如果 redo log 可以无限地增大,同时缓冲池也足够大,是不是就意味着可以不将缓冲池中的脏页刷新回磁盘上?宕机时,完全可以通过 redo log 来恢复整个数据库系统中的数据。
显然,上述的前提条件是不满足的,这也就引入了 checkpoint 技术。
简介
Checkpoint (检查点) 的目的是为了解决以下几个问题:1、缩短数据库的恢复时间;2、缓冲池不够用时,将脏页刷新到磁盘;3、重做日志不可用时,刷新脏页。
- 数据库宕机时,不需要重做所有的日志,因为 Checkpoint 之前的脏页都已经刷新回磁盘,只需对 Checkpoint 后的 redo log 进行恢复即可,这样就大大缩短了恢复的时间。
- 当缓冲池不够用时,会根据 LRU 算法淘汰最近最少使用的页,若此页为脏页,那么需要强制执行 Checkpoint,将脏页刷回磁盘。
- 当前数据库对 redo log 的设计都是循环使用的,为了防止被覆盖,必须强制 Checkpoint,将缓冲池中的页至少刷新到当前 redo log 的位置。
InnoDB 通过 Log Sequence Number, LSN 来标记版本,这是 8 字节的数字,每个页有 LSN,重做日志中也有 LSN,Checkpoint 也有 LSN,这个是联系三者的关键变量。
LSN 当前状态可以通过如下命令查看。
mysql> SHOW ENGINE INNODB STATUS\G
—-
LOG
—-
Log sequence number 293590838 LSN1事务创建时一条日志
Log flushed up to 293590838
Pages flushed up to 293590838
Last checkpoint at 293590829
0 pending log flushes, 0 pending chkp writes
1139 log i/o’s done, 0.00 log i/o’s/second
分类
通常有两种 Checkpoint,分别为:Sharp Checkpoint、Fuzzy Checkpoint;前者在正常关闭数据库时使用,会将所有脏页刷回磁盘;后者,会在运行时使用,用于部分脏页的刷新。
Checkpoint 所做的事情无外乎是将缓冲池中的脏页刷回到磁盘,不同之处在于每次刷新多少页到磁盘,每次从哪里取脏页,以及什么时间触发 Checkpoint。
Master Thread Checkpoint
InnoDB 的主线程以每秒或每十秒的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘,这个过程是异步的,此时 InnoDB 可以进行其他的操作,用户查询线程不会阻塞。
FLUSH_LRU_LIST Checkpoint
InnoDB 要保证 BP 中有足够空闲页,在 1.1.x 之前,该操作发生在用户查询线程中,显然这会阻塞用户的查询。如果没有足够空闲页,需要将 LRU 列表尾端的页移除,如果有脏页,那么就需要进行 Checkpoint,因为这些页来自 LRU 列表,所以称为 FLUSH_LRU_LIST Checkpoint 。
MySQL-5.6 (InnoDB-1.2.x) 版本开始,这个检查被放在了一个单独的 Page Cleaner 线程中进行,而且用户可以通过参数 innodb_lru_scan_depth 控制 LRU 列表中可用页的数量。
mysql> SHOW GLOBAL VARIABLES LIKE ‘innodb_lru_scan_depth’;
+———————————-+———-+
| Variable_name | Value |
+———————————-+———-+
| innodb_lru_scan_depth | 1024 |
+———————————-+———-+
1 row in set (0.01 sec)
Async/Sync Flush Checkpoint
是指重做日志文件不可用时,需要强制将脏页列表中的一些页刷新回磁盘,而此时脏页是从脏页列表中选取的,这可以保证重做日志文件可循环使用。
在 InnoDB 1.2.X 版本之前,Async Flush Checkpoint 会阻塞发现问题的用户查询线程,Sync Flush Checkpoint 会阻塞所有查询线程;InnoDB 1.2.X 之后放到单独的 Page Cleaner Thread。
Dirty Page too much Checkpoint
即脏页数量太多时,InnoDB 会强制进行 Checkpoint 。
mysql> SHOW GLOBAL VARIABLES LIKE ‘innodb_max_dirty_pages_pct’;
+——————————————+—————-+
| Variable_name | Value |
+——————————————+—————-+
| innodb_max_dirty_pages_pct | 75.000000 |
+——————————————+—————-+
1 row in set (0.03 sec)
也即当缓冲池中脏页的数量占据 75% 时,强制进行 Checkpoint,刷新一部分的脏页到磁盘,其目的还是为了保证缓冲池中有足够可用的空闲页。
