1.基础代码
CREATE TABLE 数据表名(字段名1 数据类型[列级别约束条件],字段名2 数据类型[列级别约束条件],字段名3 数据类型[列级别约束条件]index 索引名(列名1,列名2...));
2.数据类型
| 类型 | 类型举例 |
|---|---|
| 整数类型 | INYINT、SMALLINT、MEDIUMINT、INT(INTEGER)和 BIGINT |
| TINYINT :一般用于枚举数据,比如系统设定取值范围很小且固定的场景。 SMALLINT :可以用于较小范围的统计数据,比如统计工厂的固定资产库存数量等。 MEDIUMINT :用于较大整数的计算,比如车站每日的客流量等 INT、INTEGER :取值范围足够大,一般情况下不用考虑超限问题,用得最多。比如商品编号。 BIGINT :只有当你处理特别巨大的整数时才会用到。比如双十一的交易量、大型门户网站点击量、证券公司衍生产品持仓等 |
|
| 浮点类型 | FLOAT、DOUBLE、REAL |
| FLOAT 表示单精度浮点数 DOUBLE 表示双精度浮点 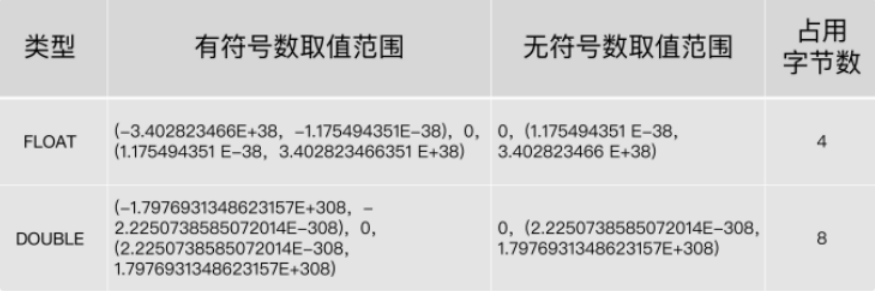 |
|
| 日期时间 | YEAR、TIME、DATE、DATETIME和TIMESTAMP |
| YEAR 类型通常用来表示年 DATE 类型通常用来表示年、月、日 TIME 类型通常用来表示时、分、秒 DATETIME 类型通常用来表示年、月、日、时、分、秒 TIMESTAMP 类型通常用来表示带时区的年、月、日、时、分、秒 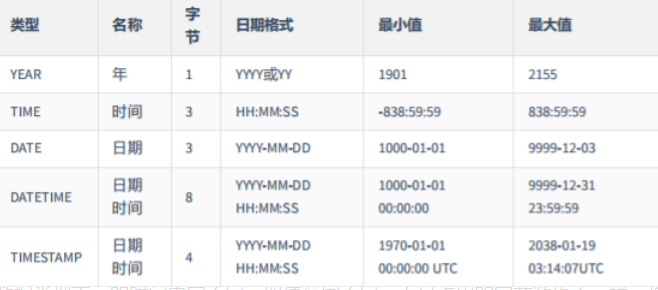 |
|
| 枚举类型 | ENUM |
| ```sql |
create table test( values ENUM(‘MEN’,’WOMEN’) ) — 如果是汉字字符集为utf8,否则会报错: Column ‘sex’ has duplicated value ‘?’ in ENUM
|| **json类型** | JSON || | 是一种轻量级的 数据交换格式 ```sqlCREATE TABLE test_json(js json);-- 向表中插入JSON数据。INSERT INTO test_json (js)VALUES (' {"name":"songhk","age" :18,"address":{"province":"beijing","city":"beiji
| | 集合类型 | SET | | | ```sql create table test(s set(‘A’,’B’,’C’)) — 像表中插入数据 insert into test_set (s) values(‘A’),(‘A,B’) — 插入重复的数据,自动删除重复的 insert into test_set (s) values(‘A’,’A’,’B’,’C’) — 插入不存在的会报错 insert into test_set (s) values(‘A,B,C,D’)
|| **文本类型** | CHAR 、 VARCHAR 、 TINYTEXT 、 TEXT 、MEDIUMTEXT 、 LONGTEXT || | <br />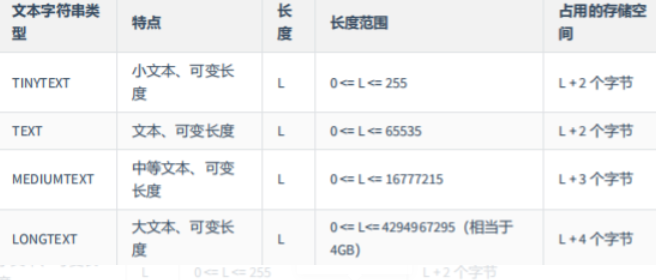 |<a name="E0DBm"></a>### 3.约束条件| **PRIMARY KEY ** | <br />1. 主**键,**当于 唯一约束 + 非空约束 的组合,主键约束列不允许重复,也不允许出现空值。<br />2. 每个表最多只允许一个主键,建立主键约束可以在列级别创建,也可以在表级别创建。<br />3. 当创建主键的约束时,系统默认会在所在的列和列组合上建立对应的唯一索引。<br />```sqlCREATE TABLE thinkgamer(id INT PRIMARY KEY);-- 符合主键使用例子CREATE TABLE thinkgamer(id INT,number INT,PRIMARY KEY(id,number));
