- 简介
- 源码解析
- 总结
- 示例
- 全表扫描
- 两表简单JOIN
- 两表 Const JOIN
简介
MySQL 的 join 操作主要是采用 nest loop 算法,其它算法暂不讨论,其中涉及的主要函数有如下 do_select()、sub_select()、evaluate_join_record(),其简单的调用堆栈可以参考如下:
$ pgrep mysqld ← 查看mysqld的进程号
32204
$ gdb
(gdb) attach 32204 ← 链接到mysqld服务器
(gdb) b evaluate_join_record ← 设置断点,然后另一个终端链接mysql
(gdb) bt
#0 evaluate_join_record (…) at sql/sql_executor.cc:1473
#1 sub_select (…) at sql/sql_executor.cc:1291
#2 do_select (…) at sql/sql_executor.cc:944
#3 JOIN::exec (…) at sql/sql_executor.cc:199
#4 handle_query (…) at sql/sql_select.cc:184
#5 execute_sqlcom_select (…) at sql/sql_parse.cc:5143
#6 mysql_execute_command (…) at sql/sql_parse.cc:2756
#7 mysql_parse (…) at sql/sql_parse.cc:5559
#8 dispatch_command (…) at sql/sql_parse.cc:1427
#9 do_command (…) at sql/sql_parse.cc:995
#10 handle_connection (…) at sql/conn_handler/connection_handler_per_thread.cc:300
#11 pfs_spawn_thread (…) at storage/perfschema/pfs.cc:2188
#12 start_thread () at pthread_create.c
#13 clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S
MySQL 的执行器与优化器类似,同样共享 JOIN 中的内容,也就是一个查询的上下文信息;而真正执行的函数为 JOIN::exec()@sql/sql_executor.cc。
在此主要查看下 exec 的执行过程,实际的执行函数在 do_select() 中,接下来简单分析下源码的执行过程。
源码解析
MySQL 执行器的源码主要在 sql_executor.cc 中,如下简单说明下函数的执行过程,只是包含了主要的路径。
static int do_select(JOIN join,List
{
… …
Next_select_func end_select= setup_end_select_func(join);
if (join->table_count) {
join->join_tab[join->top_join_tab_count - 1].next_select= end_select;
join_tab=join->join_tab+join->const_tables; // 对const表的优化 }
… …
if (join->table_count == join->const_tables) {
… …
} else {
if (join->outer_ref_cond && !join->outer_ref_cond->val_int())
error= NESTED_LOOP_NO_MORE_ROWS;
else
error= sub_select(join,join_tab,0); // 会调用sub_select,且不是最后一条 if ((error == NESTED_LOOP_OK || error == NESTED_LOOP_NO_MORE_ROWS)
&& join->thd->killed != ABORT_QUERY)
error= sub_select(join,join_tab,1); // 最后的调用函数 … …
}
}
enum_nested_loop_state sub_select(JOIN join,JOIN_TAB join_tab,bool end_of_records)
{
… …
if (end_of_records) // 如果已经到了记录的结束位置,则直接调用qep_tab->next_select() {
enum_nested_loop_state nls=
(qep_tab->next_select)(join,qep_tab+1,end_of_records); // 详见###1 DBUG_RETURN(nls);
}
READ_RECORD info= &qep_tab->read_record;
… …
while (rc == NESTED_LOOP_OK && join->return_tab >= qep_tab_idx)
{
int error;
if (in_first_read) // 首先读取第一条记录 { // 详见###2,会在后面判断是否满足条件 in_first_read= false;
error= (*qep_tab->read_first_record)(qep_tab);
}
else
error= info->read_record(info); // 循环读取记录直到结束位置,详见###3
if (error > 0 || (join->thd->is_error())) // Fatal error rc= NESTED_LOOP_ERROR;
else if (error < 0)
break;
else if (join->thd->killed) // Aborted by user {
join->thd->send_kill_message();
rc= NESTED_LOOP_KILLED;
}
else
{ // 如果没有异常,则对记录判断是否满足条件 if (qep_tab->keep_current_rowid)
