思维导图
导学
在之前的学习中,我们已经会建库了,也会建表了,还了解了一些相关的数据库知识,那么我们今天进入MySQL的重中之重,对数据的管理。
修改数据操作
针对于数据的操作,其实我们可以分为两种,一种是针对数据的查询,还有就是针对于数据的修改。
那么,在数据的修改中,又分为数据增加操作,数据删除操作和数据修改操作。
添加记录
语法:
INSERT INTO table_name[(field1, field2,...)] VALUES(value1, value2, value3)或INSERT tbl_name SET 字段名称=值,字段名称=值,...;
注意:
- field可以省略不写,但是如果不写,实际会对所有字段设置数据。而且后面VALUES中的顺序是要和你定义表时的顺序保持一致的;
- field如果写了,那么field里面的顺序要和values后面的数值保持一致。
在实际的开发中,一般都要给定字段进行插入,不建议省略fields的定义。
批量插入数据
语法:
INSERT tbl_name (字段名称,...) VALUES (值,...),
(值,...),
(值,...);
或者利用查询,将查询结果插入到表中
语法:
INSERT INTO table_name(field1, field2,...) SELECT field1, field2, ... FROM new_talbe
示例:
INSERT INTO s_v1(code, name, birthday)
SELECT code, name, birthday FROM s
修改记录
在程序开发中,修改数据一般是非常关键的操作,所以,只要是写更新数据的语句的时候,一定要想好条件。
语法:
UPDATE table_name SET field1=value1, field2=value2, ... WHERE condition
示例:
UPDATE s SET code='ss6',birthday='1990-10-10' WHERE name='zhangsan'
删除记录
同样的和修改数据操作一样,在删除数据的时候,一定要加上删除数据的条件。
删除记录 :
DELETE FROM tbl_name [WHERE条件]
-- DELETE 清空数据的时候不会重置AUTO_INCREMENT的值
补充:
TRUNCATE [TABLE] tbl_name;
-- 清空表中所有记录,会重置AUTO_INCREMENT的值
检索数据操作
完整语法:
SELECT select_expr,... FROM tb_name
[WHERE 条件]
[GROP BY{col_name|position} HAVING 二次筛选]
[ORDER BY {col_name|position|expr}[ASC|DESC]]
[LIMIT 限制结果采集的显示条数]
查询表中所有的记录
语法:
SELECT * FROM table_name [WHERE 条件]
示例:
select * from user
此处遍历出来的数据的顺序是创建表中字段的顺序。
指定字段信息查询
如果某张表的字段较多,但是在具体的某个场景中,只需要用到部分字段的信息,可以使用该查询。
语法:
SELECT field1, field2,... FROM table_name [WHERE 条件]
示例:
select id,user_name,password from user
起别名查询
语法:
给字段起别名:
SELECT 字段名称[AS] 别名名称,... FROM db_name.tb_name;
给数据表起别名:
SELECT 字段名称,... FROM tb_name AS 别名;
避免重复数据的查询
使用关键字:DISTINCT
例如要查询有在校生的班级编号,就可以使用 DISTINCT 关键字,查询 stu_info 表。 在使用 DISTINCT 查询时要注意:其效率较低的。
SELECT DISTINCT clazz FROM stu_info
查询时进行数学运算
数学运算的数据结果处理:+ - * / %
示例:
SELECT name, price AS '人民币', price/6 AS '美元' FROM t_menu
where筛选条件
在where后面,我们可以跟上所要设置的查询条件。那么如何描述查询条件呢?
- 带关系运算符和逻辑运算符的表达式;
- 带 BETWEEN AND 关键字的条件查询;
- 带 IS NULL 关键字的条件查询;
- 带 IN 关键字的条件查询;
- 带 LIKE 关键字的条件查询。
关系运算符和逻辑运算符
关系运算符:>、 >=、 <、 <=、=、<=>;
逻辑运算符:AND(&&)、OR(||)、NOT(!)