|
| —- | —- |
| ** |
1. 非空,所有类型的值都可以时null,包括int,float 等数据类型
2. 当复制时,单引号’’ 或双引号”” 里什么都没有时,此时表示是0个字符,而不是null,因为nul表示没有赋值
```sql
CREATE TABLE thinkgamer(
id INT PRIMARY KEY,
sex ENUM(‘男’,’女’,’保密’) NOT NULL
)CHARSET=UTF8;
|| ** | <br />1. 自增约束(AUTO_INCREMENT)可以约束任何一个字段,该字段不一定是PRIMARY KEY字段,也就是说自增的字段并不等于主键字段。<br />2. 但是PRIMARY_KEY约束的主键字段,一定是自增字段,即PRIMARY_KEY 要与AUTO_INCREMENT一起作用于同一个字段。<br />3. 当插入第一条记录时,自增字段没有给定一个具体值,可以写成DEFAULT/NULL,那么以后插入字段的时候,该自增字段就是从1开始,没插入一条记录,该自增字段的值增加1。当插入第一条记录时,给自增字段一个具体值,那么以后插入的记录在此自增字段上的值,就在第一条记录该自增字段的值的基础上每次增加1。<br />4. 自增约束要设置在数值类型为整形的字段上,且字段时主键,外键,唯一键的一种<br />```sqlCREATE TABLE thinkgamer(id INT PRIMARY KEY AUTO_INCREMENT,sex ENUM('男','女','保密') NOT NULL)CHARSET=UTF8;
|
| ** |
1. 值唯一,唯一约束是指定table的列或列组合不能重复,保证数据的唯一性。
2. 唯一约束不允许出现重复的值,但是可以为多个null。
3. 同一个表可以有多个唯一约束,多个列组合的约束
```sql
— 方法一:
CREATE TABLE thinkgamer(
id INT PRIMARY KEY AUTO_INCREMENT,
sex ENUM(‘男’,’女’,’保密’) NOT NULL,
name VARCHAR(20) UNIQUE
)CHARSET=UTF8;
— 方法二:
create table class2(id int ,name char(20), unique(id));
|| ** | <br />1. 外键,用来加强两个表(主表和从表)的一列或多列数据之间的连接的,可以保证一个或两个表之间的参照完整性,外键是构建于一个表的两个字段或是两个表的两个字段之间的参照关系。<br />2. 创建外键约束的顺序是先定义主表的主键,然后定义从表的外键。也就是说只有主表的主键才能被从表用来作为外键使用,被约束的从表中的列可以不是主键,主表限制了从表更新和插入的操作。<br />3. 主表和从表关联的字段要具有相同的数据类型,字符长度,参数类型<br />4. 只有当主表中主键字段存在某个数值,从表的才可以添加相应的表记录<br />5. 主表删除时表记录时,如果该项数值在从表中被使用,则需要先将从表中的占用删除,才可以在主表中删除相应的表记录<br />```sql--创建表project,并设置 id 字段为 主键create table project(id int primary key,subject char(30));--创建表class,设置id 字段为主键,设置fail 字段为外键,关联到project表的id 字段。并且,同步更新,同步删除create table class-> (id int primary key,-> name char(20),-> fail int,-> foreign key(fail) references project(id)-> on update cascade-> on delete cascade );