qep_tab->table()->file->position(qep_tab->table()->record[0]);
rc= evaluate_join_record(join, qep_tab);
}
}
… …
}
static enum_nested_loop_state evaluate_join_record(JOIN join, JOIN_TAB join_tab, int error)
{
… …
COND select_cond= join_tab->select_cond; // 取出相应的条件,其初始化在优化阶段里调用make_join_select()-> // add_not_null_conds() -> make_cond_for_table() 完成相应join_table的select_cond初始化 … …
if (select_cond) { // 如果有查询条件 select_cond_result= MY_TEST(select_cond->val_int()); // 完成从引擎获得的数据与query中该table的cond比较的过程 // 其最终调用的是Item_cmpfunc里的接口,如对于简单的数字等值比较使用Item_func_eq::val_int()-> // intArg_comparator::compare_int_signed() … …
if (found) {
rc= (join_tab->next_select)(join,join_tab+1, 0);
} else {
join_tab->read_record.unlock_row(join_tab); // 调用rr_unlock_row最终调用引擎的unlock_row对行进行解锁 }
… …
}
对于如上的函数调用,其主要的处理过程在 sub_query() 函数中,暂时小结一下上面出现的三个比较重要的函数指针:
- join_tab->read_first_record读取第一条记录使用的方法。
- info->read_record读取非第一条记录使用的方法,对于多条记录会循环调用该函数,该方法是根据 optimize 选择的 join type 来指定的。
- join_tab->next_select在 sub_select() 中的最后一条记录调用,也就是连接下一个 table 的方法,这里除了最后一个表使用 end_select 之外,其它的都使用 sub_select。
上述的三个指针基本组成了 nest loop 的主要过程。MySQL 会循环调用 read_record() 函数读取当前表的记录,如果有满足条件的记录则会调用 next_select 指针指定的函数。
接下来,分别讲解上述源码中的标记部分。
next_select
这也就是源码中 ###1 的标记;在创建 JOIN 实例时,也就是一个查询的上下文信息时,默认该变量的值是 sub_select() 。
read_first_record
对应源码中的 ###2,该函数主要用于读取第一条记录。
在 optimize() -> pick_table_access_method() 根据 join type 的不同类型选择相应的方法。注意:这里的 join type 就是 explain 中的 type 字段对应值 。
read_record
也就是源码中的 ###3,用于读取数据,该方法主要在两个地方做赋值:
在读取第一条记录的入口函数中,会调用 init_read_record() 函数初始化 info->read_record 变量,如全表扫描调用 rr_sequential() 函数,对于 ref join 则调用 join_read_next_same() 等。
- 同样在 pick_table_access_method() 函数中,设置 read_first_record 的同时设置了该变量。
总结
实际上的执行流程如下,在此以简单的查询为例。
JOIN::exec() ← 在优化完成之后,根据执行计划进行相应的查询操作
|-THD_STAGE_INFO() ← 设置线程的状态为executing,在sql/mysqld.cc文件中定义
|-set_executed() ← 设置为执行状态,JOIN::executed=true
|-prepare_result()
|-send_result_set_metadata() ← 先将元数据发送给客户端
|
|-do_select() ←### 查询的实际入口函数,做JOIN操作,会返回给客户端或写入表
| ←### <1>
|
|-join->first_select(join,qep_tab,0) ← 1. 执行nest loop操作,默认会调用sub_select()函数,
| | ← 也即循环调用rnd_next()+evaluate_join_record()
| |
| |###while循环读取数据###
| | ← 2. 调用存储引擎接口读取数据
| |-qep_tab->read_first_record() ← 2.1. 首次调用,实际为join_init_read_record()
| | |-tab->quick()->reset() ← 对于quick调用QUICK_RANGE_SELECT::reset()函数
| | | |-file->ha_index_init() ← 会调用存储引擎接口
| | | | |-index_init()
| | | | |-change_active_index()
| | | | |-innobase_get_index()
| | | |-file->multi_range_read_init()
| | |-init_read_record() ← 设置read_record指针,在此为rr_quick
| |
| |-info->read_record() ← 2.2 再次调用,如上,该函数在init_read_record()中初始化
| | |-info->quick->get_next() ← 实际调用QUICK_RANGE_SELECT::get_next()
| | |-file->multi_range_read_next() ← 调用handler.cc文件中函数
