- (1.7 HashMap [数组 + 链表])FAQ
- 1.为啥不使用ArrayList方式存储?
- 2.当key命中的数组索引一致,需要进行链表插入时,是从链表头,中,尾哪里插入,为什么?
- 3.HashMap默认数组长度,最大长度
- 4.Integer.highestOneBit() 函数的作用
- 5.roundUpToPowerOf2() 中的 number - 1作用
- 6.通过key的hashcode 所得到的索引,要满足的两个条件?
- 7.数组的初始化长度为啥要是2的幂次方呢?
- 8.hash方法的右移和^运算的作用
- 9.key为null的时候,特殊情况
- 10.既然key为null,会落在第一位,那么第一位会有其他key吗?
- 11.add(index,e)方法,ArrayList和LinkendList 插入谁快?
- 12.hashMap扩容的条件?
- 13.在进行扩容的时候,扩容前后同一个数组元素上,有啥规律?
- 14.在进行扩容的时候,为啥不直接数组上的第一个元素直接移动到新数组上,而是遍历?
- 15.多线程下为啥是不安全的?
- 16.hash种子作用?
- 17.如何避免hashmap扩容?
- 18.在hashmap循环中,删除key,为啥会报错?
- 19.modCount的作用?
- 20.扩容大小规律?
- (1.7 ConcurrentHashMap[Segment数组 + HashEntry + 数组链表]) FAQ
- (1.8 HashMap[Node数组 + 链表/红黑树]) FAQ
(1.7 HashMap [数组 + 链表])FAQ
1.为啥不使用ArrayList方式存储?
虽然存储快,但是查询效率低,ArrayList是通过index获取的,直接通过index拿数组的元素所以快,而hashmap是通过key获取的,key和内部数组如果没有建立关系,就需要全局遍历查找,效率很低;
2.当key命中的数组索引一致,需要进行链表插入时,是从链表头,中,尾哪里插入,为什么?
是从头部插入。原因:链表的头部是第一个,也就是数组索引下的Node,是已知的,不用找。而中部和尾部都需要遍历查找。
3.HashMap默认数组长度,最大长度
默认长度:1 << 4 = 16 ,最大长度 1 << 30 = 2
4.Integer.highestOneBit() 函数的作用
拿到一个int小于等于当前int整数的2次方数,例如 17->16,6->4,10->8,32->32
5.roundUpToPowerOf2() 中的 number - 1作用
为了处理刚好等于2次方数的情况;例如 传入16应该返回16,如果不进行number-1,那么返回的是32
6.通过key的hashcode 所得到的索引,要满足的两个条件?
- 不能角标越界
- 需要均匀的分布在每个数组元素上
7.数组的初始化长度为啥要是2的幂次方呢?
因为在indexFor 方法中,需要使用 key的hashcode值 和 table.length - 1 进行与运算即: hashcode & (table.length-1) 得到索引,而只有数组长度为2的幂次方时,length-1 得到的数字的二进制位上面都是1,而hashcode又是一个随机数,所以可以保证得到的索引会均匀的分布在每个元素上。 如下图,假设length是16,length-1为15,则与运算之后,可以保证 得到的角标 <= 15,又因为hashcode是一个随机数,所以可以保证平均分布到每个数组元素上。 为啥不用%?因为位运算比%运算效率要高
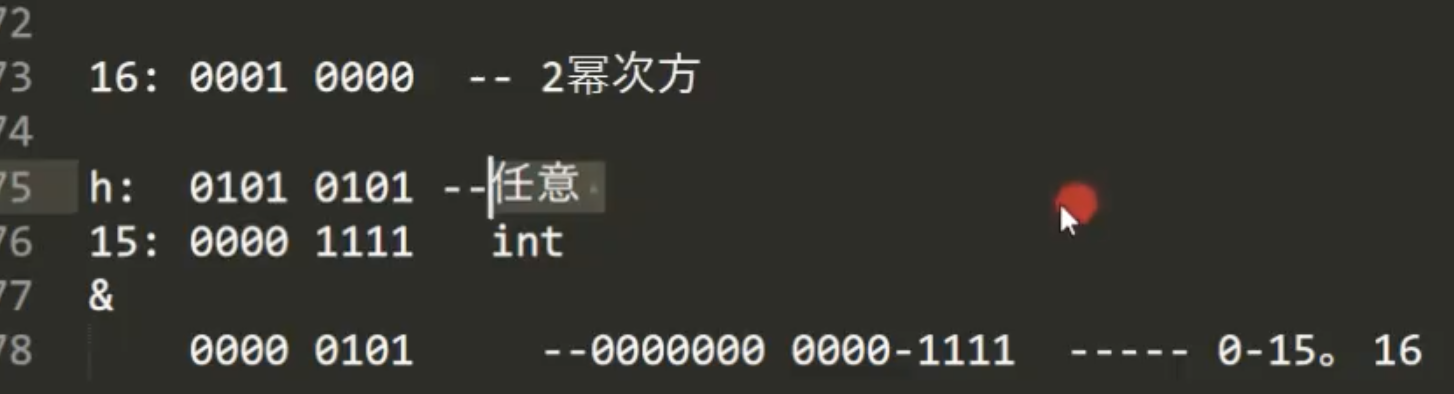
8.hash方法的右移和^运算的作用
