GC 周期的不同阶段
GC 主要包含三个阶段,其对应的写屏障状态如下表所示:
| 阶段 | 写屏障 |
|---|---|
| GCoff | 关闭 |
| GCmark | 启用 |
| GCmarktermination | 启用 |
当需要进行 GC 阶段切换时,主要就只是控制 gcphase 和 writeBarrier 这两个变量,实现也比较简单:
const (
_GCoff = iota // GC 没有运行,sweep 在后台运行,写屏障没有启用
_GCmark // GC 标记 roots 和 workbufs: 分配黑色,写屏障启用
_GCmarktermination // GC 标记终止: 分配黑色, P’s 帮助 GC, 写屏障启用
)
//go:nosplit
func setGCPhase(x uint32) {
atomic.Store(&gcphase, x) // *gcphase = x
// 只有 mark 和 marktermination 才需要写屏障
writeBarrier.needed = gcphase == _GCmark || gcphase == _GCmarktermination
// 只有需要或者 cgo 时候才启用写屏障
writeBarrier.enabled = writeBarrier.needed || writeBarrier.cgo
}
在运行时代码中,阶段切换的标记非常明确:
- 在 gcStart 时,切换到 Mark 标记阶段;
- 当标记工作完成时候切换到 MarkTermination 阶段,并在完成标记后切换到 Off 阶段,停用写屏障。
// src/runtime/mgc.go
func gcStart(trigger gcTrigger) {
systemstack(stopTheWorldWithSema) // STW 开始
setGCPhase(_GCmark)
systemstack(func() {
now = startTheWorldWithSema(trace.enabled) // STW 结束
})
…
}
func gcMarkDone() {
systemstack(stopTheWorldWithSema) // STW 开始
…
}
func gcMarkTermination(nextTriggerRatio float64) {
setGCPhase(_GCmarktermination)
systemstack(func() {
setGCPhase(_GCoff)
}
systemstack(func() { startTheWorldWithSema(true) }) // STW 结束
…
}
在这三个主要的阶段切换中,都伴随着 STW 操作,为了叙述方便,我们以 STW 为界限,将 GC 划分为五个阶段:
| 阶段 | 说明 | 状态 |
|---|---|---|
| GCMark | 标记准备阶段,为并发标记做准备工作,启用写屏障 | STW |
| GCMark | 扫描标记阶段,与赋值器并发执行 | 并发 |
| GCMarkTermination | 标记终止阶段,保证一个周期内标记任务完成,关闭写屏障 | STW |
| GCoff | 内存清扫阶段,将需要回收的内存归还到堆中 | 并发 |
| GCoff | 内存归还阶段,将过多的内存归还给操作系统 | 并发 |
接下来我们来关注进入 STW 和退出 STW 时的具体实现。
STW 的启动
STW 要确保所有被调度器调度执行的用户代码停止执行,一个可行的方案就是让所有的 M 与其关联的 P 解除绑定, 这样 M 便无法再继续执行用户代码了。
func stopTheWorldWithSema() {
g := getg()
lock(&sched.lock)
// 停止调度器需要停止的线程数
sched.stopwait = gomaxprocs
// 设置因 GC 需要停止调度器的标志位
atomic.Store(&sched.gcwaiting, 1)
// 抢占所有当前执行的 G
preemptall()
// 停止当前 G 所在的的 P,这时需要解绑的数量少了一个
g.m.p.ptr().status = Pgcstop // Pgcstop 只用于诊断.