|
| DEFAULT |
1. 默认值,若在表中定义了默认值约束,用户在插入新的数据行时,如果该行没有指定数据,那么系统将默认值赋给该列,如果我们不设置默认值,系统默认为NULL。
2. 设置默认值的字段,默认值的类型必须和字段的值类型一样
```sql
CREATE TABLE thinkgamer(
id INT PRIMARY KEY AUTO_INCREMENT,
sex ENUM(‘男’,’女’,’保密’) NOT NULL,
name VARCHAR(20) UNIQUE,
age INT DEFAULT 20
)CHARSET=UTF8;
|<a name="JUnUz"></a>### 4.索引<a name="GGAH6"></a>#### 1.概念索引时一个排序的列表,在这个列表中的值存储着索引的值和包含这个值的数据所在行的物理地址<br />使用索引后,可以不用扫描全表来定位某行数据,而是先通过索引表找到改行数据对饮的物理地址,然后访问相应的数,加快数据库的查询速度<br />索引可以类比为书籍的目录,可以根据目录中的页码来快速找到所需的内容。<br />索引时表中一列过着若干列值排序的方法<br />建立索引的目的是加快表记录的查找或排序<a name="lRs4V"></a>#### 2 索引项和索引值索引项是数据库里面的table 中的字段;<br />索引值是字段里面存储的数据(值)<a name="bSnwE"></a>#### 3 索引的作用与副作用索引的作用<br /> 索引主要有两个作用,加快搜索速度和排序<br />索引的副作用<br />索引需要占用额外的磁盘空间<br />在插入和修改数据时,需要花费更多的时间,因为索引也要随之改动<a name="B0Enl"></a>#### 4. 建立索引的原则依据索引随可以提升数据库查询的速度,但并不是任何情况下都适合创建索引。因为索引本身会消耗系统资源,在有索引的情况下,数据库会先进行索引查询,然后定位到具体的数据行,如果索引使用不当,反而会增加数据库的负担。<br />表的主键、外键必须有索引。因为主键具有唯一性,外键关联的是子表的主键,查询时可以快速定位。<br />记录数超过300行的表应该有索引。如果没有索引,需要把表遍历一遍,会严重影响数据库的性能。<br />经常与其他表进行连接的表,在连接字段上应该建立索引。<br />唯一性太差的字段不适合建立索引。<br />更新太频繁地字段不适合创建索引。<br />经常出现在 where 子句中的字段,特别是大表的字段,应该建立索引。<br />在经常进行 GROUP BY、OPDER BY 的字段上建立索引<br />索引应该建在选择性高的字段上。<br />索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引。<br />在读比较多的表,适合建立索引。<a name="KfG5F"></a>#### 5 数据库查询的过程在有索引的情况下,数据库会先进行索引查询,然后定位到具体的数据行<br />没有有索引的情况下扫描全表来定位某行的数据<a name="ZARxF"></a>#### 6 索引的分类索引有普通索引,唯一索引,主键索引,外键索引,组合索引,全文索引。