为了让原本得到的hashcode高位数也参与到运算中,来保证散列,从而保证平均分布到数组上面。 反例,如果直接使用key的hashcode,那么如果重写了hashcode,那么可能比较单一,导致分布不均。
9.key为null的时候,特殊情况
key为null的时候,默认会存到数组的第一位,也就是角标为0的位置,由putForNullKey()函数完成
10.既然key为null,会落在第一位,那么第一位会有其他key吗?
会有的,如果通过hash方法算出来的index也为0,那么同样放在第一个数组链表上
11.add(index,e)方法,ArrayList和LinkendList 插入谁快?
不能单纯的一句数据结构来判断谁快谁慢,谁的效率高。 因为ArrayList定位虽然很快,但是需要将当前索引之后的往后移(耗费时间); 而LinkendList则时间花费在定位上面,插入很快 所以没有一个特定的说法,说谁快
12.hashMap扩容的条件?
- zise >= threshold
- 数组的当前索引位置上的元素不为null
13.在进行扩容的时候,扩容前后同一个数组元素上,有啥规律?
Node的头和尾部进行对调
14.在进行扩容的时候,为啥不直接数组上的第一个元素直接移动到新数组上,而是遍历?
因为扩容不仅仅是当前数组长度变大,同时也会把数组下的链表长度变短,从而加快get和put的效率;
15.多线程下为啥是不安全的?
多线程下,会导致HashMap在扩容的情况下,链表发生循环链表,且链表长度发生改变。当再次put或者get时候,发生死循环。 根因:在put的时候采用的是头插发,导致,第二个线程的两个局部指针发生变化
16.hash种子作用?
让得到的hash算法得到的hash值更加散列 默认的hash种子是0,当数组容量大于 [环境变量”jdk.map.althashing.threshold” ]的时候,hash种子会发生变化,来影响hash算法
17.如何避免hashmap扩容?
在知道map中大概要数量的时候,初始化的时候可以给定阈值,这样,可以避免扩容。
18.在hashmap循环中,删除key,为啥会报错?
根本原因是在迭代器遍历的时候,map的modCount和迭代器的exceptedModCount数值不一致导致抛出异常。因为插入和删除modCount都会++,而在遍历的时候,迭代器的exceptedModCount是初始化就固定的,但是再执行了remove操作之后,map的modCount发生改变,导致两者不一致,从而抛出异常。(调用迭代器的remove可以解决)
19.modCount的作用?
是一种快速容错机制,fast-fail 。因为本身hashmap就不是线程安全的容器,所以当有多个线程在同时操作hashmap的时候,就会报错。例如一个线程在读,另一个线程在写,就会提前报错。
20.扩容大小规律?
原来数组大小的2倍,且满足 数组长度为2的幂次方。
(1.7 ConcurrentHashMap[Segment数组 + HashEntry + 数组链表]) FAQ
1.ConcurrentHashMap,initialCapacity和concurrencyLevel含义?
initialCapacity:初始容量,默认为16, concurrencyLevel:Segment的数量,最大为 1 << 16 = 2 (默认为16)
2.ConcurrentHashMap是通过啥方式寻找到最近2的幂次方?
通过遍历 + 位移 找到
3.如何确定Segment下HashEntry数组的容量?
通过 initialCapacity / concurrencyLevel (并且向上取整)来计算出一个可以放的下所有容量的值c,之后因为同样需要散列均匀,所以和HashMap一样需要需使用2的幂次方,所以要找到 >= c的2的幂次方
4.在扩容的时候,是将Segment数组进行扩容吗?
