹果。
- 验证集: 课后作业。看一下学生的掌握情况,决定下一步的教学。同时为了避免学生过分背题(这还有一个高大上的名字叫做”过拟合”),导致只知道苹果+苹果,而不知道香蕉+香蕉。
- 测试集: 期末考试。为判断学生是否真正掌握了知识,用上课时未出现的题目进行测试。
神经网络
模型自己总结映射关系,可以认为是学习的概念,那深度的概念如何体现呢?经过实验发现,如果在输入、输出之间增加一些层(layer)进行映射,会得到更好的效果。增加的这些层被称为Hidden Layers,深度也就是指Hidden Layers的层数。
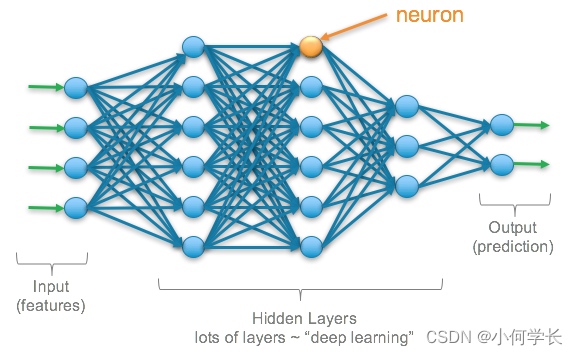
那么多少层会得到最好的效果呢?随缘吧。
并没有公式可以指导我们建立多少层,只能通过实验结果反证在什么样的layer可以获得好的效果。
通过djl来帮助我们完成模型训练及使用
<dependency>
<groupId>ai.djl</groupId>
<artifactId>api</artifactId>
<version>${djl.version}</version>
</dependency>
Dataset
在数据制备阶段,通过图像Data的名称来描述Label,并放到相关文件目录下。
扫描文件目录进行加载,并提供Data+Label的获取方式
public class MnistDataset extends RandomAccessDataset {
@Override
public void prepare(Progress progress) throws IOException {
if (prepared) {
return;
}
try (Stream<Path> paths = Files.walk(path)) {
items = paths.map(p -> p.toFile().getName())
.filter(n -> n.endsWith(".png"))
.distinct()
.collect(Collectors.toList());
}
prepared = true;
}
@Override
protected long availableSize() {
return items.size();
}
@Override
public Record get(NDManager manager, long index) {
String item = items.get(Math.toIntExact(index));
Path imagePath = Paths.get(path.toString(), item);
NDArray imageArray = null;
try {
imageArray = ImageFactory.getInstance()
.fromFile(imagePath)
.toNDArray(manager, Image.Flag.GRAYSCALE);
} catch (IOException e) {
e.printStackTrace();
}
NDList data = new NDList(imageArray);
NDList labels = new NDList(1);
labels.add(manager.create(Integer.parseInt(item.split("_")[0])));
return new Record(data, labels);
}
}
Train
按照输入输出,并设置2层hidden layers构成Block,将数据集以每次一张图片(Shape)的方式进行计算。
public TrainingResult train(Arguments arguments) throws IOException, TranslateException {
if (arguments == null) {
return null;
}
// Construct neural network
Block block = new Mlp(28 * 28, 10, new int[]{128, 64});
try (Model model = Model.newInstance("first")) {
model.setBlock(block);
// get training and validation dataset
RandomAccessDataset trainingSet = getDataset(Dataset.Usage.TRAIN, arguments);
RandomAccessDataset validateSet = getDataset(Dataset.Usage.TEST, arguments);
// setup training configuration
DefaultTrainingConfig config = setupTrainingConfig(arguments);
try (Trainer trainer = model.newTrainer(config)) {
trainer.setMetrics(new Metrics());
/*
* MNIST is 28x28 grayscale image and pre processed into 28 * 28 NDArray.
* 1st axis is batch axis, we can use 1 for initialization.
