MySQL 会依据一些规则,竭尽全力的把很糟糕的语句转换成某种可以比较高效的执行的形式,
这个过程也被称作查询重写。
本章详细介绍一些比较重要的重写规则。
条件化简
我们编写的查询语句的搜索条件本质上是一个表达式,
我们写的表达式可能比较繁杂,或者不能被高效的执行,MySQL 的查询优化器会为我们简化写的表达式。
移除不必要的括号
常量传递
a = 5 and b > a 就可以被转换为:a = 5 and b > 5
等值传递
a = b and b = c and c = 5 就可以被转换为:a = 5 and b = 5 and c = 5
移除没用的条件
对于一些明显永远为 true 或者 false的表达式,查询优化器会移除它们
(a < 1 and b = b) or (a = 6 or 5 != 5) 就可以被转换为:a < 1 or a = 6
表达式计算
在查询开始执行之前,如果表达式中只包含常量的话,它的值会被先计算出来
a = 5 + 1 就可以被转换为:a = 6
需要注意的是:如果某个列并不是以单独的形式作为表达式的操作数时,
比如:出现在函数中,出现在某个更复杂表达式中,查询优化器不会尝试对这些表达式进行化简。
比如:-a < -8 、 abs(a) > 5
having 子句 和 where 子句的合并
如果查询语句中没有出现诸如 sum、max 等聚集函数以及 group by 子句,
查询优化器就会把 having 子句和 where 子句合并起来。
常量表检测
设计 MySQL 的人认为下边这两种查询运行的特别快:
- 查询的表中一条记录都没有,或者只有一条记录(依靠统计数据判断)。
- 使用主键等值匹配或者唯一二级索引列等值匹配作为搜索条件来查询某个表。
设计 MySQL 的人认为这两种查询花费的时间特别少,是常量级别的,所以把通过这两种方式查询的表称之为常量表 (constant tables)。
查询优化器在分析一个查询语句时,首先执行常量表查询,最多只会查询出一行记录,然后把查询中涉及到该表的条件全部替换成常数,最后再分析其余表的查询成本,
比如:select from t1 inner join t2 on t1.c1 = t2.c2 where t1.primary_key = 1;
很明显,这个查询可以使用主键和常量值的等值匹配来查询 t1 表,在这个查询中 t1 表相当于常量表,
也就是上边的语句会被转换成:
select 「t1 表记录的各个字段的常量值」, t2. from t1 inner join t2 on t1.c1的常量值 = t2.c2;
外连接消除
外连接和内连接的本质区别就是:
对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配 on 子句中的过滤条件的记录,
那么该记录仍然会被加入到结果集中,对应的被驱动表记录的各个字段使用 null 值填充。
对于内连接的驱动表的记录来说,如果无法在被驱动表中找到匹配 on 子句中的过滤条件的记录,
那么该记录会被舍弃。
所以,只要我们在搜索条件中指定关于被驱动表相关列的值不为 null,那么外连接中在被驱动表中找不到符合 on 子句条件的驱动表记录也就不会被添加到最后的结果集了,
也就是说:在这种情况下:外连接和内连接查询都可以实现。
右外连接和左外连接只是在驱动表的选取方式上不同,其余方面都一样,所以优化器会首先把右外连接查询转换成左外连接查询。
在外连接查询中,指定的 where 子句中包含被驱动表中的列不为 null 值的条件被称为空值拒绝 (reject-null)。
满足空值拒绝的外查询语句,外连接和内连接可以相互转换。
这种转换带来的好处就是:查询优化器可以通过评估表的不同连接顺序(外连接、内连接)的成本,选出成本最低的那种连接顺序来执行查询。
子查询优化
子查询的语法
子查询的注意事项
in 子查询优化
将 s1 表和 s2 表进行半连接 (semi-join) 的意思就是:对于 s1 表的某条记录来说,我们只关心在 s2 表中是否存在与之匹配的记录是否存在,而不关心具体有多少条记录与之匹配,最终的结果集中只保留 s1 表的记录。
设计 MySQL 的人准备了几个实现半连接的方法:
