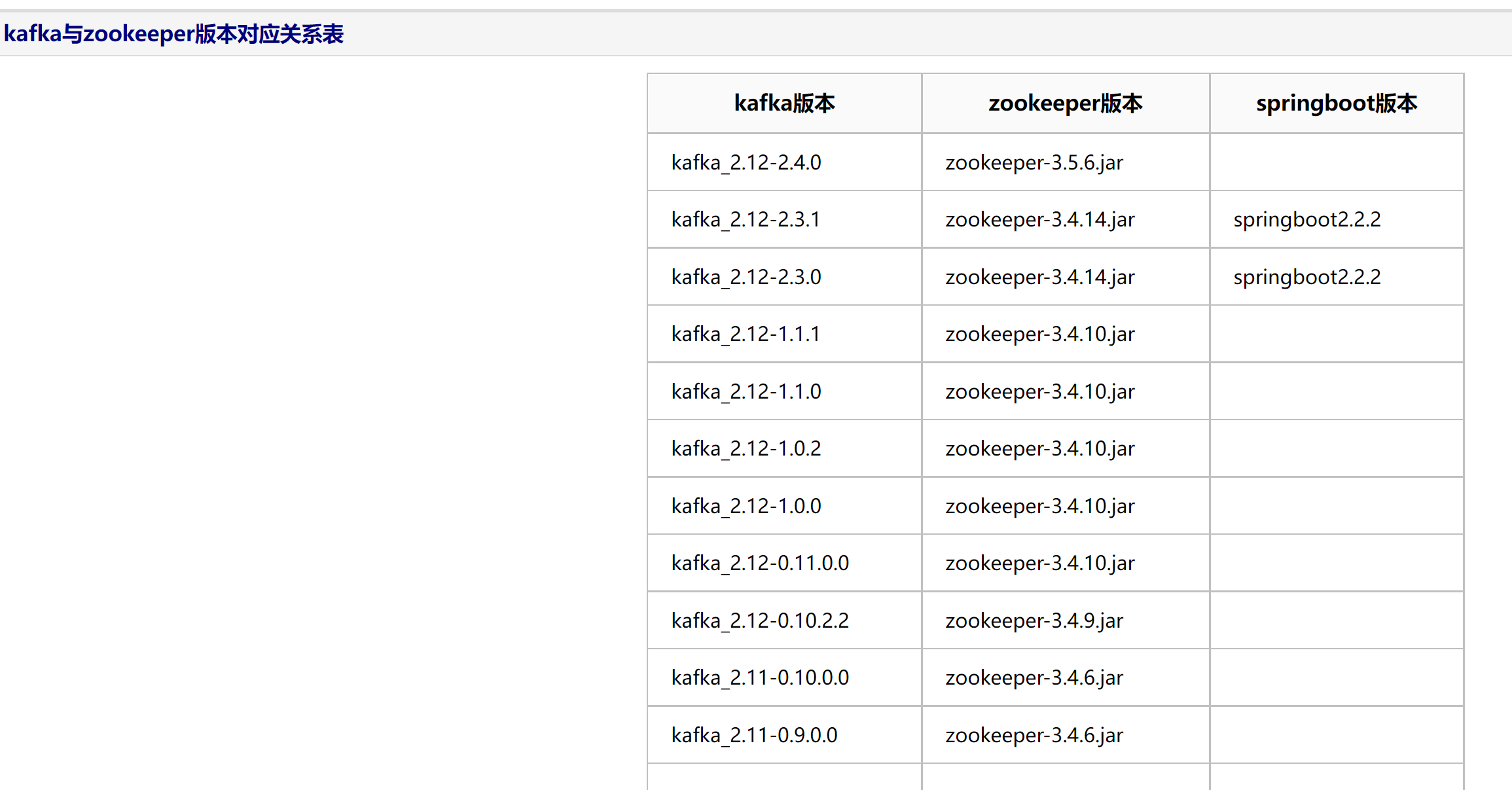
部署之前先明确好kafka和zookeeper之间得版本对应关系,kafka建议下载0.9版本之上得。下面开始部署
1、部署zookeeper
1、下载文件得地址
http://archive.apache.org/dist/zookeeper/。这里我们选择3.14得下载
2、启动虚拟机,部署单机版本得
1、启动虚拟机,把下载得包放进去,解压
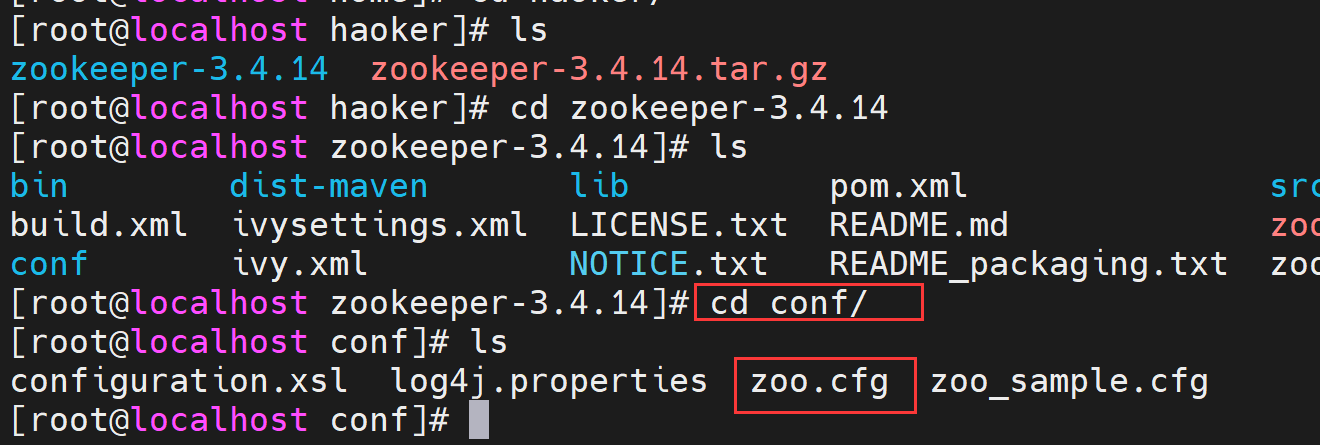
2、进入目录cofig中,新建文件zoo.cfg,然后把zoo_sample得内容复制过来。不新建zoo.cfg启动得时候会报错。新建完后,进入到bin文件启动:./zkServer.sh start
# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial# synchronization phase can takeinitLimit=10# The number of ticks that can pass between# sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.# do not use /tmp for storage, /tmp here is just# example sakes.dataDir=/tmp/zookeeper# the port at which the clients will connectclientPort=2181# the maximum number of client connections.# increase this if you need to handle more clients#maxClientCnxns=60## Be sure to read the maintenance section of the# administrator guide before turning on autopurge.## http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to "0" to disable auto purge feature#autopurge.purgeInterval=1


3、启动虚拟机,部署集群版本(三个节点)
1、克隆虚拟机配置,复制多两份,因为之前虚拟机配置了静态IP。复制后得静态IP地址需要修改下。具体静态IP修改方法可参考:
2、对解压完得zk,进入目录的conf目录下复制zoo_sample.cfg文件,为zoo.cfg文件(执行命令: cp zoo_sample.cfg zoo.cfg)。zoo.sample.cfg文件是官方所给的zk配置文件的demo,zk启动默认加载的是zoo.cfg文件。
重点关注属性:
clientPort:属性zk端口
dataDir:数据文件夹目录
dataLogDir:日志文件夹目录(不建议数据目录和日志目录在zk根目录下,如果数据量大会造成zk的严重的性能问题)。
集群环境中:
1、在dataDir文件夹下创建的myid文件,并写入标识1-n任意值(与第四步重复)。
2、需在zoo.cfg文件最后添加一下配置
#server.A=B:C:D:其中 A 数字,表示是第几号服务器. dataDir目录下必有一个myid文件,里面只存储A的值,ZK启动时读取此文件,与下面列表比较判断是哪个server# B 是服务器 ip ;C表示与 Leader 服务器交换信息的端口;D 表示的是进行选举时的通信端口。server.0=192.168.212.128:2888:3888server.1=192.168.212.130:2889:3889server.2=192.168.212.131:2890:3890
注意:单机只需要server.0即可。0是指在dataDir文件夹下创建的myid文件内容(在dataDir文件中执行:echo “1” >myid)
以下为zk的配置zoo.cfg详情(参数含义)描述