*/
Shape inputShape = new Shape(1, Mnist.IMAGE_HEIGHT * Mnist.IMAGE_WIDTH);
// initialize trainer with proper input shape
trainer.initialize(inputShape);
EasyTrain.fit(trainer, arguments.getEpoch(), trainingSet, validateSet);
return trainer.getTrainingResult();
}
}
}
private DefaultTrainingConfig setupTrainingConfig(Arguments arguments) {
String outputDir = arguments.getOutputDir();
SaveModelTrainingListener listener = new SaveModelTrainingListener(outputDir);
listener.setSaveModelCallback(
trainer -> {
TrainingResult result = trainer.getTrainingResult();
Model model = trainer.getModel();
float accuracy = result.getValidateEvaluation("Accuracy");
model.setProperty("Accuracy", String.format("%.5f", accuracy));
model.setProperty("Loss", String.format("%.5f", result.getValidateLoss()));
});
return new DefaultTrainingConfig(Loss.softmaxCrossEntropyLoss())
.addEvaluator(new Accuracy())
.optDevices(Device.getDevices(arguments.getMaxGpus()))
.addTrainingListeners(TrainingListener.Defaults.logging(outputDir))
.addTrainingListeners(listener);
}
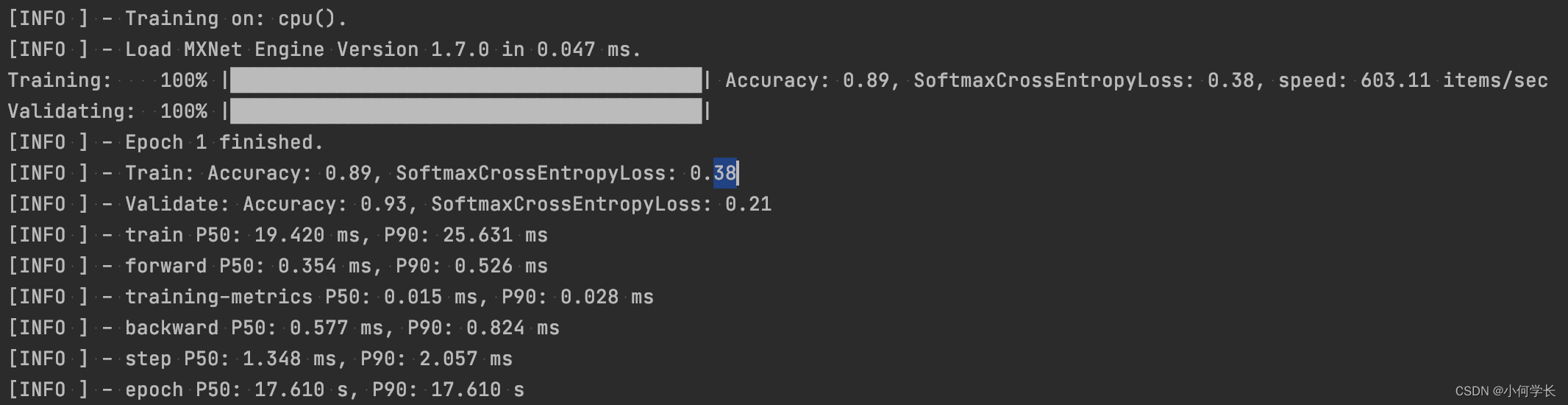
在性能检测中有一个Accuracy指标,表示的意思是 正确的数量/总数量 , 但是不能只依赖这个指标作为模型性能的判断。
inference
使用模型时,需要设定同样的Block,图像经过映射后会得到一个结果,但是并不会得到唯一解,而是获取多个结果及可能性比例。可以选择获取best
public static Integer recognition(Image img) throws IOException, TranslateException, MalformedModelException {
Model model = Model.newInstance("first");
Path modelDir = Paths.get("build/model");
Predictor<Image, Classifications> predictor = null;
Block block = new Mlp(28 * 28, 10, new int[]{128, 64});
try {
model.setBlock(block);
model.load(modelDir);
List<String> classes = IntStream.range(0, 10).mapToObj(String::valueOf).collect(Collectors.toList());
Pipeline pipeline = new Pipeline();
pipeline.add(new Resize(28, 28))
.add(new ToTensor());
Translator<Image, Classifications> translator =
ImageClassificationTranslator.builder()
.setPipeline(pipeline)
.optSynset(classes)
.build();
predictor = model.newPredictor(translator);
Classifications classifications = predictor.predict(img);
return Integer.parseInt(classifications.best().getClassName());
} catch (MalformedModelException e) {
log.error("model inference error! image:{}", img, e);
throw e;
} catch (TranslateException e) {
log.error("translate error! image:{}", img, e);
throw e;
} finally {
model.close();
if (null != predictor) {
predictor.close();
}
}
}
优化算法
这里参考到了别的博主的训练代码,自己没有拿过来进行对比,后期有时间,可拿来借鉴进行对比优化
参考文章链接:https://xinchen.blog.csdn.net/article/details/118239403
训练模型代码优化
package com.bolingcavalry.convolution;
import lombok.extern.slf4j.Slf4j;
import org.datavec.api.io.labels.ParentPathLabelGenerator;
import org.datavec.api.split.FileSplit;
import org.datavec.image.loader.NativeImageLoader;
import org.datavec.image.recordreader.ImageRecordReader;
import org.deeplearning4j.datasets.datavec.RecordReaderDataSetIterator;
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.inputs.InputType;