示例: ``` SELECT * FROM stu_info WHERE age >= 18 AND clazz = ‘C1’ AND code = ‘01’
对于null值的判断: select from user where user_name=null;(x) 不可以使用=进行null值的判断 select from user where user_name<=>null (ok)
<a name="748166f4"></a>
### BETWEEN ADN
> 一般用在对数值或者日期的区间判断条件中,而且是可以被替代的。
SELECT FROM stu_info WHERE age BETWEEN 16 AND 20 SELECT FROM stu_info WHERE age >= 16 AND age <=20 — 使用 NOT 取反 SELECT * FROM stu_info WHERE NOT (age >= 16 AND age <=20)
<a name="79bbf0b8"></a>
### IS NULL
> 判断数据结果集中非空元素,要注意的是:NULL 和 空字符串是两个概念,使用的查询条件不尽相同
SELECT FROM stu_info WHERE name IS NULL; SELECT FROM stu_info WHERE name = ‘’; — 判断空字符串
**使用非空判断是要注意**
SELECT * FROM stu_info WHERE name IS NOT NULL
<a name="eb5b9788"></a>
### IN
> 条件在某些离散的数据范围内
SELECT FROM stu_info WHERE clazz IN (‘C1’, ‘C2’); — 替代方案 SELECT FROM stu_info WHERE clazz = ‘C1’ OR clazz = ‘C2’
<a name="25c4c6f0"></a>
### LIKE
> 模糊查询:用的较多,一般用到的是全匹配`%搜索字%`,尾部匹配`搜索字%`
> 其他还有单个字匹配`_`和首部匹配`%搜索字`
SELECT FROM stuinfo WHERE name LIKE ‘李强’; SELECT FROM stu_info WHERE name LIKE ‘李%’; SELECT * FROM stu_info WHERE name LIKE ‘%李%’;
<a name="117ded9e"></a>
## 分组
GROUP BY分组:把值相同放到一个组中,最终查询出的结果只会显示组中一条记录。<br />示例:
SELECT id,username,age,sex FROM user
只会分别显示男 女2组里的各一条信息代表。<br />**分组拼接信息-group_concat()**
SELECT GROUP_CONTACT(username),age,sex,addr FROM user
<a name="d6257307"></a>
### 聚合函数
- count 总数
- sum 求和
- avg 平均值
- max 最大值
- min 最小值
示例:
SELECT COUNT(*) AS totalUsers, SUM(age) AS sum_age, MAX(age) AS max_age, MIN(age) AS min_age, AVG(age) AS avg_age, FROM user
**注意:**需要注意count(*)与count(字段)的区别。
<a name="320f5f3e"></a>
### HAVING对分组后的数据进行筛选
我们使用where对分组前的数据进行筛选,使用having对分组后的数据进行筛选。<br />示例:
select subject,avg(score) as avg_score from student group by subject having (avg_score < 60);
<a name="07974d40"></a>
## 排序
> 数据的排序方式:顺序 ASC、逆序 DESC。
> 在排序中是可以多字段排序的,即会有第一排序条件和第二、三...次排序条件
SELECT * FROM stu_info ORDER BY clazz ASC, code DESC
> 随机顺序`ORDER BY RAND();`
<a name="abe954b9"></a>
## 限制查询数量
使用 LIMIT 关键字限制查询的条数,后面跟两个参数,第一个参数是从第几条开始,第二个是一共显示多少条记录
SELECT * FROM stu_info ORDER BY clazz ASC, code DESC LIMIT 9, 3
— 显示 page 页,每页显示 num 条记录 — page = 2; num = 3; — x = (page - 1) * num — y = num
LIMIT同样也可以用于更新和删除操作,但是使用的时候只能添加一个参数
```sql
-- 更新user1表中的前3条记录,将age加5
UPDATE user1 SET age=age+5 LIMIT 3;
-- 将user1表中id字段降序排列,更新前三条记录,将age减10
UPDATE user1 SET age=age-10 ORDER BY id DESC LIMIT 3;
-- 删除user1表中前三条记录
DELETE FROM user1 LIMIT 3;
-- 删除user1表中id字段降序排列的前三条记录
DELETE FROM user1 ORDER BY id DESC LIMIT 3;
查询顺序解释
对于一个较完整的 SQL 语句执行的解释
SELECT
clazz,MAX(age) AS '最大年龄',
COUNT(*) AS '多少人'
FROM stu_info
WHERE id > 2