不是,而是对Segment下的HashEntry数组进行扩容(局部扩容),Segment的长度一旦初始化确认,后面将不再进行改变
5.Segment0(Segment数组第一个位置的Segment)的作用?
为了给其他位置的Segment在第一次new的时候做参考,包括他的属性之类的。
6.Unsafe 类可以在应用里面的类中使用吗?
不可以:如下代码,只有当前类的类加载器是null,才可以使用。在应用里面的类加载器是App不为空,所以会报错。而在ConcurrentHashMap他的类加载器是Boot(启动类加载器),在java代码中是不能获取到的,返回的是null,所以可以使用
@CallerSensitivepublic static Unsafe getUnsafe() {Class var0 = Reflection.getCallerClass();if (!VM.isSystemDomainLoader(var0.getClassLoader())) {throw new SecurityException("Unsafe");} else {return theUnsafe;}}
7.描述Segment进行put的逻辑?
通过ReentrantLock来进行加锁,同时在拿不到锁的时候,scanAndLockForPut(),函数进行while重试,由于while比较消耗CPU,所以通过一些操作来,控制减缓while循环,并且通过【MAX_SCAN_RETRIES = Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1 】来确定何时上锁。
8.如何保证线程安全?
首先Segment数组不会进行扩容。 put:看代码。首先使用Unsafe的CAS拿到当前key对应的Segment,然后调用Segment的put方法,将当前KV插入到key对应的HashEntry,期间如果超过阈值,也会对HashEntry进行扩容,逻辑与HashMap一致,但是不会出现循环链表的情况,因为Segment继承了ReentrantLock,put操作时加了锁,保证了线程安全。
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
/**
* Scans for a node containing given key while trying to
* acquire lock, creating and returning one if not found. Upon
* return, guarantees that lock is held. UNlike in most
* methods, calls to method equals are not screened: Since
* traversal speed doesn't matter, we might as well help warm
* up the associated code and accesses as well.
*
* @return a new node if key not found, else null
*/
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
get:看代码。拿到Segment和put一样,接着拿到对应的HashEntry也是通过CAS机制,最后遍历链表,找到对应的key。
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
remove:看代码。拿到Segment和put一样,使用重入锁进行加锁,保证线程安全。
public V remove(Object key) {
int hash = hash(key);
Segment<K,V> s = segmentForHash(hash);
return s == null ? null : s.remove(key, hash, null);
}
final V remove(Object key, int hash, Object value) {
if (!tryLock())
scanAndLock(key, hash);
V oldValue = null;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> e = entryAt(tab, index);
HashEntry<K,V> pred = null;
while (e != null) {
K k;
HashEntry<K,V> next = e.next;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
V v = e.value;
if (value == null || value == v || value.equals(v)) {
if (pred == null)
setEntryAt(tab, index, next);
else
pred.setNext(next);
++modCount;
--count;
oldValue = v;
}
break;
}
pred = e;
e = next;
}
} finally {
unlock();
}
return oldValue;
}
/**
* Scans for a node containing the given key while trying to
* acquire lock for a remove or replace operation. Upon
* return, guarantees that lock is held. Note that we must
* lock even if the key is not found, to ensure sequential
* consistency of updates.
*/
private void scanAndLock(Object key, int hash) {
// similar to but simpler than scanAndLockForPut
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
int retries = -1;
while (!tryLock()) {
HashEntry<K,V> f;
if (retries < 0) {
if (e == null || key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f;
retries = -1;
}
}
}
9.size()方法逻辑?
看代码:首先要搞清楚,11行的for循环次数: 第一次:retries++ == RETRIES_BEFORE_LOCK 为false,sum = segment的修改次数,size = segment的下的总数,sum不等于last,last 赋值为 sum; 第二次:仍然不加锁,sum,size由于被重新置0,所以重新计算,此时比较last和新的sum,如果一致,说明修改次数是一样的。如果不一致继续第三次循环; 第三次:重复第二次操作。 第四次:此时retries++ == RETRIES_BEFORE_LOCK 为true,此时强制加锁进行统计,直到sum == last,返回size。
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
(1.8 HashMap[Node数组 + 链表/红黑树]) FAQ
1.为何1.8的hash算法不再像1.7那么复杂?
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}

若有收获,就点个赞吧
0 人点赞