import org.deeplearning4j.nn.conf.layers.ConvolutionLayer;
import org.deeplearning4j.nn.conf.layers.DenseLayer;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.conf.layers.SubsamplingLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.deeplearning4j.util.ModelSerializer;
import org.nd4j.evaluation.classification.Evaluation;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.dataset.api.preprocessor.DataNormalization;
import org.nd4j.linalg.dataset.api.preprocessor.ImagePreProcessingScaler;
import org.nd4j.linalg.learning.config.Nesterovs;
import org.nd4j.linalg.lossfunctions.LossFunctions;
import org.nd4j.linalg.schedule.MapSchedule;
import org.nd4j.linalg.schedule.ScheduleType;
import java.io.File;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
@Slf4j
public class LeNetMNISTReLu {
// 存放文件的地址,请酌情修改
// private static final String BASE_PATH = System.getProperty("java.io.tmpdir") + "/mnist";
private static final String BASE_PATH = "E:\\temp\\202106\\26";
public static void main(String[] args) throws Exception {
// 图片像素高
int height = 28;
// 图片像素宽
int width = 28;
// 因为是黑白图像,所以颜色通道只有一个
int channels = 1;
// 分类结果,0-9,共十种数字
int outputNum = 10;
// 批大小
int batchSize = 54;
// 循环次数
int nEpochs = 1;
// 初始化伪随机数的种子
int seed = 1234;
// 随机数工具
Random randNumGen = new Random(seed);
log.info("检查数据集文件夹是否存在:{}", BASE_PATH + "/mnist_png");
if (!new File(BASE_PATH + "/mnist_png").exists()) {
log.info("数据集文件不存在,请下载压缩包并解压到:{}", BASE_PATH);
return;
}
// 标签生成器,将指定文件的父目录作为标签
ParentPathLabelGenerator labelMaker = new ParentPathLabelGenerator();
// 归一化配置(像素值从0-255变为0-1)
DataNormalization imageScaler = new ImagePreProcessingScaler();
// 不论训练集还是测试集,初始化操作都是相同套路:
// 1. 读取图片,数据格式为NCHW
// 2. 根据批大小创建的迭代器
// 3. 将归一化器作为预处理器
log.info("训练集的矢量化操作...");
// 初始化训练集
File trainData = new File(BASE_PATH + "/mnist_png/training");
FileSplit trainSplit = new FileSplit(trainData, NativeImageLoader.ALLOWED_FORMATS, randNumGen);
ImageRecordReader trainRR = new ImageRecordReader(height, width, channels, labelMaker);
trainRR.initialize(trainSplit);
DataSetIterator trainIter = new RecordReaderDataSetIterator(trainRR, batchSize, 1, outputNum);
// 拟合数据(实现类中实际上什么也没做)
imageScaler.fit(trainIter);
trainIter.setPreProcessor(imageScaler);
log.info("测试集的矢量化操作...");
// 初始化测试集,与前面的训练集操作类似
File testData = new File(BASE_PATH + "/mnist_png/testing");
FileSplit testSplit = new FileSplit(testData, NativeImageLoader.ALLOWED_FORMATS, randNumGen);
ImageRecordReader testRR = new ImageRecordReader(height, width, channels, labelMaker);
testRR.initialize(testSplit);
DataSetIterator testIter = new RecordReaderDataSetIterator(testRR, batchSize, 1, outputNum);
testIter.setPreProcessor(imageScaler); // same normalization for better results
log.info("配置神经网络");
// 在训练中,将学习率配置为随着迭代阶梯性下降
Map<Integer, Double> learningRateSchedule = new HashMap<>();
learningRateSchedule.put(0, 0.06);
learningRateSchedule.put(200, 0.05);
learningRateSchedule.put(600, 0.028);