<br />唯一键约束就是唯一索引(unique key),<br />主键索引(primary key),外键索引(foreign key) ,在创建主键约束,外键约束时候,会自动创建<a name="hajtK"></a>#### 7 创建普通索引```sql--创建表的时候,为score 字段设置索引create table class(id int, name char(30),score int ,index class_score_index(score));--修改表的方式,为name 字段创建索引alter table class add index class_name_index(name);--直接为class表id 字段创建索引create index class_id_index on class(id);
8.创建全文索引
-- 方法一:直接创建全文索引create fulltext index 索引名 on 表名(列名);-- 方法二: 创建表时候指定索引create table 表名(字段名 数据类型 ..... ,fulltext 索引名(字段名));-- 方法三: 修改表方式创建alter table 表名 add fulltext 索引名 on 表名(字段名);
create table class(id int,name char(30),-> tel bigint ,-> address varchar(50),-> info varchar(100),-> fulltext textindex(info));

9.模糊查询
select * from 表名 where match(字段名) against('匹配内容');-- 插入三条表记录insert into class values (1,'zhangsan',1010110,'china','this is vip'),(2,'lisi',1010110,'china','this is super vip'),(3,'wangwu',1010110,'china','this is vvip');-- 在clss 表的info 字段,查询匹配 ‘vip’ 的表记录select * from class where match(info) against('vip');

10.6 查看索引
show index from 表名;show key from 表名;-- 举例show index from class \G
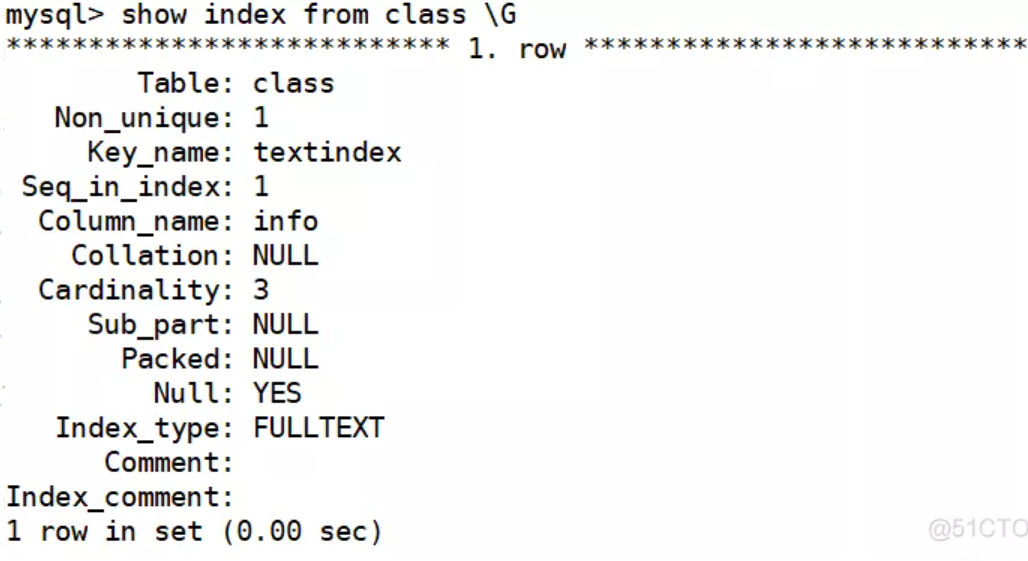
| Table | 表的名称 |
|---|---|
| Non_unique | 如果索引不能包括重复词,则为 0;如果可以,则为 1 |
| Key_name | 索引的名称 |
| Seq_in_index | 索引中的列序号,从 1 开始 |
| Column_name | 列名称 |
| Collation | 列以什么方式存储在索引中。在 MySQL 中,有值‘A’(升序)或 NULL(无分类) |
| Cardinality | 索引中唯一值数目的估计值 |
| Sub_part | 如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,为 NULL |
| Packed | 指示关键字如何被压缩。如果没有被压缩,则为 NULL |
| Null | 如果列含有 NULL,则含有 YES。如果没有,则该列含有 NO |
| Index_type | 用过的索引方法(BTREE, FULLTEXT, HASH, RTREE) |
| Comment | 备注 |
10.删除索引
直接删除索引drop index 索引名 on 表名;修改表的方式删除索引alter table 表名 drop index 索引名;删除主键索引alter table 表名 drop primary key-- 举例#查看表的详细信息,获取索引名show create table class \G


若有收获,就点个赞吧
0 人点赞