#间隔都是使用tickTime的倍数来表示的,例如initLimit=10就是tickTime的十倍等于2W毫秒tickTime=2000# The number of ticks that can pass between, sending a request and getting an acknowledgement# 心跳最大延迟时间,如果leader在规定的时间内无法获取到follow的心跳检测响应,则认为节点已脱离syncLimit=5# the directory where the snapshot is stored. do not use /tmp for storage, /tmp here is just. example sakes.# 用于存放内存数据库快照的文件夹,同时用于集群的myid文件也存在这个文件夹里dataDir=/home/haoker/zookeeper-3.4.14/data# the port at which the clients will connect,ZK端口clientPort=2181# the maximum number of client connections. increase this if you need to handle more clients# 允许连接的客户端数目,0-不限制,通过 IP 来区分不同的客户端maxClientCnxns=60#将管理机器把事务日志写入到“ dataLogDir ”所指定的目录,而不是“ dataDir ”所指定的目录。避免日志和快照之间的竞争dataLogDir=/home/haoker/zookeeper-3.4.14/data_log# The number of snapshots to retain in dataDir#用于配置zookeeper在自动清理的时候需要保留的快照数据文件数量和对应的事务日志文件,最小值时三,如果比3小,会自动调整为3#autopurge.snapRetainCount=3# Purge task interval in hours. Set to "0" to disable auto purge feature#配套snapRetainCount使用,用于配置zk进行历史文件自动清理的频率,如果参数配置为0或者小于零,就表示不开启定时清理功能,默认不开启#autopurge.purgeInterval=1##集群配置# The number of ticks that the initial, synchronization phase can take# follow服务器在启动的过程中会与leader服务器建立链接并完成对数据的同步,leader服务器允许follow在initLimit时间内完成,默认时10.集群量增大时#同步时间变长,有必要适当的调大这个参数, 当超过设置倍数的 tickTime 时间,则连接失败initLimit=10#server.A=B:C:D:其中 A 数字,表示是第几号服务器. dataDir目录下必有一个myid文件,里面只存储A的值,ZK启动时读取此文件,与下面列表比较判断是哪个server# B 是服务器 ip ;C表示与 Leader 服务器交换信息的端口;D 表示的是进行选举时的通信端口。server.0=192.168.212.128:2888:3888server.1=192.168.212.130:2889:3889server.2=192.168.212.131:2890:3890
第四步、创建dataDir文件下的主机标识文件myid,具体方法在第三步有描述。
第五步、在zk的bin目录下执行 ./zkServer.sh start-foreground启动zk,默认走的是zoo.cfg配置文件,也可以在启动命令上指定启动配置文件./zkServer.sh start zoo.cfg
验证是否启动成功
1、在zk的bin目录下执行./zkServer.sh status 查看启动状态Mode 有两个值 leader 和follower
2、使用工具连接
二、部署kafka
1、集群部署
1、下载安装包
1、http://archive.apache.org/dist/kafka/2.3.1/ 这里选择2.3.1得下载
2、下载完后,进行解压
2、复制三份kafka
scp -r root@192.168.212.128:/home/haoker/kafka_2.12-2.3.1.tgz /home/haoker/
3、进入config目录,然后修改server.properties配置文件
修改地址主要改这几块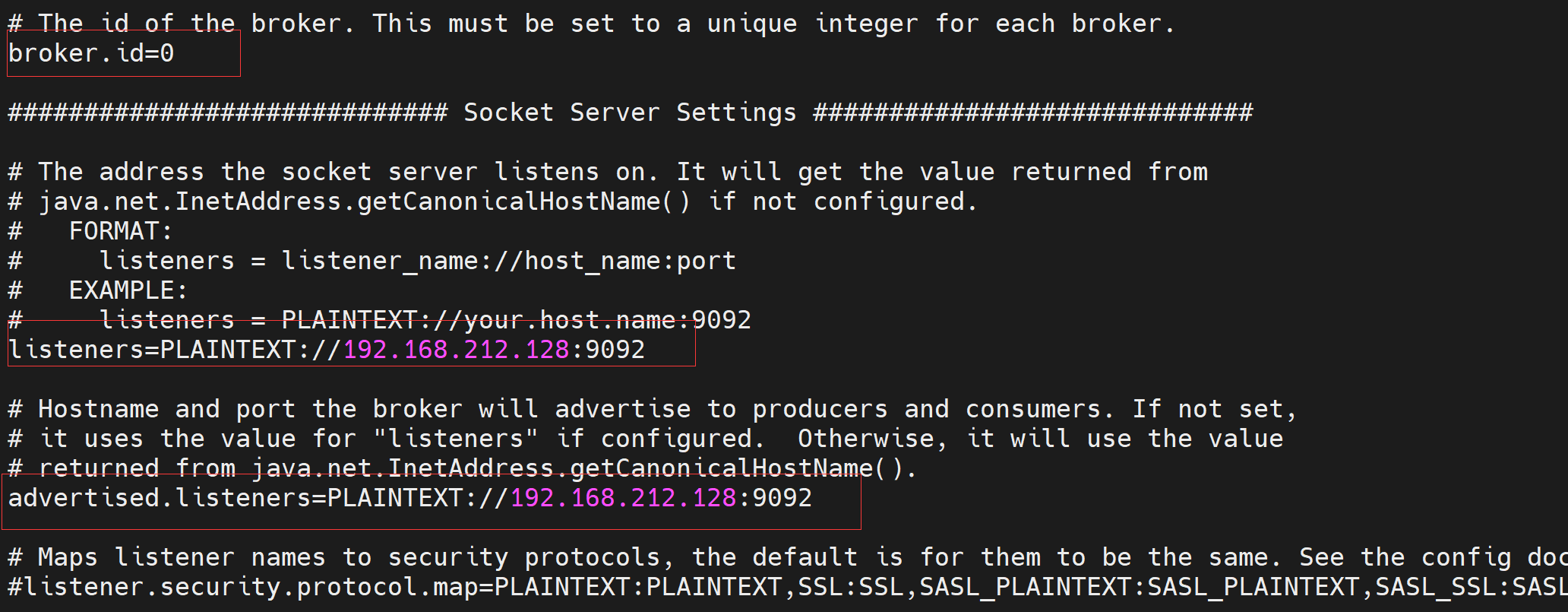