| | |-read_range_first() ← 对于第一次调用
| | | |-ha_index_read_map() ← 存储引擎调用
| | | |-index_read()
| | | |-row_search_mvcc()
| | |
| | |-read_range_next() ← 对于非第一次调用
| | |-ha_index_next()
| | |-general_fetch()
| | |-row_search_mvcc()
| |
| |-evaluate_join_record() ← 2.3 处理读取的记录,判断是否满足条件,包括了第一条记录
| |-qep_tab->next_select() ← 对于查询,实际会调用end_send()
| |-Query_result_send::send_data()
|
|-join->first_select(join,qep_tab,1) ← 3. 一个table已经读取数据结束,同样默认调用sub_select()
| |-join_tab->next_select() ← 调用该函数处理下个表或者结束处理
|
|-join->select_lex->query_result()->send_eof()
在 <1> 中,对于简单的查询 (const且不需要临时文件),实际上只需要执行 end_select() 即可,上述介绍的是常用的查询方式。sub_select()
这是 MySQL 的 JOIN 实现比较重要的函数,很多比较有用的函数信息,可以查看注释。
enum_nested_loop_state sub_select(JOIN join, QEP_TAB const qep_tab,bool end_of_records);
参数:
join : 本次查询的上下文信息。
join_tab :
end_of_records: 是否执行获取记录的最后一步。
示例
全表扫描
如下是单表的全表扫描。
mysql> explain select emp_no from salaries where salary = 90930;
+———+——————-+—————+———+———————-+———+————-+———+————-+——————-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+———+——————-+—————+———+———————-+———+————-+———+————-+——————-+
| 1 | SIMPLE | salaries | ALL | NULL | NULL | NULL | NULL | 2838426 | Using where |
+———+——————-+—————+———+———————-+———+————-+———+————-+——————-+
1 row in set (0.00 sec)
这里只有一个表,所以 join_tab 只有一个;而且是全表扫描,所以 read_first_record、read_record 两个指针都被指定为 rr_sequential() 函数。
又因为是 select 语句,会直接将数据返回给客户端,所以其中的 next_select 就是 end_send() 函数;如果是 insert … select … 语句的话,那么会在 setup_end_select_func() 中设置为 end_write() 完成数据的写入。
其执行流程基本如下。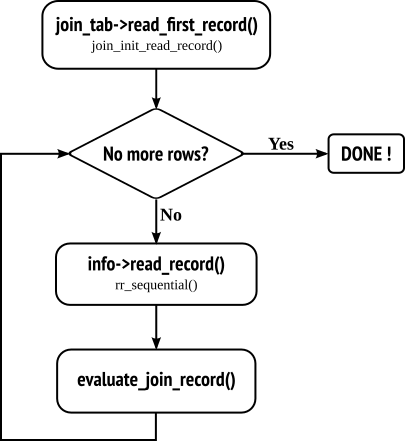
通过 gdb 查看的结果如下:
(gdb) set print pretty on
(gdb) b sub_select
Breakpoint 1 at 0x7fe9b7453ac8: file sql/sql_select.cc, line 18197.
——- 查看表的数量,此时join_tab只有一个
(gdb) p join->table_count
$1 = 1
——- const表的数量,为0
(gdb) p join->const_tables
$2 = 0
(gdb) p join_tab->next_select
$3 = (Next_select_func) 0x7fe9b745653f
(gdb) p join_tab->read_first_record
$4 = (READ_RECORD::Setup_func) 0x7fe9b7455d02
(gdb) p join_tab->read_record->read_record
$5 = (READ_RECORD::Read_func) 0x7fe9b776837b
实际的处理流程很简单。
两表简单JOIN
如下的两个表的 JOIN 操作,其中 e.gender 和 s.salary 都不是索引。
mysql> explain select * from salaries s join employees e on (s.emp_no=e.emp_no) where
-> e.gender=’F’ and s.salary=90930;
+———+——————-+———-+———+———————-+————-+————-+—————+————+——————-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+———+——————-+———-+———+———————-+————-+————-+—————+————+——————-+
| 1 | SIMPLE | e | ALL | PRIMARY | NULL | NULL | NULL | 299469 | Using where |
| 1 | SIMPLE | s | ref | PRIMARY | PRIMARY | 4 | e.emp_no | 4 | Using where |
+———+——————-+———-+———+———————-+————-+————-+—————+————+——————-+
2 rows in set (0.00 sec)
如上的 explain 结果可以基本确定 MySQL 的执行过程。
