王昊老师:
- 每个Topic分为多个分区partition,配合分区设计,提出消费者组的概念,组内每个消费者并行消费;一个分区只能对应一个消费者,但是允许多个分区对应一个消费者;不同消费者组完全是独立的
- 副本数不能高于节点数;broker之间不分主从,是去中心化的,依赖ZooKeeper来协调;分区之间分主从;分区数与节点数没什么关系,硬要在一台机器上分多个区也可以
- 修改文档


全部落盘指的ISR中所有的全部落盘- leader发ack给producer只会发HW(High WaterMark)之前的ack,HW到LEO之间的不会发ack
- f(f(x)) = f(x) —> 幂等性
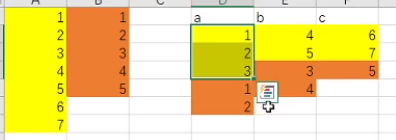 range策略容易数据倾斜
range策略容易数据倾斜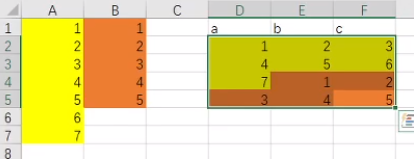 RoundRobin策略
RoundRobin策略- 内部话题:
1. consumer_offsets:记录consumer消费的状态(offset)(0.9版本之后)
2. transaction_states:记录transaction(事务)的状态 
- consumer端事务基本是没有的,只有精准一次性消费,但是没办法回滚,因为资源可能删除了
Consumer精准一次性消费一般用两种方式:
- 手动提交偏移量 + 幂等性处理
- 事务:把偏移量offset保存到支持事务的数据库中
**
- 围绕两个点:安全+性能
童威给的视频:
分布式和集群的区别:
分布式指的是不同人做不同的事
集群指的是不同人做相同的事
Hadoop是分布式集群:其中分布式指的是NameNode和SecondaryNameNode做的事情不一样;集群指的是DataNode做的事一样
每个分区对应一个batch,不同producer给同一分区发送数据时共用同一个batch
broker之间也会找一个Controller出来(不是主从关系),帮助分区选举leader和follower(0.9之前这个事情是ZooKeeper来做的)
Sticky分配策略的原理比较复杂,它的设计主要实现了两个目的:
- 分区的分配要尽可能的均匀;
- 分区的分配尽可能的与上次分配的保持相同。
如果这两个目的发生了冲突,优先实现第一个目的。
发生分区重分配后,对于同一个分区而言有可能之前的消费者和新指派的消费者不是同一个,对于之前消费者进行到一半的处理还要在新指派的消费者中再次处理一遍,这时就会浪费系统资源。而使用Sticky策略就可以让分配策略具备一定的“粘性”,尽可能地让前后两次分配相同,进而可以减少系统资源的损耗以及其它异常情况的发生。
offset的维护:**
- 生产者端:segment中有一个index

- 消费者端:有一个consumer topic这样的主题(去ZK中
get /kafka/brokers/topics/__consumer_offsets能看到)

若有收获,就点个赞吧
0 人点赞