# The id of the broker. This must be set to a unique integer for each broker.broker.id=0############################# Socket Server Settings ############################## The address the socket server listens on. It will get the value returned from# java.net.InetAddress.getCanonicalHostName() if not configured.# FORMAT:# listeners = listener_name://host_name:port# EXAMPLE:# listeners = PLAINTEXT://your.host.name:9092listeners=PLAINTEXT://192.168.212.128:9092# Hostname and port the broker will advertise to producers and consumers. If not set,# it uses the value for "listeners" if configured. Otherwise, it will use the value# returned from java.net.InetAddress.getCanonicalHostName().advertised.listeners=PLAINTEXT://192.168.212.128:9092# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL# The number of threads that the server uses for receiving requests from the network and sending responses to the networknum.network.threads=3# The number of threads that the server uses for processing requests, which may include disk I/Onum.io.threads=8# The send buffer (SO_SNDBUF) used by the socket serversocket.send.buffer.bytes=102400# The receive buffer (SO_RCVBUF) used by the socket serversocket.receive.buffer.bytes=102400# The maximum size of a request that the socket server will accept (protection against OOM)socket.request.max.bytes=104857600############################# Log Basics ############################## A comma separated list of directories under which to store log fileslog.dirs=/home/haoker/kafka_2.12-2.3.1/data_log# The default number of log partitions per topic. More partitions allow greater# parallelism for consumption, but this will also result in more files across# the brokers.num.partitions=1# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.