learningRateSchedule.put(800, 0.0060);
learningRateSchedule.put(1000, 0.001);
// 超参数
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(seed)
// L2正则化系数
.l2(0.0005)
// 梯度下降的学习率设置
.updater(new Nesterovs(new MapSchedule(ScheduleType.ITERATION, learningRateSchedule)))
// 权重初始化
.weightInit(WeightInit.XAVIER)
// 准备分层
.list()
// 卷积层
.layer(new ConvolutionLayer.Builder(5, 5)
.nIn(channels)
.stride(1, 1)
.nOut(20)
.activation(Activation.IDENTITY)
.build())
// 下采样,即池化
.layer(new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2, 2)
.stride(2, 2)
.build())
// 卷积层
.layer(new ConvolutionLayer.Builder(5, 5)
.stride(1, 1) // nIn need not specified in later layers
.nOut(50)
.activation(Activation.IDENTITY)
.build())
// 下采样,即池化
.layer(new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2, 2)
.stride(2, 2)
.build())
// 稠密层,即全连接
.layer(new DenseLayer.Builder().activation(Activation.RELU)
.nOut(500)
.build())
// 输出
.layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nOut(outputNum)
.activation(Activation.SOFTMAX)
.build())
.setInputType(InputType.convolutionalFlat(height, width, channels)) // InputType.convolutional for normal image
.build();
MultiLayerNetwork net = new MultiLayerNetwork(conf);
net.init();
// 每十个迭代打印一次损失函数值
net.setListeners(new ScoreIterationListener(10));
log.info("神经网络共[{}]个参数", net.numParams());
long startTime = System.currentTimeMillis();
// 循环操作
for (int i = 0; i < nEpochs; i++) {
log.info("第[{}]个循环", i);
net.fit(trainIter);
Evaluation eval = net.evaluate(testIter);
log.info(eval.stats());
trainIter.reset();
testIter.reset();
}
log.info("完成训练和测试,耗时[{}]毫秒", System.currentTimeMillis()-startTime);
// 保存模型
File ministModelPath = new File(BASE_PATH + "/minist-model.zip");
ModelSerializer.writeModel(net, ministModelPath, true);
log.info("最新的MINIST模型保存在[{}]", ministModelPath.getPath());
}
}
以上代码的训练结果
21:19:15.355 [main] INFO org.deeplearning4j.optimize.listeners.ScoreIterationListener - Score at iteration 1110 is 0.18300625613640034
21:19:15.365 [main] DEBUG org.nd4j.linalg.dataset.AsyncDataSetIterator - Manually destroying ADSI workspace
21:19:16.632 [main] DEBUG org.nd4j.linalg.dataset.AsyncDataSetIterator - Manually destroying ADSI workspace
21:19:16.642 [main] INFO com.bolingcavalry.convolution.LeNetMNISTReLu -
========================Evaluation Metrics========================
# of classes: 10
Accuracy: 0.9886
Precision: 0.9885
Recall: 0.9886
F1 Score: 0.9885
Precision, recall & F1: macro-averaged (equally weighted avg. of 10 classes)
=========================Confusion Matrix=========================
0 1 2 3 4 5 6 7 8 9
---------------------------------------------------
972 0 0 0 0 0 2 2 2 2 | 0 = 0
0 1126 0 3 0 2 1 1 2 0 | 1 = 1
1 1 1019 2 0 0 0 6 3 0 | 2 = 2
0 0 1 1002 0 5 0 1 1 0 | 3 = 3
0 0 2 0 971 0 3 2 1 3 | 4 = 4
0 0 0 3 0 886 2 1 0 0 | 5 = 5
6 2 0 1 1 5 942 0 1 0 | 6 = 6
0 1 6 0 0 0 0 1015 1 5 | 7 = 7
1 0 1 1 0 2 0 2 962 5 | 8 = 8