sched.stopwait—
// 抢占所有在系统调用 Psyscall 状态的 P
for , p := range allp {
s := p.status
if s == _Psyscall && atomic.Cas(&p.status, s, _Pgcstop) {
p.syscalltick++
sched.stopwait—
}
}
// 抢占所有空闲的 P,防止再次被抢走
for {
p := pidleget()
if p == nil {
break
}
p.status = _Pgcstop
sched.stopwait—
}
wait := sched.stopwait > 0
unlock(&sched.lock)
// 等待剩余的无法被抢占的 P 主动停止
if wait {
for {
// 等待 100us, 然后尝试重新抢占,从而防止竞争
if notetsleep(&sched.stopnote, 100*1000) {
noteclear(&sched.stopnote)
break
}
preemptall()
}
}
…
}
func preemptall() bool {
res := false
for , _p := range allp {
// 尝试抢占所有处于运行状态的 P
if p.status != Prunning {
continue
}
if preemptone(_p) {
res = true
}
}
return res // 至少成功了一个
}
func preemptone(p *p) bool {
mp := p.m.ptr()
if mp == nil || mp == getg().m {
return false
}
gp := mp.curg
if gp == nil || gp == mp.g0 {
return false
}
// 设置抢占标记
// goroutine 中的每个调用都会通过比较当前栈指针和 gp.stackgard0 来检查栈是否溢出。
// 设置 gp.stackgard0 为 StackPreempt 来将抢占转换为正常的栈溢出检查。
gp.preempt = true
gp.stackguard0 = stackPreempt
return true
}
这样来看其实 STW 的逻辑很简单:
- 尝试为每个处于运行状态 (
_Prunning) 的 P 上的 goroutine 设置抢占标记,这样所有正在运行的 G 在发生进一步函数调用时,会主动被抢占 - 抢占所有正在进行系统调用状态(
_Psyscall)时还来不及被抢夺的 P - 抢占所有处于空闲状态尚未被 M 绑定的 P
- 等待所有的 P 都与 M 成功解绑。
STW 的结束
当要结束 STW 阶段时,无非就是唤醒调度器,即唤醒已经处于休眠状态的 M,重新开始调度 G。
func startTheWorldWithSema(emitTraceEvent bool) int64 {
mp := acquirem()
// 优先处理网络数据
if netpollinited() {
list := netpoll(false) // 非阻塞
injectglist(&list)
}
lock(&sched.lock)
// 处理 P 的数量调整
procs := gomaxprocs
if newprocs != 0 {
procs = newprocs
newprocs = 0
}
p1 := procresize(procs)
// 调度器可以开始调度了
sched.gcwaiting = 0
// 唤醒系统监控
if sched.sysmonwait != 0 {
sched.sysmonwait = 0
notewakeup(&sched.sysmonnote)
}
unlock(&sched.lock)
// 依次将 m 唤醒,并绑定到 p,开始执行
for p1 != nil {
p := p1
p1 = p1.link.ptr()
if p.m != 0 {
mp := p.m.ptr()
p.m = 0
(…)
mp.nextp.set(p)
notewakeup(&mp.park)
} else {
// 运行 M 并运行 P. 下面不会创建一个新的 M
newm(nil, p)
}
}
// 记录 STW 结束时间
startTime := nanotime()
(…)
// 如果我们在本地队列或全局队列中有过多的可运行的 goroutine,则唤醒一个额外的 proc。
// 如果我们不这样做,那么过程就会停止。
// 如果我们有大量过多的工作,重新设置将取消必要的额外过程。
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 {
wakep()
}
releasem(mp)
return startTime
}
这个逻辑也很直接:
- 网络数据优先级最高,优先确定需要处理的网络数据
- 其次唤醒系统监控
- 最后再依次唤醒 M,将其绑定 P,并重新开始调度 G
GC 的启动
TODO:
func gcStart(trigger gcTrigger) {
// 不要尝试在非抢占或可能不稳定的情况下(m 被锁)启动 GC。
mp := acquirem()
if gp := getg(); gp == mp.g0 || mp.locks > 1 || mp.preemptoff != “” {
releasem(mp)
return
}
releasem(mp)
mp = nil
// 记录已经启动的 sweeper 数量
for trigger.test() && sweepone() != ^uintptr(0) {
sweep.nbgsweep++
}
// 执行 GC 初始化,以及 sweep 终止转换 termination transition
semacquire(&work.startSema)
// 在持有锁的情况下 重新检查转换条件,若不需要触发则不触发
if !trigger.test() {
semrelease(&work.startSema)
return
}
// 对于统计信息,请检查用户是否强制使用此 GC。
work.userForced = trigger.kind == gcTriggerCycle
(…)
semacquire(&worldsema) // 无法抢到 worldsema 的其他人,会在此阻塞
标记准备阶段
func gcStart(trigger gcTrigger) {
(…)
mode := gcBackgroundMode
(…)
// 进入标记阶段前的准备工作
// 启动 mark workers
gcBgMarkStartWorkers()
// 重置 mark 状态
systemstack(gcResetMarkState)
// 记录此次 GC 时 STW 的各项信息,用于计算下一次 GC 周期的触发时间
work.stwprocs, work.maxprocs = gomaxprocs, gomaxprocs
if work.stwprocs > ncpu {
work.stwprocs = ncpu
}
work.heap0 = atomic.Load64(&memstats.heap_live)
work.pauseNS = 0
work.mode = mode
now := nanotime()
work.tSweepTerm = now
work.pauseStart = now
(…)
// ————————- 正式 STW ———————————
systemstack(stopTheWorldWithSema)
systemstack(func() {
finishsweep_m() // 等待 sweeper 完成,确保所有 span 已被清除
})
(…)
// 记录 GC 周期
work.cycles++
// 重置 GC controller 的状态,用于估计下一次 GC 的触发时间
gcController.startCycle()
work.heapGoal = memstats.next_gc
(…)
// 进入并发标记阶段并启用写障碍。
// 因为世界已经停止,所有 Ps 都会观察到,当我们开始世界并开始扫描时,写入障碍就会被启用。
// 写屏障必须在 assists 之前启用,因为必须在标记任何非叶堆对象之前启用它们。
// 由于分配被阻止直到 assists 可能发生,我们希望尽早启用 assists。
setGCPhase(_GCmark)
gcBgMarkPrepare() // 必须 happen before assist enable.
