文档:03_尚硅谷大数据技术之SparkStreaming.docx
从数据处理的延迟的角度:
- 离线数据:处理的数据的延迟以分钟、小时为单位
- 准实时数据:处理的数据的延迟以秒为单位
- 实时数据:处理的数据的延迟以毫秒为单位
从数据处理的方式的角度:
- 流式数据:读取一条数据就处理一条数据
- 微批次数据:缓存一部分数据,一块进行处理
- 批量数据:缓存一部分数据,一块进行处理
Spark:离线数据 + 批量数据
SparkStreaming:准实时数据 + 微批次数据
SparkStreaming是基于RDD的
从socket中获取的数据是一行一行的字符串
SparkStreaming中不能在Driver程序中执行stop方法,太暴力了,直接停掉,不管执行结束与否,改用文档中优雅的关闭方式
需要启动采集器: ssc.start()
Driver需要等待采集器的结束: ssc.awaitTermination()awaitTermination()会阻塞主线程的运行

可以监听目录
但是不稳定,没啥人用
没办法监听旧文件,新的文件有时候也监听不到
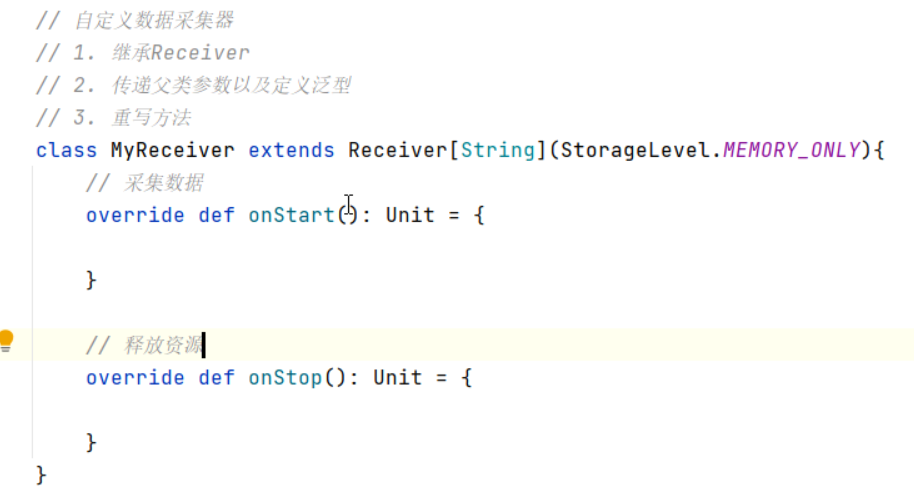
自定义数据采集器详细代码去Spark代码示例 -> Spark自定义组件中去找
kafka传输数据以KV形式传输,有key才能做分区
离散化流无法排序,可以将DStream转换为RDD进行排序 (transform原语)
- 原语:DStream对象的方法
- 算子:RDD对象的方法
- 方法:Scala对象的方法

要进行周期性操作不能直接通过原语实现,必须要通过DStream转RDD的方式同时在原语中,算子外方式调用,即途中注释(周期性执行)的地方
buffer放在检查点中,在磁盘上或在分布式文件系统上(如HDFS),用之前需要设置检查点(不推荐使用,小文件太多)推荐使用Redis保存每次的结果
object SparkStreaming08_State {def main(args: Array[String]): Unit = {// TODO 创建环境对象val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkStreaming")val ssc = new StreamingContext(sparkConf, Seconds(3))// buffer放在检查点中,在磁盘上或在分布式文件系统上(如HDFS),用之前需要设置检查点// 不推荐使用,小文件太多,推荐使用Redis保存每次的结果ssc.checkpoint("cp")// 从socket中获取的数据是一行一行的字符串val socketDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)//val wordToCount = socketDS.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)val mapDS : DStream[(String, Int)] = socketDS.flatMap(_.split(" ")).map((_,1))// updateStateByKey方法需要传递参数,这个参数的类型为函数类型// 函数类型中输入有两个参数// seq : Seq[Int], 将相同的key的value放置在seq集合中// opt : Option[Int]// The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().val stateDS = mapDS.updateStateByKey((seq:Seq[Int], buffer:Option[Int]) => {val oldCnt = buffer.getOrElse(0)val newCnt = oldCnt + seq.sumOption(newCnt)})stateDS.print()ssc.start()ssc.awaitTermination()}}
窗口的大小必须为采集周期的整数倍
窗口滑动时大小也必须为采集周期的正数倍
窗口统计的是窗口内的数据
窗口范围大,滑动幅度小,会存在大量的重复数据
窗口范围小,滑动幅度大,不会存在大量的重复数据,甚至没有重复数据
(所有的连接对象都是不能序列化的)
线程间控制最好使用第三方中间件(比如HDFS有没有某个文件或路径、ZooKeeper有没有某个节点等)

若有收获,就点个赞吧
0 人点赞