1 2 1 3 5 3 0 2 1 991 | 9 = 9
Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times
==================================================================
21:19:16.643 [main] INFO com.bolingcavalry.convolution.LeNetMNISTReLu - 完成训练和测试,耗时[27467]毫秒
21:19:17.019 [main] INFO com.bolingcavalry.convolution.LeNetMNISTReLu - 最新的MINIST模型保存在
Process finished with exit code 0
作者表示:前面的测试结果显示准确率为0.9886,这是1.0.0-beta6版本DL4J的训练结果,如果换成1.0.0-beta7,准确率可以达到0.99以上,大家可以尝试一下。
后端应用代码优化
参考文章链接:https://xinchen.blog.csdn.net/article/details/118353259
SpringBoot应用设计(流程设计)
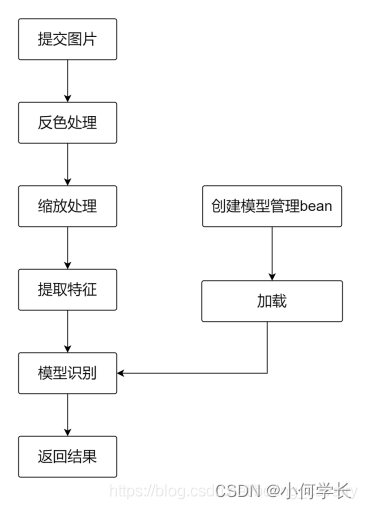
- 如果用户输入的是黑底白字的图片,只需要将上述流程中的反色处理去掉即可
- 为白底黑字图片提供专用接口predict-with-white-background
- 为黑底白字图片提供专用接口predict-with-black-background
- 将处理图片所需的静态方法集中在ImageFileUtil.java的文件中,主要是save(存到磁盘上)、resize(缩放)、colorRevert(反色)、clear(清理)、getGrayImageFeatures(提取特征,操作和训练时的是一样的):
package com.bolingcavalry.commons.utils;
import lombok.extern.slf4j.Slf4j;
import org.datavec.api.split.FileSplit;
import org.datavec.image.loader.NativeImageLoader;
import org.datavec.image.recordreader.ImageRecordReader;
import org.deeplearning4j.datasets.datavec.RecordReaderDataSetIterator;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.dataset.api.preprocessor.ImagePreProcessingScaler;
import org.springframework.web.multipart.MultipartFile;
import javax.imageio.ImageIO;
import java.awt.*;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.UUID;
@Slf4j
public class ImageFileUtil {
/**
* 调整后的文件宽度
*/
public static final int RESIZE_WIDTH = 28;
/**
* 调整后的文件高度
*/
public static final int RESIZE_HEIGHT = 28;
/**
* 将上传的文件存在服务器上
* @param base 要处理的文件所在的目录
* @param file 要处理的文件
* @return
*/
public static String save(String base, MultipartFile file) {
// 检查是否为空
if (file.isEmpty()) {
log.error("invalid file");
return null;
}
// 文件名来自原始文件
String fileName = file.getOriginalFilename();
// 要保存的位置
File dest = new File(base + fileName);
// 开始保存
try {
file.transferTo(dest);
} catch (IOException e) {
log.error("upload fail", e);
return null;
}
return fileName;
}
/**
* 将图片转为28*28像素
* @param base 处理文件的目录
* @param fileName 待调整的文件名
* @return
*/
public static String resize(String base, String fileName) {
// 新文件名是原文件名在加个随机数后缀,而且扩展名固定为png
String resizeFileName = fileName.substring(0, fileName.lastIndexOf(".")) + "-" + UUID.randomUUID() + ".png";
log.info("start resize, from [{}] to [{}]", fileName, resizeFileName);
try {
// 读原始文件
BufferedImage bufferedImage = ImageIO.read(new File(base + fileName));
// 缩放后的实例
Image image = bufferedImage.getScaledInstance(RESIZE_WIDTH, RESIZE_HEIGHT, Image.SCALE_SMOOTH);
BufferedImage resizeBufferedImage = new BufferedImage(28, 28, BufferedImage.TYPE_INT_RGB);
Graphics graphics = resizeBufferedImage.getGraphics();
// 绘图
graphics.drawImage(image, 0, 0, null);
graphics.dispose();
// 转换后的图片写文件
ImageIO.write(resizeBufferedImage, "png", new File(base + resizeFileName));
} catch (Exception exception) {