Table pullout(子查询中的表上拉)
当子查询的查询列表处只有主键或者唯一索引列时,保证了子查询的结果集中无重复值,才可以用这种方法。
直接把子查询中的表 上拉 到外层查询的 from 子句中,并把子查询中的搜索条件合并到外层查询的搜索条件中。
比如:select from s1 where key2 in (select key2 from s2 where key3 = ‘a’);
上拉之后的查询:select from s1 inner join s2 on s1.key2 = s2.key2 where s2.key3 = ‘a’;
DuplicateWeedout execution strategy(重复值消除)
查询语句:select * from s1 where key1 in (select common_field from s2 where key3 = ‘a’);
转换为半连接查询后, s1 表中的某条记录可能在 s2 表中有多条匹配的记录,所以该条记录可能被多次添加到结果集中,为了消除重复,我们可以建立一个临时表,比如:
create table tmp (id primary key);
在执行连接查询的过程中,每当某条 s1 表中的记录要加入结果集时,
就首先把这条记录的 id 值加入到这个临时表里,如果添加成功,说明这条 s1 表中的记录之前并没有被加入到最终的结果集,现在把该记录添加到最终的结果集;如果添加失败,说明这条 s1 表中的记录之前已经被加入到最终的结果集,把它丢弃。
这种使用临时表消除 semi-join 结果集中的重复值的方式称之为 DuplicateWeedout 。
LooseScan execution strategy (松散索引扫描)
查询语句:select from s1 where key3 in (select key1 from s2 where key1 > ‘a’ and key1 < ‘b’)
在子查询中,对于 s2 表的访问可以使用到 key1 列的索引,而恰好子查询的查询列表处就是 key1 列,
这样在将该查询转换为半连接查询后,如果将 s2 作为驱动表执行查询的话,那么执行过程如图所示: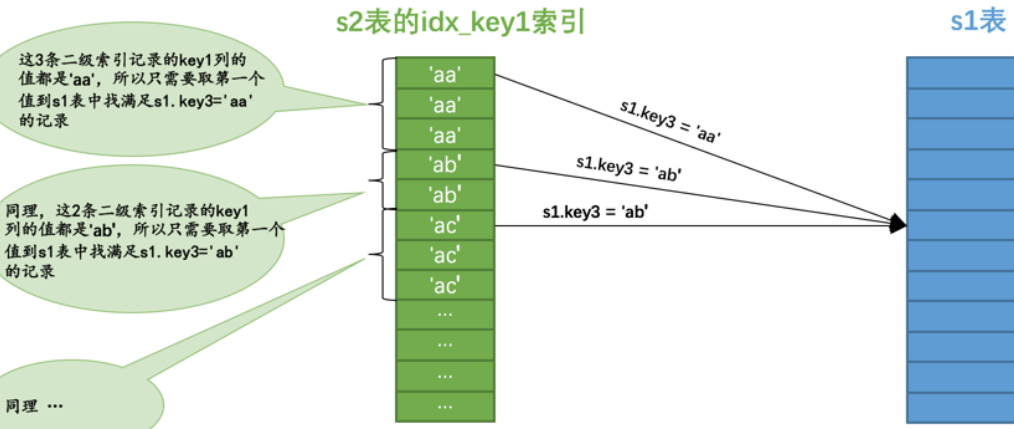
如图所示,在 s2 表的 idx_key1 索引中,值为 aa 的二级索引记录一共有 3 条,
那么只需要取第一条的值到 s1 表中查找 s1.key3 = ‘aa’ 的记录,
如果能在 s1 表中找到对应的记录,那么就把对应的记录加入到结果集。
依此类推,其他值相同的二级索引记录,也只需要取第一条记录的值到 s1 表中找匹配的记录,
这种虽然是扫描索引,但*只取值相同的记录的第一条去做匹配操作的方式被称为松散索引扫描。
Semi-join Materialization execution strategy(物化表)
先把外层查询的 in 子句中的不相关子查询进行物化,然后再进行外层查询的表和物化表的连接,
本质上也是一种 semi-join,只不过由于物化表中没有重复的记录,所以可以直接将子查询转为连接查询。
FirstMatch execution strategy (首次匹配)
FirstMatch 是一种最原始的半连接执行方式,它的执行过程为:
先取一条外层查询中的记录,然后到子查询的表中寻找符合匹配条件的记录,
如果能找到一条,则将该外层查询的记录放入最终的结果集,并且停止查找更多匹配的记录,
如果找不到符合匹配条件的记录,则将该外层查询的记录丢弃,
然后再开始取下一条外层查询的记录,重复上边这个过程。
semi - join 的适用条件
并不是所有包含 in 子查询的查询语句都可以转换为 semi - join,
只有形如这样的子查询才可以被转换为 semi - join:
select ... from t1 where expr in (select ... from t2 ...) and...或者select ... from t1 where (c1, c2, ...) in (select ... from t2 ...) and...
