题目
 样例1输入 6 0 0 1 0 1 1 3 1 5 1 7 1 样例1输出 3 样例1解释 按照规则一,最佳阈值的选取范围为0,1,3,5,7。 θ=0时,预测正确次数为4; θ=1时,预测正确次数为5; θ=3时,预测正确次数为5; θ=5时,预测正确次数为4; θ=7时,预测正确次数为3。 阈值选取为1或3时,预测准确率最高; 所以按照规则二,最佳阈值的选取范围缩小为1,3。 依规则三,θ=max1,3=3。 样例2输入 8 5 1 5 0 5 0 2 1 3 0 4 0 100000000 1 1 0 样例2输出 100000000 *子任务 70%的测试数据保证m<=200; 全部的测试数据保证1<=m<=105。 |
|---|
思路
…没啥好说的,这是最早开始做的,那时候不会做,理解完别人代码后才懂了前缀和的用处。具体内容在代码注释里。
代码
70分超时代码
其中对STL的运用值得学习。
超时原因:30%数据<= 10^5 ,两重循环就超时了。
理解:程序为什么会超时?
这张图展示了一般情况下,不同复杂度1s内可以处理的大概规模。
具体理解见:程序为什么会超时?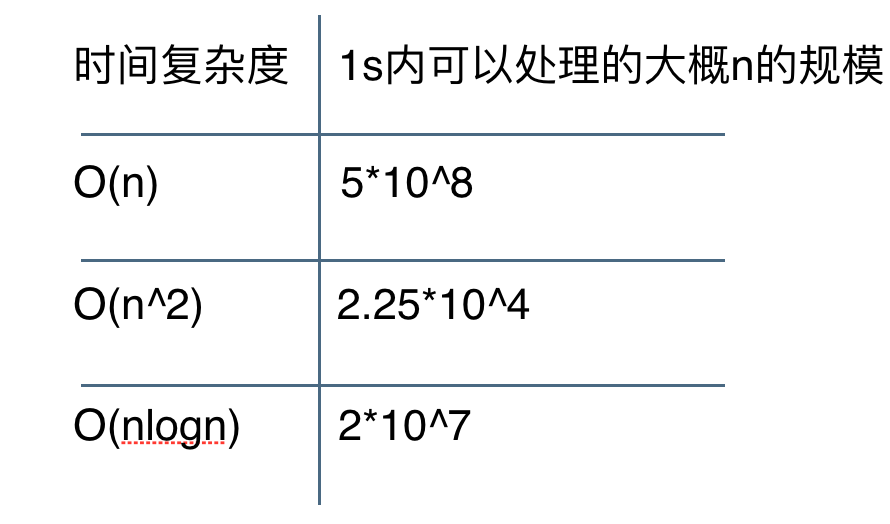
可以通过看数据规模来推测:
 的算法,
的算法, 可以几百,一般题目给的数据范围为100,就告诉你可以用
可以几百,一般题目给的数据范围为100,就告诉你可以用 的算法AC。
的算法AC。 的算法,
的算法, 可以几千,一般不到万,经常出现的就是数据范围1000。
可以几千,一般不到万,经常出现的就是数据范围1000。 或者
或者 的算法,最常见的数据范围就是
的算法,最常见的数据范围就是 为100000。
为100000。#include<iostream>#include<vector>#include<set>#include<algorithm>using namespace std;int count_num;int main(){ios::sync_with_stdio(false);//提高输入输出效率int m;vector<int> zero,one;set<int> yuzhi;int best_y=0,best_num=0;cin>>m;while(m--){int temp_y,temp_result;cin>>temp_y>>temp_result;if(temp_result==0){zero.push_back(temp_y);}else{one.push_back(temp_y);}yuzhi.insert(temp_y);}//对0和1的vector排序sort(zero.begin(),zero.end());sort(one.begin(),one.end());for(set<int>::iterator it=yuzhi.begin();it!=yuzhi.end();it++){count_num =0;for(int i=0;i<zero.size();i++){if(zero[i]<*it){count_num++;}else{break;}}for(int i=one.size()-1;i>=0;i--){if(one[i]>=*it){count_num++;}else{break;}}if(count_num>=best_num){best_num =count_num;best_y =*it;}}cout<<best_y;return 0;}
满分代码
运用了前缀和思想。 ```cpp
include
include
include
include
using namespace std; struct scorenode{ int y,
result;
}; vector
v;//阈值成绩容器 set sy;//去重后的阈值序列 const int N =100000+5;
bool cmp(scorenode a,scorenode b){ return a.y<b.y;//升序
} int main(){ //ios::sync_with_stdio(false); int sum[N] ={0};//成绩前缀和 int best_num=0,best_y =0; int m;//输入
cin>>m;
//不能用m--,后面还要用到m的
// while(m—){
// scorenode s;
// cin>>s.y>>s.result;
// v.push_back(s);
// }
for(int i=0;i
v.push_back(s);
}
//按照y的升序排序
sort(v.begin(),v.end(),cmp);
//计算成绩前缀和,sum是从1开始计数,这里具体的值代表<=阈值i的不挂科人数,sum[m]就是总的不挂科人数
for(int i=1;i<=m;i++){
sum[i]=sum[i-1]+v[i-1].result;
}
int one=0 ,zero=0,count=0;
for(int i=1;i<=m;i++){
int temp_y =v[i-1].y;//按序比较阈值
if(sy.count(temp_y)){
continue;//去重阈值
}
sy.insert(temp_y);
one =sum[m]-sum[i-1];//总的不挂科人数-比当前阈值低的不挂科(因为设定阈值后,这些人就挂了,变成了不正确数据)
zero =i-1-sum[i-1];//i-1是比当前阈值成绩低的总人数,总人数减去不挂科的,就是挂科人数
count =one+zero;
if(count>=best_num){
best_num =count;
best_y=temp_y;
}
}
cout<<best_y<<endl;
return 0;
} ```

若有收获,就点个赞吧
0 人点赞