log.info("resize error from [{}] to [{}], {}", fileName, resizeFileName, exception);
resizeFileName = null;
}
log.info("finish resize, from [{}] to [{}]", fileName, resizeFileName);
return resizeFileName;
}
/**
* 将RGB转为int数字
* @param alpha
* @param red
* @param green
* @param blue
* @return
*/
private static int colorToRGB(int alpha, int red, int green, int blue) {
int pixel = 0;
pixel += alpha;
pixel = pixel << 8;
pixel += red;
pixel = pixel << 8;
pixel += green;
pixel = pixel << 8;
pixel += blue;
return pixel;
}
/**
* 反色处理
* @param base 处理文件的目录
* @param src 用于处理的源文件
* @return 反色处理后的新文件
* @throws IOException
*/
public static String colorRevert(String base, String src) throws IOException {
int color, r, g, b, pixel;
// 读原始文件
BufferedImage srcImage = ImageIO.read(new File(base + src));
// 修改后的文件
BufferedImage destImage = new BufferedImage(srcImage.getWidth(), srcImage.getHeight(), srcImage.getType());
for (int i=0; i<srcImage.getWidth(); i++) {
for (int j=0; j<srcImage.getHeight(); j++) {
color = srcImage.getRGB(i, j);
r = (color >> 16) & 0xff;
g = (color >> 8) & 0xff;
b = color & 0xff;
pixel = colorToRGB(255, 0xff - r, 0xff - g, 0xff - b);
destImage.setRGB(i, j, pixel);
}
}
// 反射文件的名字
String revertFileName = src.substring(0, src.lastIndexOf(".")) + "-revert.png";
// 转换后的图片写文件
ImageIO.write(destImage, "png", new File(base + revertFileName));
return revertFileName;
}
/**
* 取黑白图片的特征
* @param base
* @param fileName
* @return
* @throws Exception
*/
public static INDArray getGrayImageFeatures(String base, String fileName) throws Exception {
log.info("start getImageFeatures [{}]", base + fileName);
// 和训练模型时一样的设置
ImageRecordReader imageRecordReader = new ImageRecordReader(RESIZE_HEIGHT, RESIZE_WIDTH, 1);
FileSplit fileSplit = new FileSplit(new File(base + fileName),
NativeImageLoader.ALLOWED_FORMATS);
imageRecordReader.initialize(fileSplit);
DataSetIterator dataSetIterator = new RecordReaderDataSetIterator(imageRecordReader, 1);
dataSetIterator.setPreProcessor(new ImagePreProcessingScaler(0, 1));
// 取特征
return dataSetIterator.next().getFeatures();
}
/**
* 批量清理文件
* @param base 处理文件的目录
* @param fileNames 待清理文件集合
*/
public static void clear(String base, String...fileNames) {
for (String fileName : fileNames) {
if (null==fileName) {
continue;
}
File file = new File(base + fileName);
if (file.exists()) {
file.delete();
}
}
}
}
- 定义service层,只有一个方法,可以通过入参决定是否做反色处理:
package com.bolingcavalry.predictnumber.service;
import org.springframework.web.multipart.MultipartFile;
public interface PredictService {
/**
* 取得上传的图片,做转换后识别成数字
* @param file 上传的文件
* @param isNeedRevert 是否要做反色处理
* @return
*/
int predict(MultipartFile file, boolean isNeedRevert) throws Exception ;
}
- sevice层的实现,也是核心代码
package com.bolingcavalry.predictnumber.service.impl;
import com.bolingcavalry.commons.utils.ImageFileUtil;
import com.bolingcavalry.predictnumber.service.PredictService;
