前言
并行编程势不可挡,Java从1.7开始就提供了Fork/Join 支持并行处理,在jdk8之后,进一步加强,并引入到Stream中
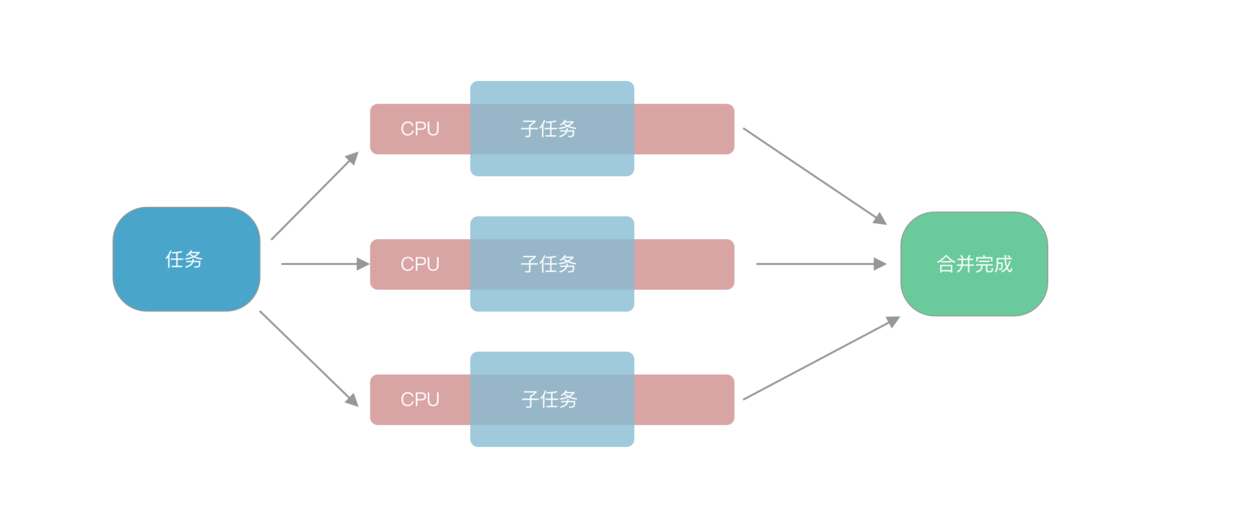
Fork/Join 处理就是将任务拆分子任务,分发给多个处理器同时处理,之后合并。
这是偷的图.png
ParallelStreams原理
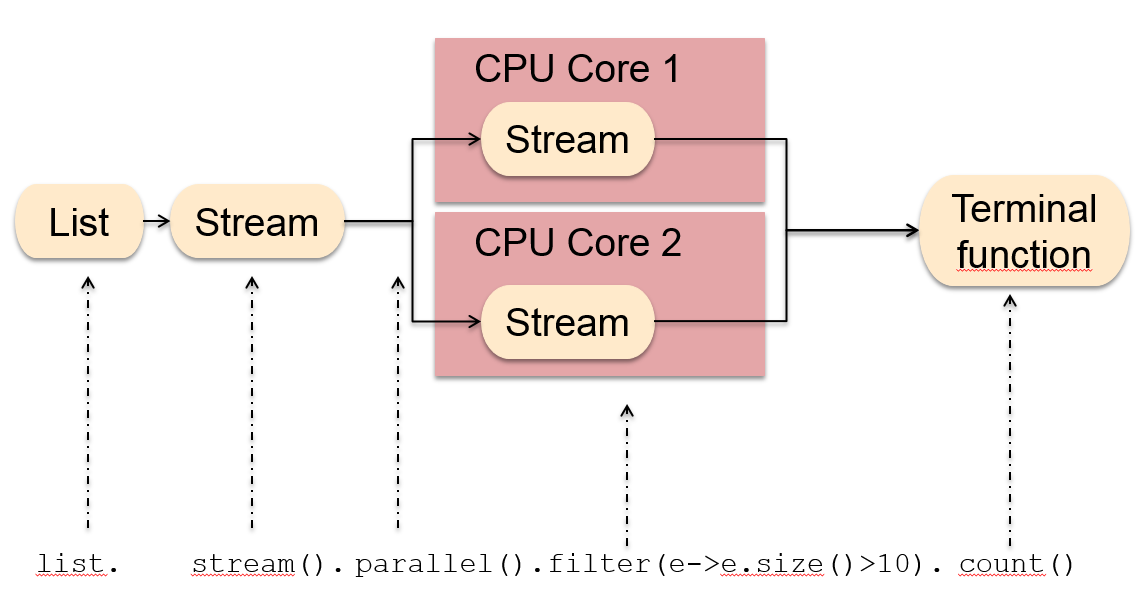
这也是偷的图.png
并行执行时,java将流划分为多个子流,分散在不同CPU并行处理,然后进行合并。
并行一定比串行更快吗?这不一定,取决于两方面条件:
在集合转Map的时候,使用toMap和groupingBy,partitioningBy等jdk自带的收集器,可以对list进行按照自定义的key,value组装,用起来十分方便,如下代码:
List<String> list = new ArrayList<>();list.stream().collect(Collectors.toMap(...));list.stream().collect(Collectors.groupingBy(...));
那么是否有必要使用并行流来执行呢,我之前以为有必要,可能会更快,但是今天打脸了🙃
我们来查看官网: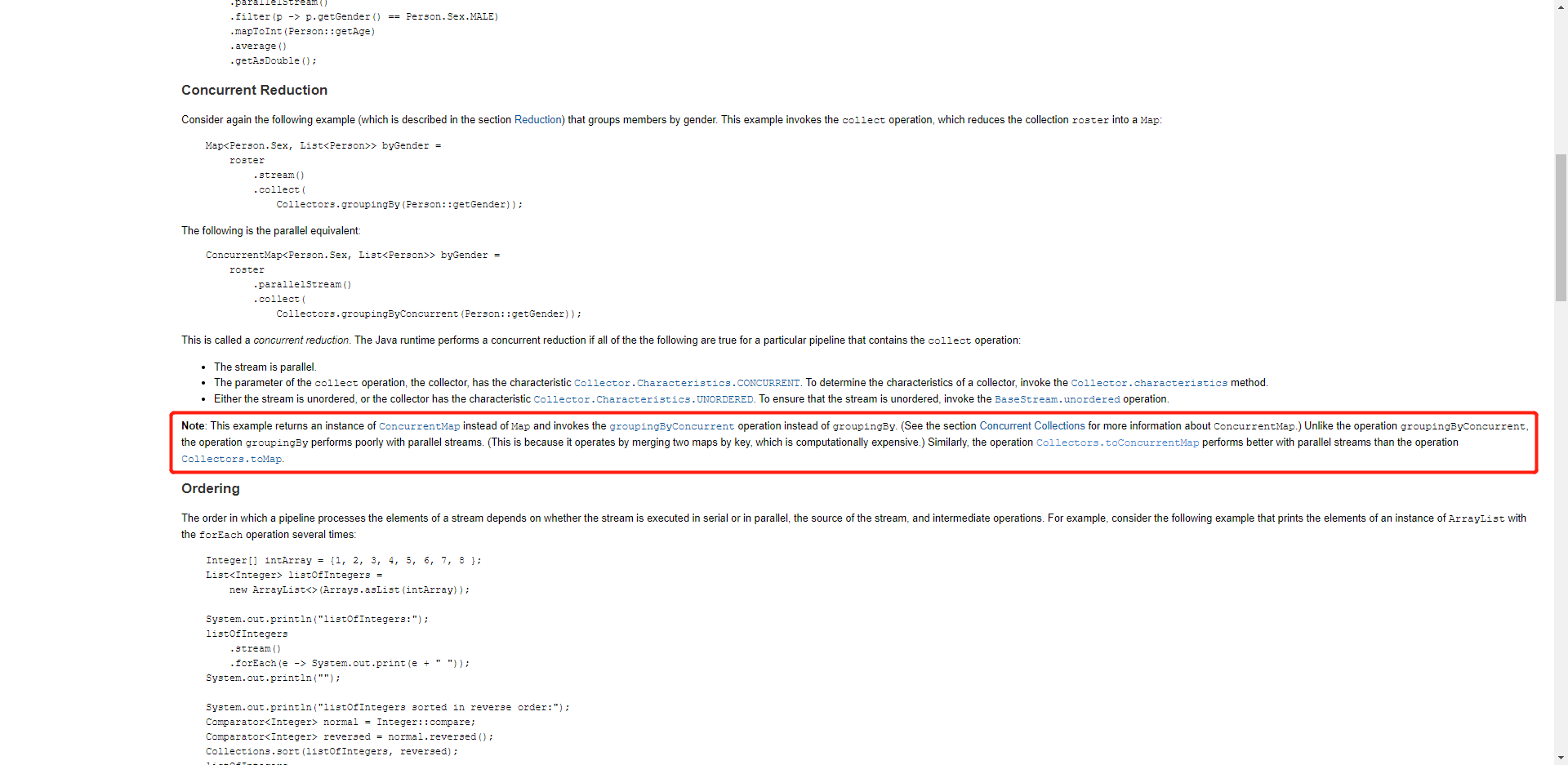
咔咔一顿翻译:
Note: This example returns an instance of
ConcurrentMapinstead ofMapand invokes thegroupingByConcurrentoperation instead ofgroupingBy. (See the section Concurrent Collections for more information aboutConcurrentMap.) Unlike the