用文字总结一下,只有符合下边这些条件的子查询才可以被转换为 semi - join:
- 该子查询必须是和 in 语句组成的布尔表达式,并且在外层查询的 where 或者 on 子句中出现。
- 外层查询也可以有其他的搜索条件,但是和 in 子查询的搜索条件必须是使用 and 连接起来的。
- 该子查询必须是一个单一的查询,不能是由若干个查询由 union 连接起来的形式。
- 该子查询不能包含 group by 或者 having 语句或者聚集函数。
不适用于 semi - join 的情况
对于一些不能将子查询转为 semi - join 的情况,典型的比如下边这几种:
- 外层查询的 where 条件中有其他搜索条件与 in 子查询组成的布尔表达式使用非 and 连接起来
比如:select * from s1 where key1 in (select common_field from s2 where key3 = ‘a’) or key2 > 100;
- 使用 not in 而不是 in 的情况
比如:select * from s1 where key1 not in (select common_field from s2 where key3 = ‘a’);
- 在 select 子句中的 in 子查询的情况
比如:select key1 in (select common_field from s2 where key3 = ‘a’) from s1;
- 子查询中包含 group by、having 或者聚集函数的情况
比如:select from s1 where key2 in (select count() from s2 group by key1);
- 子查询中包含 union 的情况
比如:select from s1 where key1 in (select from s1 union select * from s2);
MySQL 有两个方法来优化不能转为 semi-join 查询的子查询:
- 对于不相关子查询来说,可以尝试把子查询物化之后再参与查询
比如:select * from s1 where key1 not in (select common_field from s2 where key3 = ‘a’);
先将子查询物化,然后再判断 key1 是否在物化表的结果集中可以加快查询执行的速度。
小贴士: 这里将子查询物化之后不能转为和外层查询的表的连接,只能是先扫描 s1 表, 然后对 s1 表的某记录来说,判断该记录的 key1 值在不在物化表中。
- 不管是相关子查询还是不相关子查询,都可以把 in 子查询尝试专为 exists子查询,对于任意一个 in 子查询来说,都可以转为 exists 子查询。
通用的例子如下:select from t1 where expr1 in (select expr2 from … where w1) 可以被转换
为:select from t1 where exists (select expr1 from … where w1 and expr1 = expr2)。
如果 in 子查询不满足转换为 semi-join 的条件,又不能转换为物化表或者转换为物化表的成本太大,
那么 in 子查询就会被转换为 exists 查询。
小结
- 如果 in 子查询符合转换为 semi-join 的条件,查询优化器会优先把该子查询转换为 semi-join,
然后再考虑 5 种执行半连接的策略中哪个成本最低,会选择成本最低的那种执行策略来执行子查询。
- Table pullout、DuplicateWeedout、LooseScan、Materialization、FirstMatch
- 如果 in 子查询不符合转换为 semi-join 的条件,查询优化器会从下边两种策略中找出一种成本更低的方式执行子查询:
- 先将子查询物化之后再执行查询
- 执行 in to exists 转换
对于派生表的优化
把子查询放在外层查询的 from 子句后,那么这个子查询的结果相当于一个派生表,
比如:select * from (select id as d_id, key3 as d_key3 from s2) as derived_s2;
子查询 (select id as d_id, key3 as d_key3 from s2) 的结果集就相当于一个派生表,这个表的名称是 derived_s2,该表有两个列,分别是 d_id和 d_key3。
对于含有派生表的查询,MySQL 提供了两种执行策略:
- 把派生表物化。
可以将派生表的结果集写到一个内部的临时表中,然后就把这个物化表当作普通表一样参与查询。
在对派生表进行物化时,设计 MySQL 的人使用了延迟物化的策略,即在查询中真正使用到到派生表
时才会物化派生表。
比如:select from (select ‘‘ from s1 where key1 = ‘a’) as derived_s1 inner join s2 on derived_s1.key1 = s2.key1 where s2.key2 = 1; 如果采用物化派生表的方式来执行这个查询的话,那么执行时首先会到
s2 表中找出满足 s2.key2 = 1 的记录,如果找不到,说明参与连接的 s2 表的记录就是空的,所以整个
查询的结果集就是空的,所以也就没有必要去物化查询中的派生表了。
- 将派生表和外层的表合并。
也就是将含有派生表的查询重写为没有派生表的形式,
比如:select from (select ‘‘ from s1 where key1 = ‘a’); 这个查询本质上就是想查看 s1 表中满足
key1 = ‘a’ 条件的的全部记录,
所以和下边这个语句是等价的:select from s1 where key1 = ‘a’;
对于一些稍微复杂的包含派生表的语句,比如:select from (select ‘‘ from s1 where key1 = ‘a’) as
derived_s1 inner join s2 on derived_s1.key1 = s2.key1 where s2.key2 = 1; 我们可以将派生表与外层查
询的表合并,然后将派生表中的搜索条件放到外层查询的搜索条件中,就像这样:select ‘‘ from s1
inner join s2 on s1.key1 = s2.key1 where s2.key2 = 1; 这样通过将外层查询和派生表合并的方式成功
的消除了派生表,也就意味着我们不用再付出创建和访问临时表的成本了。
但是,并不是所有带有派生表的查询都能被成功的和外层查询合并,当派生表中有这些语句就不可以和外层查询合并:聚集函数,比如:max()、min()、sum() 等、distinct、group by、having、limit、union、union all、派生表对应的子查询的 select 子句中含有另一个子查询。
所以 MySQL 在执行带有派生表的时候,优先尝试把派生表和外层查询合并掉,如果不行的话,再把派生表物化执行查询。

若有收获,就点个赞吧
0 人点赞