import lombok.extern.slf4j.Slf4j;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.util.ModelSerializer;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import javax.annotation.PostConstruct;
import java.io.File;
@Service
@Slf4j
public class PredictServiceImpl implements PredictService {
/**
* -1表示识别失败
*/
private static final int RLT_INVALID = -1;
/**
* 模型文件的位置
*/
@Value("${predict.modelpath}")
private String modelPath;
/**
* 处理图片文件的目录
*/
@Value("${predict.imagefilepath}")
private String imageFilePath;
/**
* 神经网络
*/
private MultiLayerNetwork net;
/**
* bean实例化成功就加载模型
*/
@PostConstruct
private void loadModel() {
log.info("load model from [{}]", modelPath);
// 加载模型
try {
net = ModelSerializer.restoreMultiLayerNetwork(new File(modelPath));
log.info("module summary\n{}", net.summary());
} catch (Exception exception) {
log.error("loadModel error", exception);
}
}
@Override
public int predict(MultipartFile file, boolean isNeedRevert) throws Exception {
log.info("start predict, file [{}], isNeedRevert [{}]", file.getOriginalFilename(), isNeedRevert);
// 先存文件
String rawFileName = ImageFileUtil.save(imageFilePath, file);
if (null==rawFileName) {
return RLT_INVALID;
}
// 反色处理后的文件名
String revertFileName = null;
// 调整大小后的文件名
String resizeFileName;
// 是否需要反色处理
if (isNeedRevert) {
// 把原始文件做反色处理,返回结果是反色处理后的新文件
revertFileName = ImageFileUtil.colorRevert(imageFilePath, rawFileName);
// 把反色处理后调整为28*28大小的文件
resizeFileName = ImageFileUtil.resize(imageFilePath, revertFileName);
} else {
// 直接把原始文件调整为28*28大小的文件
resizeFileName = ImageFileUtil.resize(imageFilePath, rawFileName);
}
// 现在已经得到了结果反色和调整大小处理过后的文件,
// 那么原始文件和反色处理过的文件就可以删除了
ImageFileUtil.clear(imageFilePath, rawFileName, revertFileName);
// 取出该黑白图片的特征
INDArray features = ImageFileUtil.getGrayImageFeatures(imageFilePath, resizeFileName);
// 将特征传给模型去识别
return net.predict(features)[0];
}
}
- 上述代码中,有两需要注意:
- loadModel方法在bean初始化时会执行,里面通过ModelSerializer.restoreMultiLayerNetwork完成模型文件加载
- 真正的识别操作其实就是MultiLayerNetwork.predict方法,一步而已,非常简单
- 然后是web接口层,对外提供两个接口:
package com.bolingcavalry.predictnumber.controller;
import com.bolingcavalry.predictnumber.service.PredictService;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
@RestController
public class PredictController {
final PredictService predictService;
public PredictController(PredictService predictService) {
this.predictService = predictService;
}
@PostMapping("/predict-with-black-background")
@ResponseBody
public int predictWithBlackBackground(@RequestParam("file") MultipartFile file) throws Exception {
// 训练模型的时候,用的数字是白字黑底,
// 因此如果上传白字黑底的图片,可以直接拿去识别,而无需反色处理
return predictService.predict(file, false);
}
@PostMapping("/predict-with-white-background")
@ResponseBody
public int predictWithWhiteBackground(@RequestParam("file") MultipartFile file) throws Exception {
// 训练模型的时候,用的数字是白字黑底,
// 因此如果上传黑字白底的图片,就需要做反色处理,
// 反色之后就是白字黑底了,可以拿去识别
return predictService.predict(file, true);
}
}

若有收获,就点个赞吧
0 人点赞