operationgroupingByConcurrent, the operationgroupingByperforms poorly with parallel streams. (This is because it operates by merging two maps by key, which is computationally expensive.) Similarly, the operationCollectors.toConcurrentMapperforms better with parallel streams than the operationCollectors.toMap.这个例子返回了ConcurrentMap来代替了Map,并且执行了groupingByConcurrent来代替groupingBy。(想了解更多关于ConcurrentMap,可以看并行集合的部分。) 和groupingByConcurrent不同的是,如果用并行流来执行groupingBy是低效率的(因为根据key来合并多个map,比较昂贵。)同理,用并行流执行Collectors.toConcurrentMap,要好于来执行Collectors.toMap。
也就是说在使用类似toMap和groupingBy将list组装成map的时候,使用并行流会更消耗资源,不推荐使用。如果想使用并行流,那么可以使用带“Concurrent”的对应函数,例如groupingByConcurrent,toConcurrentMap等等。
最后得出结论:
在使用集合的stream转Map的时候,两种方案:
- 在数据量不大的情况下,乖乖使用穿行流;
- 在数据量很大,并且多核CPU的时候:可使用并行流 + XXXConcurrent收集器来组装Map;
Tip:并行流直接toMap,groupingBy等会消耗额外的CPU资源,得不偿失,切记不要滥用!!也不要想当然的用!!

若有收获,就点个赞吧
0 人点赞