CheckPoint 机制
在 Innodb 每次都取最老的 modified page 对应的 LSN,并将此脏页的 LSN 作为 Checkpoint 点记录到日志文件,意思就是 “此 LSN 之前对应的日志和数据都已经刷新到磁盘” 。
当 MySQL 启动做崩溃恢复时,会从 last checkpoint 对应的 LSN 开始扫描 redo log ,并将其应用到 buffer pool,直到 last checkpoint 对应的 LSN 等于 log flushed up to 对应的 LSN,则恢复完成。
如下是整个 redo log 的生命周期。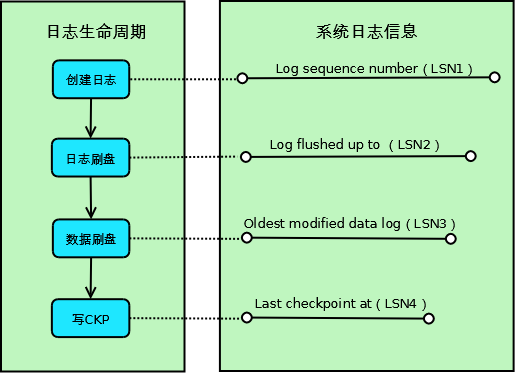
InnoDB 的一条事务日志共经历 4 个阶段:
- 创建阶段 (log sequence number, LSN1):事务创建一条日志,当前系统 LSN 最大值,新的事务日志 LSN 将在此基础上生成,也就是 LSN1+新日志的大小;
- 日志刷盘 (log flushed up to, LSN2):当前已经写入日志文件做持久化的 LSN;
- 数据刷盘 (oldest modified data log, LSN3):当前最旧的脏页数据对应的 LSN,写 Checkpoint 的时候直接将此 LSN 写入到日志文件;
- 写CKP (last checkpoint at, LSN4):当前已经写入 Checkpoint 的 LSN,也就是上次的写入;
对于系统来说,以上 4 个 LSN 是递减的,即: LSN1>=LSN2>=LSN3>=LSN4 。如上所述,LSN 当前状态可以通过如下命令查看。
mysql> SHOW ENGINE INNODB STATUS\G
—-
LOG
—-
Log sequence number 293590838 LSN1事务创建时一条日志
Log flushed up to 293590838
Pages flushed up to 293590838
Last checkpoint at 293590829
0 pending log flushes, 0 pending chkp writes
1139 log i/o’s done, 0.00 log i/o’s/second
如上的信息是在 log_print() 函数中打印。
void log_print( FILE* file)
{
… …
fprintf(file,
“Log sequence number “ LSN_PF “\n”
“Log flushed up to “ LSN_PF “\n”
“Pages flushed up to “ LSN_PF “\n”
“Last checkpoint at “ LSN_PF “\n”,
log_sys->lsn,
log_sys->flushed_to_disk_lsn,
log_buf_pool_get_oldest_modification(),
log_sys->last_checkpoint_lsn);
… …
}
日志保护机制
InnoDB 中 LSN 是单调递增的,而日志文件大小却是固定的,所以在写入的时候通过取余来计算偏移量,这样存在两个 LSN 写入到同一位置的可能,如果日志被覆盖,而数据也没有刷盘,一旦宕机,数据就丢失了。
为此,InnoDB 实现了一套日志保护机制,详细实现如下。
首先,明确下概念,上述的 buf 是指 redo log buffer,而 ckp 实际上与 buffer pool 相关,也就是脏页的刷脏。上述直线表示 redo log 的空间,会乘 0.9 的安全系数。
- Ckp age (LSN1- LSN4) 还没有做 Checkpoint 的日志范围,若超过日志空间,说明被覆盖的日志可能还没有刷到磁盘,而其 BP 中对应的数据 (脏页) 肯定没有刷到磁盘上;
- Buf age (LSN1- LSN3) 脏页对应的日志还没有刷盘的范围,若超过日志空间,说明被覆盖的日志及其 BP 中对应数据肯定还没有刷到磁盘;
当事务执行速度大于刷脏速度时,Ckp age和Buf age (innodb_flush_log_at_trx_commit!=1时) 都会逐步增长,当达到 async 点的时候,强制进行写 redo-log 或者写 Checkpoint,如果这样做还是赶不上事务执行的速度,则为了避免数据丢失,到达 sync 点的时候,会阻塞其它所有的事务,专门进行 redo-log 刷盘或者写 Checkpoint。
也就是说,只要事务执行速度大于脏页刷盘速度,最终都会触发日志保护机制,进而将事务阻塞,导致 MySQL 操作挂起。
源码解析
临界范围计算
如下是相关的变量以及临界值的计算函数。
——- 相关变量
innodb_log_buffer_size = 16777216 = 16M
innodb_log_file_size = 50331648 = 48M
innodb_log_files_in_group = 2
innodb_flush_log_at_trx_commit = 1
innodb_thread_concurrency = 0
——- 计算临界函数调用栈
innobase_start_or_create_for_mysql()