大概的执行过程是:e 表进入 sub_select() 执行,通过 rr_sequential() 函数获取该表的每条记录,然后通过 evaluate_join_record() 判断该记录是否满足 e.gender=’F’ [using where],如果没有满足则接着取下一条,满足的话,则把它的 e.emp_no 传递给 s 表。
接下来 s 执行 sub_select,其 type 是 ref,就是通过索引来获得记录而非全表扫描,也即拿 e.emp_no 的值来检索 s 的 PRIMARY KEY 来获得记录;最后再通过 s 的 evaluate_join_record() 判断是否满足 salary=90930 这个条件,如果满足是直接发送给客户端,否则获得记录进行判断。
接下来仍然通过 gdb 查看上面两个表的三个函数指针来验证上面的过程:
——- 查看表名的顺序,如下的两种方式相同
(gdb) p join->join_tab[0]->table->alias->Ptr
(gdb) p join->table[0]->alias->Ptr
$1 = 0x7fe9870171c8 “e”
——- 查看表以及const表的数量
(gdb) p join->table_count
$2 = 2
(gdb) p join->const_tables
$3 = 0
(gdb) p join_tab[0]->next_select
$4 = (Next_select_func) 0x7fe9b7453aac
(gdb) p join_tab[1]->next_select
$5 = (Next_select_func) 0x7fe9b745653f
(gdb) p join_tab[0]->read_first_record
$6 = (READ_RECORD::Setup_func) 0x7fe9b7455d02
(gdb) p join_tab[1]->read_first_record
$7 = (READ_RECORD::Setup_func) 0x7fe9b7455615
(gdb) p join_tab[0]->read_record->read_record
$8 = (READ_RECORD::Read_func) 0x7fe9b776837b
(gdb) p join_tab[1]->read_record->read_record
$9 = (READ_RECORD::Read_func) 0x7fe9b7455985
处理上述的处理过程是两个表的 JOIN 处理。
两表 Const JOIN
与上面 SQL 不同的是,emp_no 采用的是主健,执行计划如下:
mysql> explain select * from salaries s join employees e on (s.emp_no=e.emp_no) where
-> e.emp_no=62476 and s.salary=90930;
+———+——————-+———-+———-+———————-+————-+————-+———-+———+——————-+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+———+——————-+———-+———-+———————-+————-+————-+———-+———+——————-+
| 1 | SIMPLE | e | const | PRIMARY | PRIMARY | 4 | const | 1 | |
| 1 | SIMPLE | s | ref | PRIMARY | PRIMARY | 4 | const | 15 | Using where |
+———+——————-+———-+———-+———————-+————-+————-+———-+———+——————-+
2 rows in set (0.00 sec)
正常来说,执行过程仍然如上所示,其中驱动表是 e,但是确实是这样的吗?实际上,在 sub_select() 设置断点后,实际第一次的入参时 s 表,而非我们开始认为的 e 表。
——- 查看表名的顺序,如下的两种方式相同
(gdb) p join->join_tab[0]->table->alias->Ptr
$1 = 0x7fe9870171c8 “e”
——- 查看表以及const表的数量
(gdb) p join->table_count
$2 = 2
(gdb) p join->const_tables
$3 = 1
——- 查看第一次进入sub_select()时的表名称
(gdb) p join_tab->table->alias->Ptr
$4 = 0x7fe987017248 “s”
(gdb) p join_tab[0]->next_select
$4 = (Next_select_func) 0x7fe9b7453aac
(gdb) p join_tab[1]->next_select
$5 = (Next_select_func) 0x7fe9b745653f
(gdb) p join_tab[0]->read_first_record
$6 = (READ_RECORD::Setup_func) 0x7fe9b7455d02
(gdb) p join_tab[1]->read_first_record
$7 = (READ_RECORD::Setup_func) 0x7fe9b7455615
(gdb) p join_tab[0]->read_record->read_record
$8 = (READ_RECORD::Read_func) 0x7fe9b776837b
(gdb) p join_tab[1]->read_record->read_record
$9 = (READ_RECORD::Read_func) 0x7fe9b7455985
实际上对于 const 类型,我们可以直接获取到对应的查询条件,此时只需要对 s 表进行过滤即可。
如果直接查看 salaries 表中 emp_no 是 62476 的记录,会发现总共有 15 条记录;那么在 gdb 调试时,如果在 evaluate_join_record() 中设置断点之后,总共执行了 16 次。除了比较 15 次记录之外,在最后一条记录,同样会调用该函数。
这一部分在优化器 make_join_statistics(),详细内容后面再介绍。

若有收获,就点个赞吧
0 人点赞