# This value is recommended to be increased for installations with data dirs located in RAID array.num.recovery.threads.per.data.dir=1############################# Internal Topic Settings ############################## The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"# For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.offsets.topic.replication.factor=1transaction.state.log.replication.factor=1transaction.state.log.min.isr=1############################# Log Flush Policy ############################## Messages are immediately written to the filesystem but by default we only fsync() to sync# the OS cache lazily. The following configurations control the flush of data to disk.# There are a few important trade-offs here:# 1. Durability: Unflushed data may be lost if you are not using replication.# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.# The settings below allow one to configure the flush policy to flush data after a period of time or# every N messages (or both). This can be done globally and overridden on a per-topic basis.# The number of messages to accept before forcing a flush of data to disk#log.flush.interval.messages=10000# The maximum amount of time a message can sit in a log before we force a flush#log.flush.interval.ms=1000############################# Log Retention Policy ############################## The following configurations control the disposal of log segments. The policy can# be set to delete segments after a period of time, or after a given size has accumulated.# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens# from the end of the log.# The minimum age of a log file to be eligible for deletion due to agelog.retention.hours=168# A size-based retention policy for logs. Segments are pruned from the log unless the remaining# segments drop below log.retention.bytes. Functions independently of log.retention.hours.#log.retention.bytes=1073741824# The maximum size of a log segment file. When this size is reached a new log segment will be created.log.segment.bytes=1073741824# The interval at which log segments are checked to see if they can be deleted according# to the retention policieslog.retention.check.interval.ms=300000############################# Zookeeper ############################## Zookeeper connection string (see zookeeper docs for details).# This is a comma separated host:port pairs, each corresponding to a zk# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".# You can also append an optional chroot string to the urls to specify the# root directory for all kafka znodes.zookeeper.connect=192.168.212.128:2181,192.168.212.130:2181,192.168.212.131:2181# Timeout in ms for connecting to zookeeperzookeeper.connection.timeout.ms=60000############################# Group Coordinator Settings ############################## The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.# The default value for this is 3 seconds.# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.group.initial.rebalance.delay.ms=0
4、新建日志文件 mkdir data_log
5、启动成功
nohup /home/haoker/kafka_2.12-2.3.1/bin/kafka-server-start.sh /home/haoker/kafka_2.12-2.3.1/config/server.properties &>> /home/haoker/kafka_2.12-2.3.1/kafka.log &

6、部署过程出现得错误
1、Timed out waiting for connection while in state: CONNECTING
zk连接问题
1、查看zk是否正常启动
2、把连接时间设置大点,本地得虚拟机连接比较慢
三、 Kafka 命令行操作
1、查看当前服务器中的所有 topic
./kafka-topics.sh --zookeeper 192.168.212.128:2181 --list
2、新建topic
./kafka-topics.sh --zookeeper 192.168.212.128:2181 --create --replication-factor 3 --partitions 1 --topic first
3、生产者往topic投递数据
./kafka-console-producer.sh --broker-list 192.168.212.128:9092 --topic first
4、消费者消费topic数据
./kafka-console-consumer.sh --topic first --bootstrap-server 192.168.212.128:9092 --from-beginning
5、查看某个 Topic 的详情
./kafka-topics.sh --zookeeper 192.168.212.128:2181 --describe --topic first

6、修改分区数
./kafka-topics.sh --zookeeper 192.168.212.128:2181 --alter --topic first --partitions 3

若有收获,就点个赞吧
0 人点赞