gcMarkRootPrepare()
// 标记所有活动的 tinyalloc 块。由于我们从这些分配,他们需要像其他分配一样黑。
// 另一种方法是在每次分配时使小块变黑,这会减慢 tiny allocator。
gcMarkTinyAllocs()
// 此时所有 Ps 都启用了写入屏障,从而保持了无白色到黑色的不变性。
// 启用 mutator 协助对快速分配 mutator 施加压力。
atomic.Store(&gcBlackenEnabled, 1)
// 记录标记开始的时间
gcController.markStartTime = now
systemstack(func() {
now = startTheWorldWithSema(trace.enabled)
work.pauseNS += now - work.pauseStart
work.tMark = now
})
// ————————- 结束 STW ———————————-
(…)
semrelease(&work.startSema)
}
//go:nowritebarrier
func finishsweep_m() {
// Sweeping must be complete before marking commences, so
// sweep any unswept spans. If this is a concurrent GC, there
// shouldn’t be any spans left to sweep, so this should finish
// instantly. If GC was forced before the concurrent sweep
// finished, there may be spans to sweep.
for sweepone() != ^uintptr(0) {
sweep.npausesweep++
}
nextMarkBitArenaEpoch()
}
TODO: 后台标记
// gcBgMarkStartWorkers 准备后台标记 worker goroutines。
// 这些 goroutine 直到标记阶段才会运行,但它们必须在工作未停止时从常规 G 栈启动。调用方必须持有 worldsema。
func gcBgMarkStartWorkers() {
// 后台 mark 分别每个 P 上执行。确保每个 P 都有一个后台 GC G
for _, p := range allp {
if p.gcBgMarkWorker == 0 {
go gcBgMarkWorker(p) // 启动一个 goroutine 来运行 mark worker
notetsleepg(&work.bgMarkReady, -1) // 休眠,直到 gcBgMarkWorker 就绪
noteclear(&work.bgMarkReady) // 这时启动继续启动下一个 Worker
}
}
}
func gcBgMarkWorker(p *p) {
gp := getg()
type parkInfo struct {
m muintptr // Release this m on park.
attach puintptr // If non-nil, attach to this p on park.
}
// We pass park to a gopark unlock function, so it can’t be on
// the stack (see gopark). Prevent deadlock from recursively
// starting GC by disabling preemption.
gp.m.preemptoff = “GC worker init”
park := new(parkInfo)
gp.m.preemptoff = “”
park.m.set(acquirem())
park.attach.set(p)
// Inform gcBgMarkStartWorkers that this worker is ready.
// After this point, the background mark worker is scheduled
// cooperatively by gcController.findRunnable. Hence, it must
// never be preempted, as this would put it into _Grunnable
// and put it on a run queue. Instead, when the preempt flag
// is set, this puts itself into _Gwaiting to be woken up by
// gcController.findRunnable at the appropriate time.
notewakeup(&work.bgMarkReady)
(…)
}
func gcBgMarkPrepare() {
work.nproc = ^uint32(0)
work.nwait = ^uint32(0)
}
//go:nowritebarrier
func gcMarkRootPrepare() {
work.nFlushCacheRoots = 0
// Compute how many data and BSS root blocks there are.
nBlocks := func(bytes uintptr) int {
return int((bytes + rootBlockBytes - 1) / rootBlockBytes)
}
work.nDataRoots = 0
work.nBSSRoots = 0
// 扫描全局变量
for _, datap := range activeModules() {
nDataRoots := nBlocks(datap.edata - datap.data)
if nDataRoots > work.nDataRoots {
work.nDataRoots = nDataRoots
}
}
for _, datap := range activeModules() {
nBSSRoots := nBlocks(datap.ebss - datap.bss)
if nBSSRoots > work.nBSSRoots {
work.nBSSRoots = nBSSRoots
}
}
// Scan span roots for finalizer specials.
//
// We depend on addfinalizer to mark objects that get
// finalizers after root marking.
//
// We’re only interested in scanning the in-use spans,
// which will all be swept at this point. More spans
// may be added to this list during concurrent GC, but
// we only care about spans that were allocated before
// this mark phase.
work.nSpanRoots = mheap.sweepSpans[mheap.sweepgen/2%2].numBlocks()
// Scan stacks.