|-log_group_init()
|-log_calc_max_ages() 计算临界范围
接下来看看临界值是如何计算的。
bool log_calc_max_ages(void)
{
log_mutex_enter();
group = UT_LIST_GET_FIRST(log_sys->log_groups);
// 设置redo-log的最大磁盘空间,也就是64-bits正整数的最大值 smallest_capacity = LSN_MAX;// 5.7实际只支持一个分组,获取的是除了头(LOG_FILE_HDR_SIZE)之外的总redo-log空间大小 while (group) {<br /> if (log_group_get_capacity(group) < smallest_capacity) {<br /> smallest_capacity = log_group_get_capacity(group);<br /> }<br /> group = UT_LIST_GET_NEXT(log_groups, group);<br /> }// 实际真正可以使用的空间需要乘以一个安全系数0.9 smallest_capacity = smallest_capacity - smallest_capacity / 10;// 为每个OS线程预留一部分存储空间 free = LOG_CHECKPOINT_FREE_PER_THREAD * (10 + srv_thread_concurrency)<br /> + LOG_CHECKPOINT_EXTRA_FREE;<br /> if (free >= smallest_capacity / 2) { // 需要预留足够的内存空间 success = false;<br /> goto failure;<br /> } else {<br /> margin = smallest_capacity - free;<br /> }// 好吧,再预留一部分内存空间 margin = margin - margin / 10; /* Add still some extra safety */<br /> log_sys->log_group_capacity = smallest_capacity;// 1-1/8=7/8=0.875 log_sys->max_modified_age_async = margin<br /> - margin / LOG_POOL_PREFLUSH_RATIO_ASYNC;<br /> // 1-1/16=15/16=0.9375 log_sys->max_modified_age_sync = margin<br /> - margin / LOG_POOL_PREFLUSH_RATIO_SYNC;// 1-1/32=31/32=0.96875 log_sys->max_checkpoint_age_async = margin - margin<br /> / LOG_POOL_CHECKPOINT_RATIO_ASYNC;<br /> log_sys->max_checkpoint_age = margin;
failure:
log_mutex_exit();
return(success);
}
关于边界划分可以简单查看下图。
边界检查
对于 max_modified_age_async 变量,也就是异步刷新,会在 page cleaner 线程中检查。
#define PCT_IO(p) ((ulong) (srv_io_capacity * ((double) (p) / 100.0)))
buf_flush_page_cleaner_coordinator() ← 该函数基本上每秒调用一次
|-buf_flush_page_cleaner_coordinator()
|-page_cleaner_flush_pages_recommendation()
|-log_get_lsn() ← 获取当前lsn,也就是log_sys->lsn
|-af_get_pct_for_dirty() ← 是否需要刷新多个页,返回IO-Capacity的百分比
| |-buf_get_modified_ratio_pct()
| |-buf_get_total_list_len()
|
|-af_get_pct_for_lsn() ← 计算是否需要进行异步刷redo-log,返回IO-Capacity的百分比
| |-log_get_max_modified_age_async() ← 获取max_modified_age_async
|
|-ut_max() ← 获取上述两个返回值的最大值
除了 max_modified_age_async 变量之外,其它相关的变量都会在 log_checkpoint_margin() 函数中进行比较,详细内容可以直接查看如下函数。
static void log_checkpoint_margin(void)
{
log_t* log = log_sys;
lsn_t age;
lsn_t checkpoint_age;
ib_uint64_t advance;
lsn_t oldest_lsn;
bool success;