GROUP BY clazz HAVING count(*) > 1
ORDER BY MAX(age) DESC
执行顺序
- 筛选整个表找那个
id > 2的数据; - 把筛选出的记录按照
clazz字段进行分组; - 把分组完的结果,筛选出每组数据总数量 > 1的数据
count(*) > 1; - 按照分组后的字段进行排序
MAX(age) DESC; - 按照 SELECT 中要求显示的字段输出结果集。
高级查询
表之间的关系
- 一对多(多对一)
在多的一方加入一的一方的外键。 - 多对多
通过一个中间表将两个表之间建立关系。 - 一对一
在所谓的子表中加入所谓主表的外键,并加上唯一性约束。笛卡尔积查询-自然连接查询
自然连接查询是用的比较少的,同学们只需要了解即可。
示例:
要注意的是,如果不加条件,直接查询,会把两个表进行笛卡尔积的操作,查询出来的数据是有问题。SELECT t.id, t.name, t.age, ts.depName FROM teachar t, teach_species tsSELECT t.id, t.name, t.age, ts.depName FROM teachar t, teach_species ts where t.dep_id=ts.id内连接查询
内连接查询是可以使用自然连接查询替代的,但是效率方面,内连接会高
-- 内连接查询
SELECT s.`code`, s.`name`, c.`name` FROM student s
INNER JOIN clazz c ON s.clazz_id = c.id
内连接会查询出两个表中符合条件的交集部分
外连接查询
左外连接:
SELECT 字段名称,... FROM tb_name1 LEFT [OUTER] JOIN tb_name2 ON 条件
先显示左表中的全部记录,再去右表中查询符合条件的记录,不符合的以NULL代替
右外连接:
SELECT 字段名称,... FROM tb_name1 RIGHT [OUTER] JOIN tb_name2 ON 条件
先显示右表中的全部记录,再去左表中查询符合条件的记录,不符合的以NULL代替
关键字LEFT左边的那个表为主表,右边的表为从表;
关键字RIGHT右边的那个表为主表,左边的表为从表。
左外连接查询
以左表为主表,左表中的数据都会被显示出来,关联的右表中,如果存在符合条件的数据,那么会被关联出并显示,如果没有,则会显示 NULL。
-- 左外连接
SELECT s.`code`, s.`name`, c.`name` FROM student s
LEFT JOIN clazz c ON s.clazz_id = c.id
特殊查询
子查询
内层语句的查询结果可以作为外层语句的查询条件。
语法:
子查询(必须要放在括号里)
SELECT 字段名称 FROM tbl_name WHERE col_name =(SELECT col_name FROM tbl_name)
示例:
1、由IN引发的子查询
SELECT * FROM emp WHERE depId IN (SELECT id FROM dep);
2、由NOT IN 引发的子查询
SELECT * FROM emp WHERE depId NOT IN (SELECT id FROM dep);
3、由比较运算符引发的子查询
SELECT id,username,score,FROM stu WHERE score>=(SELECT score FROM level WHERE id=1);
4、由EXISTS引发的子查询
EXISTS后面的SELECT语句返回一个布尔类型,若后面的值不存在前面的语句不执行,若存在,则执行(EXISTS 后面的语句返回的BOOLEAN值,是是否执行前面语句的条件)
SELECT * FROM emp WHERE EXISTS (SELECT depName FROM dep WHERE id=10);
带有 ANY SOME ALL的子查询
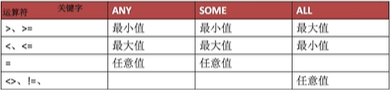
ANY 和 SOME 理解为与 或 | 相似
例如:表达式: A > SOME(1,2,3,4,5,6)
只要A的值大于SOME括号中的任意一个值, 整个表达式返回TURE, 否则返回FALSE
ALL 则理解为与 并且 & 相似
例如:表达式: A > ALL(1,2,3,4,5,6)
只有A的值大于ALL括号中的所有值, 整个表达式返回TURE, 否则返回FALSE
示例:
带有ANY SOME ALL 关键字查询
SELECT * FROM stu
WHERE score>=ANY(SELECT score FROM level);
ANY跟SOME意义相同
SELECT * FROM stu
WHERE score>=SOME(SELECT score FROM level);
SELECT * FROM stu
WHERE score>=ALL(SELECT score FROM level);
联合查询
使用的比较少。
通过多个 select 语句查询,将查询的结果合并在一起,并返回一个新的结果集。 union 关键字用于合并数据,默认选择不同的数据,若允许重复的数据,可以使用 union all。 请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。
UNION:
SELECT 字段名称,... FROM tb_name1 UNION SELECT 字段名称,... FROM tb_name2;会去掉两个表中的重复项
UNION ALL:
SELECT 字段名称,... FROM tb_name1 UNION ALL SELECT 字段名称,... FROM tb_name2;直接合并两个表中的记录

若有收获,就点个赞吧
0 人点赞
