1.输入
1x3x224x224 vit_deit_tiny_patch16_224为例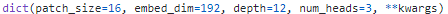
2.PatchEmbed
class PatchEmbed(nn.Module):""" Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=None):super().__init__()img_size = to_2tuple(img_size)patch_size = to_2tuple(patch_size)self.img_size = img_sizeself.patch_size = patch_sizeself.patch_grid = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])self.num_patches = self.patch_grid[0] * self.patch_grid[1]self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):# 1x3x224x224B, C, H, W = x.shape# FIXME look at relaxing size constraintsassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# -> 1x192x14x14 -> 1x192x196 -> 1x196x192x = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)return x
3.Attention
class Attention(nn.Module):def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):super().__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5# 192 x 576(192*3)self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop)def forward(self, x):# 1x196x192 196=14x14(patch大小) 192(embed_dim)B, N, C = x.shape# -> 1x196x576 -> 1x196x3x3x64 -> 3x1x3x196x64qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)# 1x3x196x64q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)# q -> 1x3x196x64# k.transpose(-2, -1) -> 1x3x64x196# attn -> 1x3x196x196attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)# 1x3x196x64 -> 1x196x3x64 -> 1x196x192x = (attn @ v).transpose(1, 2).reshape(B, N, C)# 1x196x192x = self.proj(x)x = self.proj_drop(x)return x
4.Mlp
class Mlp(nn.Module):def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_features# in_features:192, hidden_features:768(192x4)self.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):# x -> 1x196x192x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return x
5.
class VisionTransformer(nn.Module):""" Vision TransformerA PyTorch impl of : `An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale`- https://arxiv.org/abs/2010.11929Includes distillation token & head support for `DeiT: Data-efficient Image Transformers`- https://arxiv.org/abs/2012.12877"""def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12,num_heads=12, mlp_ratio=4., qkv_bias=True, qk_scale=None, representation_size=None, distilled=False,drop_rate=0., attn_drop_rate=0., drop_path_rate=0., embed_layer=PatchEmbed, norm_layer=None,act_layer=None, weight_init=''):"""Args:img_size (int, tuple): input image sizepatch_size (int, tuple): patch sizein_chans (int): number of input channelsnum_classes (int): number of classes for classification headembed_dim (int): embedding dimensiondepth (int): depth of transformernum_heads (int): number of attention headsmlp_ratio (int): ratio of mlp hidden dim to embedding dimqkv_bias (bool): enable bias for qkv if Trueqk_scale (float): override default qk scale of head_dim ** -0.5 if setrepresentation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if setdistilled (bool): model includes a distillation token and head as in DeiT modelsdrop_rate (float): dropout rateattn_drop_rate (float): attention dropout ratedrop_path_rate (float): stochastic depth rateembed_layer (nn.Module): patch embedding layernorm_layer: (nn.Module): normalization layerweight_init: (str): weight init scheme"""super().__init__()self.num_classes = num_classesself.num_features = self.embed_dim = embed_dim # num_features for consistency with other modelsself.num_tokens = 2 if distilled else 1norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)act_layer = act_layer or nn.GELUself.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)num_patches = self.patch_embed.num_patchesself.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None# 需要position embedding来编码tokens的位置信息self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))self.pos_drop = nn.Dropout(p=drop_rate)dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay ruleself.blocks = nn.Sequential(*[Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, act_layer=act_layer)for i in range(depth)])self.norm = norm_layer(embed_dim)# Representation layerif representation_size and not distilled:self.num_features = representation_sizeself.pre_logits = nn.Sequential(OrderedDict([('fc', nn.Linear(embed_dim, representation_size)),('act', nn.Tanh())]))else:self.pre_logits = nn.Identity()# Classifier head(s)self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.head_dist = Noneif distilled:self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()# Weight initassert weight_init in ('jax', 'jax_nlhb', 'nlhb', '')head_bias = -math.log(self.num_classes) if 'nlhb' in weight_init else 0.trunc_normal_(self.pos_embed, std=.02)if self.dist_token is not None:trunc_normal_(self.dist_token, std=.02)if weight_init.startswith('jax'):# leave cls token as zeros to match jax implfor n, m in self.named_modules():_init_vit_weights(m, n, head_bias=head_bias, jax_impl=True)else:trunc_normal_(self.cls_token, std=.02)self.apply(_init_vit_weights)def _init_weights(self, m):# this fn left here for compat with downstream users_init_vit_weights(m)@torch.jit.ignoredef no_weight_decay(self):return {'pos_embed', 'cls_token', 'dist_token'}def get_classifier(self):if self.dist_token is None:return self.headelse:return self.head, self.head_distdef reset_classifier(self, num_classes, global_pool=''):self.num_classes = num_classesself.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()if self.num_tokens == 2:self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()def forward_features(self, x):x = self.patch_embed(x)cls_token = self.cls_token.expand(x.shape[0], -1, -1) # stole cls_tokens impl from Phil Wang, thanksif self.dist_token is None:# 增加cls_token进行分类,获取image featurex = torch.cat((cls_token, x), dim=1)else:x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)x = self.pos_drop(x + self.pos_embed)x = self.blocks(x)x = self.norm(x)if self.dist_token is None:# 返回的类似于pooling层后的特征return self.pre_logits(x[:, 0])else:return x[:, 0], x[:, 1]def forward(self, x):x = self.forward_features(x)if self.head_dist is not None:x, x_dist = self.head(x[0]), self.head_dist(x[1]) # x must be a tupleif self.training and not torch.jit.is_scripting():# during inference, return the average of both classifier predictionsreturn x, x_distelse:return (x + x_dist) / 2else:x = self.head(x)return x

若有收获,就点个赞吧
0 人点赞