loop:
advance = 0;
log_mutex_enter();<br /> ut_ad(!recv_no_log_write);// 判断是否需要执行flush或者checkpoint,不需要则直接返回 if (!log->check_flush_or_checkpoint) {<br /> log_mutex_exit();<br /> return;<br /> }// 找出当前所有buffer pool实例中最老的LSN,实际上直接读取每个flush_list的尾部即可 oldest_lsn = log_buf_pool_get_oldest_modification();// 如果计算的age大于max_modified_age_sync,则需要做一次同步刷新 age = log->lsn - oldest_lsn;<br /> if (age > log->max_modified_age_sync) {<br /> /* A flush is urgent: we have to do a synchronous preflush */<br /> advance = age - log->max_modified_age_sync;<br /> }// 计算checkpoint_age,并判断是否需要做checkpoint以及是否需要同步 checkpoint_age = log->lsn - log->last_checkpoint_lsn;<br /> if (checkpoint_age > log->max_checkpoint_age) {<br /> /* A checkpoint is urgent: we do it synchronously */<br /> checkpoint_sync = true;<br /> do_checkpoint = true;<br /> } else if (checkpoint_age > log->max_checkpoint_age_async) {<br /> /* A checkpoint is not urgent: do it asynchronously */<br /> do_checkpoint = true;<br /> checkpoint_sync = false;<br /> log->check_flush_or_checkpoint = false;<br /> } else {<br /> do_checkpoint = false;<br /> checkpoint_sync = false;<br /> log->check_flush_or_checkpoint = false;<br /> }<br /> log_mutex_exit();if (advance) {<br /> lsn_t new_oldest = oldest_lsn + advance;<br /> // 需要同步刷新,则将LSN推进到新的LSN位置 success = log_preflush_pool_modified_pages(new_oldest);// 如果失败说明有其它的线程在处理 /* If the flush succeeded, this thread has done its part and can proceed. If it did not succeed, there was another thread doing a flush at the same time. */<br /> if (!success) {<br /> log_mutex_enter();<br /> log->check_flush_or_checkpoint = true;<br /> log_mutex_exit();<br /> goto loop;<br /> }<br /> }if (do_checkpoint) {<br /> log_checkpoint(checkpoint_sync, FALSE);<br /> if (checkpoint_sync) {<br /> goto loop;<br /> }<br /> }<br />}<br />在用户线程中,会调用 log_free_check() 函数检查是否需要将日志刷新到磁盘。<br />log_free_check()<br /> |-log_check_margins()<br /> |-log_write_up_to()<br />在 log_check_margins() 函数中,会检查 log_sys->buf_free > log->max_buf_free,如果成立则会执行日志刷盘操作。
检查点写入
一般会通过调用 log_checkpoint() 函数完成 checkpoint 的写入,需要注意的是,该函数中只会完成 checkpoint 的写入,并不会刷脏页。
当然也可以调用 log_make_checkpoint_at() 完成刷脏以及 checkpoint 的写入。
log_make_checkpoint_at()
|-log_preflush_pool_modified_pages()
|-log_checkpoint() ← 并不从BP中刷脏页,只检查BP中的最大LSN,然后刷新到磁盘
