DataFrame是对RDD的封装,增加了结构化信息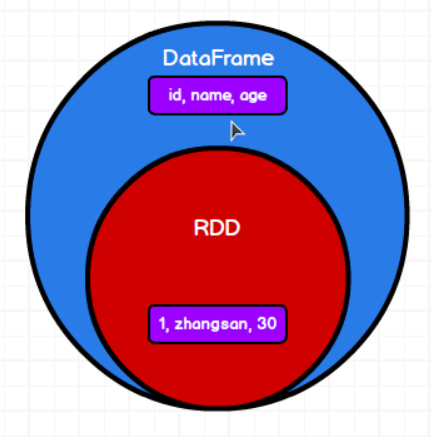
Json字符串:
JavaScript Object Notation
eg: var obj = {“name”: “zhangsan”, “age”: 20}
var objs = [{“name”: “zhangsan”, “age”: 20}]
(上面两个例子都是Json)
AJAX + JSON => 前端技术
视图(view):一个查询结果集
从DataFrame转回RDD时RDD的存储类型是Row
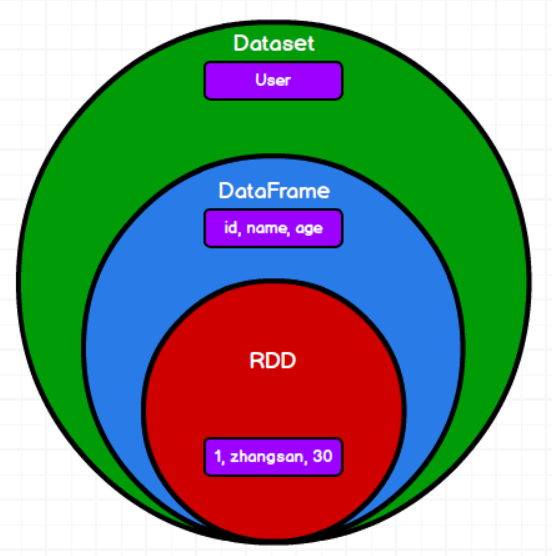
Dataset是强类型的数据集合
RDD转换样例类,然后toDS方法就可以转为Dataset
Dataset转RDD直接调用rdd方法
DataFrmae转Dataset时使用as[样例类]
Dataset转DataFrame使用toDF
JSON文件要求文件整体格式符合JSON要求
SparkSQL底层是SparkCore,SparkCore读取文件使用的是Hadoop
所以Spark中要求JSON文件中每一行符合JSON格式即可(IDEA提示有错也没事)
在使用特殊操作时,需要隐式转换操作的,这个隐式转换在shell窗口自动导入,所以可以直接使用
在当前环境中,没有自动引入这些隐式转换,所以会报错,需要引入 import spark.implicits._
import 关键字可以导入对象的方法,这个对象的声明必须是 val ,不能是 var
这里的spark不是包名,是对象名(import spark.implicits._ )
DataFrame & Dataset
type DataFrame = Dataset[Row]
Dataset[Person] => RDD[Person]
DataFrame => RDD[Row] 相当于:
DataFrame = Dataset[Row] => RDD[Row]
DataFrame其实就是Dataset,只不过是特定类型的Dataset(Row类型)
sql语句中早期版本只支持弱类型的聚合函数,不支持强类型的聚合函数
在Spark3.0版本后,可以通过特殊操作,将强类型转换为弱类型
UDAF(用户自定义聚合函数)是弱类型的, UserDefinedAggregateFunction(3.0.0版本被标为废弃)
Aggregator是强类型的(3.0.0版本用于替代UserDefinedAggregateFunction)
(Java中一次性只能做32位的操作,所以long和double都是64位的,就要分2次进行操作,不是原子性的)
早期版本的Spark无法将强类型的聚合函数应用在SQL文中
强类型聚合函数在早期版本中使用DSL方式来操作
强类型聚合函数可以转换为查询列进行操作
行式存储有利于查询,不利于统计
列式存储有利于统计,不利于查询
(parquet格式文件是列存储)

若有收获,就点个赞吧
0 人点赞