//
// Gs may be created after this point, but it’s okay that we
// ignore them because they begin life without any roots, so
// there’s nothing to scan, and any roots they create during
// the concurrent phase will be scanned during mark
// termination.
work.nStackRoots = int(atomic.Loaduintptr(&allglen))
work.markrootNext = 0
work.markrootJobs = uint32(fixedRootCount + work.nFlushCacheRoots + work.nDataRoots + work.nBSSRoots + work.nSpanRoots + work.nStackRoots)
}
func gcMarkTinyAllocs() {
for , p := range allp {
c := p.mcache
if c == nil || c.tiny == 0 {
continue
}
, span, objIndex := findObject(c.tiny, 0, 0)
gcw := &p.gcw
greyobject(c.tiny, 0, 0, span, gcw, objIndex)
}
}
// gcBlackenEnabled 如果 mutator assists 和 background mark worker 被允许 blacken 对象。
// 它只有在 gcphase == _GCmark 时才被设置
var gcBlackenEnabled uint32
小结
TODO: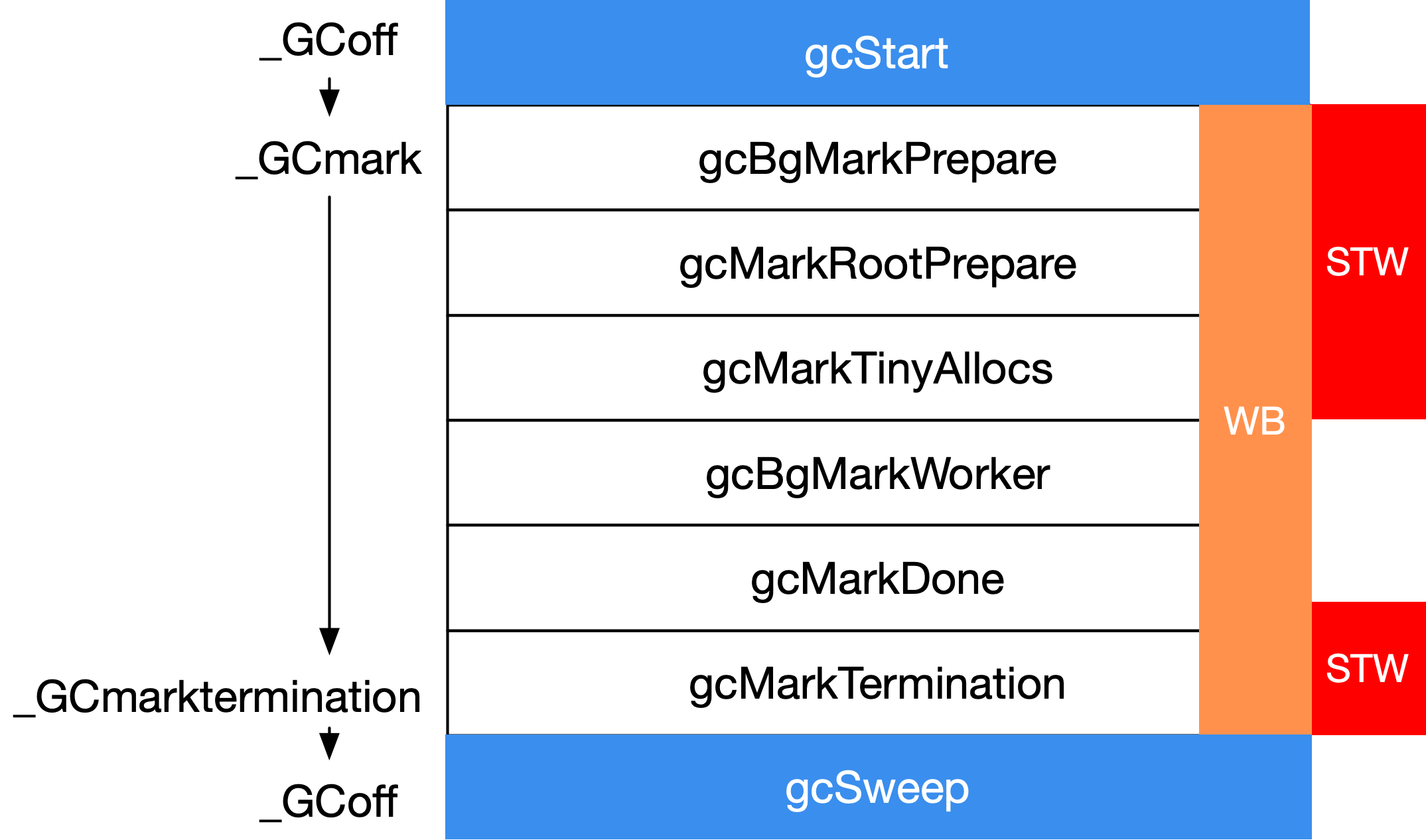
图 1: 垃圾回收器各阶段总览

若有收获,就点个赞吧
0 人点赞