|-log_mutex_enter() ← 持有log_sys->mutex锁
|-log_buf_pool_get_oldest_modification()
| |-buf_pool_get_oldest_modification() ← 遍厉所有BP实例,获取最大lsn,之前都已经写入磁盘
|
|-fil_names_clear()
| |-mtr_t::commit_checkpoint()
|
|-log_write_up_to()
|
|-log_write_checkpoint_info()
|-log_group_checkpoint() ← 将checkpoint信息写入redolog头部,两个写入点轮流写入
checkpoint 信息分别保存在 ib_logfile0 的 512 字节和 1536(3512) 字节处,每个 checkpoint 默认大小为 512 字节,当然,其中很大一部分是空白,详细可以参考如下函数。
static void log_group_checkpoint(log_group_t group)
{
… …
buf = group->checkpoint_buf;
memset(buf, 0, OS_FILE_LOG_BLOCK_SIZE);
mach_write_to_8(buf + LOG_CHECKPOINT_NO, log_sys->next_checkpoint_no);<br /> mach_write_to_8(buf + LOG_CHECKPOINT_LSN, log_sys->next_checkpoint_lsn);
lsn_offset = log_group_calc_lsn_offset(log_sys->next_checkpoint_lsn,<br /> group);<br /> mach_write_to_8(buf + LOG_CHECKPOINT_OFFSET, lsn_offset);<br /> mach_write_to_8(buf + LOG_CHECKPOINT_LOG_BUF_SIZE, log_sys->buf_size);
log_block_set_checksum(buf, log_block_calc_checksum_crc32(buf));
MONITOR_INC(MONITOR_PENDING_CHECKPOINT_WRITE);
log_sys->n_log_ios++;
MONITOR_INC(MONITOR_LOG_IO);
ut_ad(LOG_CHECKPOINT_1 < univ_page_size.physical());<br /> ut_ad(LOG_CHECKPOINT_2 < univ_page_size.physical());
if (log_sys->n_pending_checkpoint_writes++ == 0) {<br /> rw_lock_x_lock_gen(&log_sys->checkpoint_lock,<br /> LOG_CHECKPOINT);<br /> }
/* Note: We alternate the physical place of the checkpoint info. See the (next_checkpoint_no & 1) below. */
/* We send as the last parameter the group machine address added with 1, as we want to distinguish between a normal log file write and a checkpoint field write */
fil_io(IORequestLogWrite, false,<br /> page_id_t(group->space_id, 0),<br /> univ_page_size,<br /> (log_sys->next_checkpoint_no & 1)<br /> ? LOG_CHECKPOINT_2 : LOG_CHECKPOINT_1,<br /> OS_FILE_LOG_BLOCK_SIZE,<br /> buf, (byte*) group + 1);
ut_ad(((ulint) group & 0x1UL) == 0);<br />}<br />InnoDB 的 checkpoint 主要有 3 部分信息组成:
- checkpoint no每次写入都会递增,用于轮流写入 redo log 的头部的两部分,可以通过该值判断那个比较新;
- checkpoint lsn记录了产生该 checkpoint 时 log_sys->next_checkpoint_lsn 是 flush 的 LSN,确保在该 LSN 前面的数据页都已经落盘,不再需要通过 redo log 进行恢复;
- checkpoint offset记录了该 checkpoint 产生时,redo log 在 ib_logfile 中的偏移量,通过该值就可以找到需要恢复的 redo log 开始位置。
每次在启动时,都会尝试读取两个值,并比较两者,获取较大的值。

若有收获,就点个赞吧
0 人点赞
